 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoupled Entity Representation Learning for Pinterest Ads Ranking
Sep 04, 2025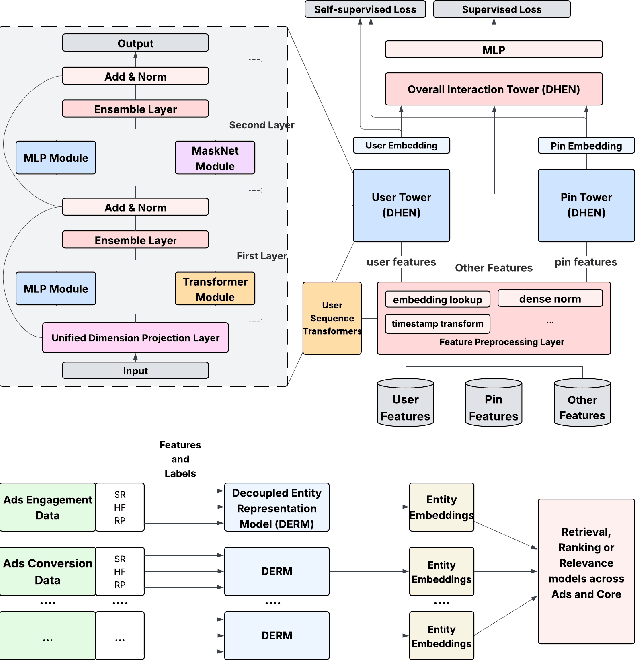



In this paper, we introduce a novel framework following an upstream-downstream paradigm to construct user and item (Pin) embeddings from diverse data sources, which are essential for Pinterest to deliver personalized Pins and ads effectively. Our upstream models are trained on extensive data sources featuring varied signals, utilizing complex architectures to capture intricate relationships between users and Pins on Pinterest. To ensure scalability of the upstream models, entity embeddings are learned, and regularly refreshed, rather than real-time computation, allowing for asynchronous interaction between the upstream and downstream models. These embeddings are then integrated as input features in numerous downstream tasks, including ad retrieval and ranking models for CTR and CVR predictions. We demonstrate that our framework achieves notable performance improvements in both offline and online settings across various downstream tasks. This framework has been deployed in Pinterest's production ad ranking systems, resulting in significant gains in online metrics.
On the Practice of Deep Hierarchical Ensemble Network for Ad Conversion Rate Prediction
Apr 10, 2025The predictions of click through rate (CTR) and conversion rate (CVR) play a crucial role in the success of ad-recommendation systems. A Deep Hierarchical Ensemble Network (DHEN) has been proposed to integrate multiple feature crossing modules and has achieved great success in CTR prediction. However, its performance for CVR prediction is unclear in the conversion ads setting, where an ad bids for the probability of a user's off-site actions on a third party website or app, including purchase, add to cart, sign up, etc. A few challenges in DHEN: 1) What feature-crossing modules (MLP, DCN, Transformer, to name a few) should be included in DHEN? 2) How deep and wide should DHEN be to achieve the best trade-off between efficiency and efficacy? 3) What hyper-parameters to choose in each feature-crossing module? Orthogonal to the model architecture, the input personalization features also significantly impact model performance with a high degree of freedom. In this paper, we attack this problem and present our contributions biased to the applied data science side, including: First, we propose a multitask learning framework with DHEN as the single backbone model architecture to predict all CVR tasks, with a detailed study on how to make DHEN work effectively in practice; Second, we build both on-site real-time user behavior sequences and off-site conversion event sequences for CVR prediction purposes, and conduct ablation study on its importance; Last but not least, we propose a self-supervised auxiliary loss to predict future actions in the input sequence, to help resolve the label sparseness issue in CVR prediction. Our method achieves state-of-the-art performance compared to previous single feature crossing modules with pre-trained user personalization features.
Improving Query Safety at Pinterest
Jun 23, 2020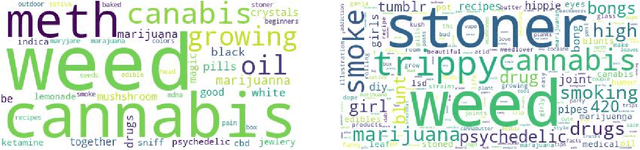


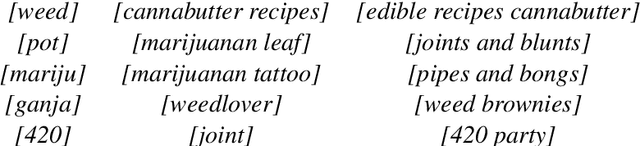
Query recommendations in search engines is a double edged sword, with undeniable benefits but potential of harm. Identifying unsafe queries is necessary to protect users from inappropriate query suggestions. However, identifying these is non-trivial because of the linguistic diversity resulting from large vocabularies, social-group-specific slang and typos, and because the inappropriateness of a term depends on the context. Here we formulate the problem as query-set expansion, where we are given a small and potentially biased seed set and the aim is to identify a diverse set of semantically related queries. We present PinSets, a system for query-set expansion, which applies a simple yet powerful mechanism to search user sessions, expanding a tiny seed set into thousands of related queries at nearly perfect precision, deep into the tail, along with explanations that are easy to interpret. PinSets owes its high quality expansion to using a hybrid of textual and behavioral techniques (i.e., treating queries both as compositional and as black boxes). Experiments show that, for the domain of drugs-related queries, PinSets expands 20 seed queries into 15,670 positive training examples at over 99\% precision. The generated expansions have diverse vocabulary and correctly handles words with ambiguous safety. PinSets decreased unsafe query suggestions at Pinterest by 90\%.