 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Evolution of Embedding Table Optimization and Multi-Epoch Training in Pinterest Ads Conversion
May 08, 2025Deep learning for conversion prediction has found widespread applications in online advertising. These models have become more complex as they are trained to jointly predict multiple objectives such as click, add-to-cart, checkout and other conversion types. Additionally, the capacity and performance of these models can often be increased with the use of embedding tables that encode high cardinality categorical features such as advertiser, user, campaign, and product identifiers (IDs). These embedding tables can be pre-trained, but also learned end-to-end jointly with the model to directly optimize the model objectives. Training these large tables is challenging due to: gradient sparsity, the high cardinality of the categorical features, the non-uniform distribution of IDs and the very high label sparsity. These issues make training prone to both slow convergence and overfitting after the first epoch. Previous works addressed the multi-epoch overfitting issue by using: stronger feature hashing to reduce cardinality, filtering of low frequency IDs, regularization of the embedding tables, re-initialization of the embedding tables after each epoch, etc. Some of these techniques reduce overfitting at the expense of reduced model performance if used too aggressively. In this paper, we share key learnings from the development of embedding table optimization and multi-epoch training in Pinterest Ads Conversion models. We showcase how our Sparse Optimizer speeds up convergence, and how multi-epoch overfitting varies in severity between different objectives in a multi-task model depending on label sparsity. We propose a new approach to deal with multi-epoch overfitting: the use of a frequency-adaptive learning rate on the embedding tables and compare it to embedding re-initialization. We evaluate both methods offline using an industrial large-scale production dataset.
On the Practice of Deep Hierarchical Ensemble Network for Ad Conversion Rate Prediction
Apr 10, 2025The predictions of click through rate (CTR) and conversion rate (CVR) play a crucial role in the success of ad-recommendation systems. A Deep Hierarchical Ensemble Network (DHEN) has been proposed to integrate multiple feature crossing modules and has achieved great success in CTR prediction. However, its performance for CVR prediction is unclear in the conversion ads setting, where an ad bids for the probability of a user's off-site actions on a third party website or app, including purchase, add to cart, sign up, etc. A few challenges in DHEN: 1) What feature-crossing modules (MLP, DCN, Transformer, to name a few) should be included in DHEN? 2) How deep and wide should DHEN be to achieve the best trade-off between efficiency and efficacy? 3) What hyper-parameters to choose in each feature-crossing module? Orthogonal to the model architecture, the input personalization features also significantly impact model performance with a high degree of freedom. In this paper, we attack this problem and present our contributions biased to the applied data science side, including: First, we propose a multitask learning framework with DHEN as the single backbone model architecture to predict all CVR tasks, with a detailed study on how to make DHEN work effectively in practice; Second, we build both on-site real-time user behavior sequences and off-site conversion event sequences for CVR prediction purposes, and conduct ablation study on its importance; Last but not least, we propose a self-supervised auxiliary loss to predict future actions in the input sequence, to help resolve the label sparseness issue in CVR prediction. Our method achieves state-of-the-art performance compared to previous single feature crossing modules with pre-trained user personalization features.
Short Video-based Advertisements Evaluation System: Self-Organizing Learning Approach
Oct 23, 2020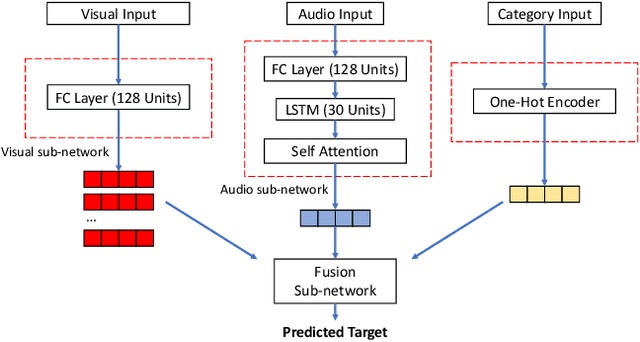
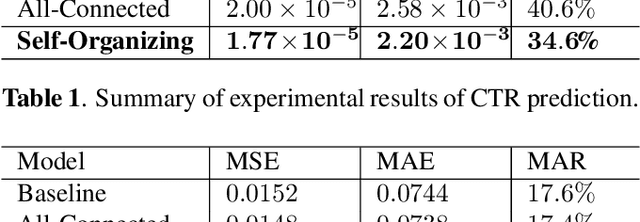
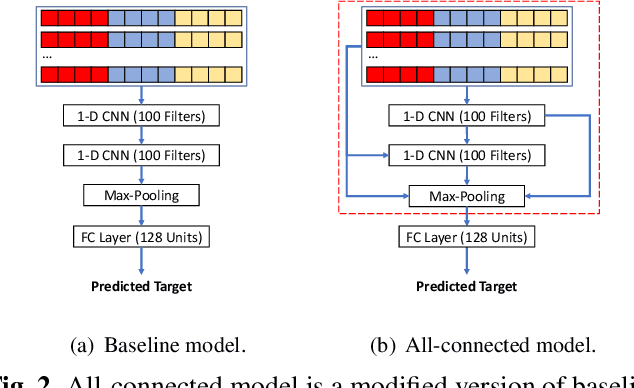
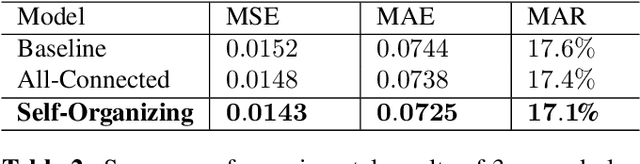
With the rising of short video apps, such as TikTok, Snapchat and Kwai, advertisement in short-term user-generated videos (UGVs) has become a trending form of advertising. Prediction of user behavior without specific user profile is required by advertisers, as they expect to acquire advertisement performance in advance in the scenario of cold start. Current recommender system do not take raw videos as input; additionally, most previous work of Multi-Modal Machine Learning may not deal with unconstrained videos like UGVs. In this paper, we proposed a novel end-to-end self-organizing framework for user behavior prediction. Our model is able to learn the optimal topology of neural network architecture, as well as optimal weights, through training data. We evaluate our proposed method on our in-house dataset. The experimental results reveal that our model achieves the best performance in all our experiments.
Ensemble Chinese End-to-End Spoken Language Understanding for Abnormal Event Detection from audio stream
Oct 19, 2020
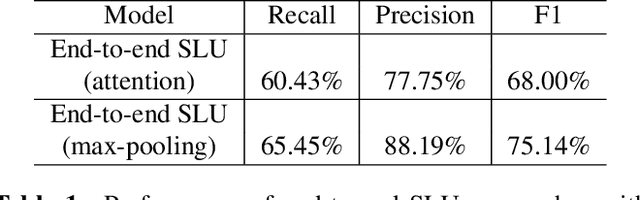

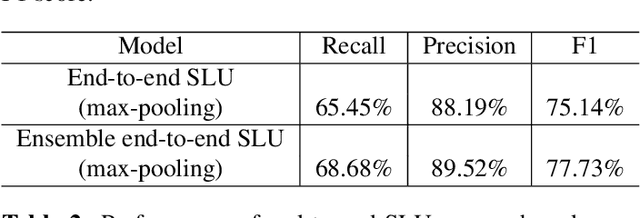
Conventional spoken language understanding (SLU) consist of two stages, the first stage maps speech to text by automatic speech recognition (ASR), and the second stage maps text to intent by natural language understanding (NLU). End-to-end SLU maps speech directly to intent through a single deep learning model. Previous end-to-end SLU models are primarily used for English environment due to lacking large scale SLU dataset in Chines, and use only one ASR model to extract features from speech. With the help of Kuaishou technology, a large scale SLU dataset in Chinese is collected to detect abnormal event in their live audio stream. Based on this dataset, this paper proposed a ensemble end-to-end SLU model used for Chinese environment. This ensemble SLU models extracted hierarchies features using multiple pre-trained ASR models, leading to better representation of phoneme level and word level information. This proposed approached achieve 9.7% increase of accuracy compared to previous end-to-end SLU model.
Themes Inferred Audio-visual Correspondence Learning
Sep 14, 2020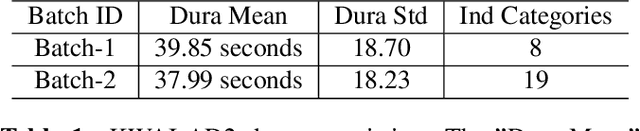
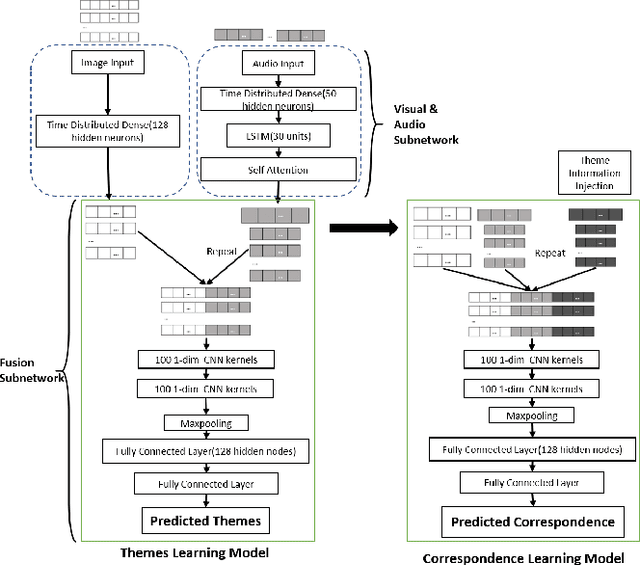
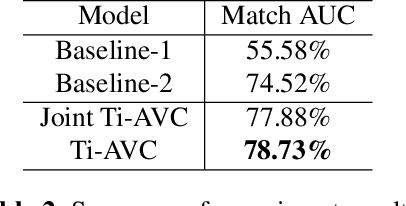
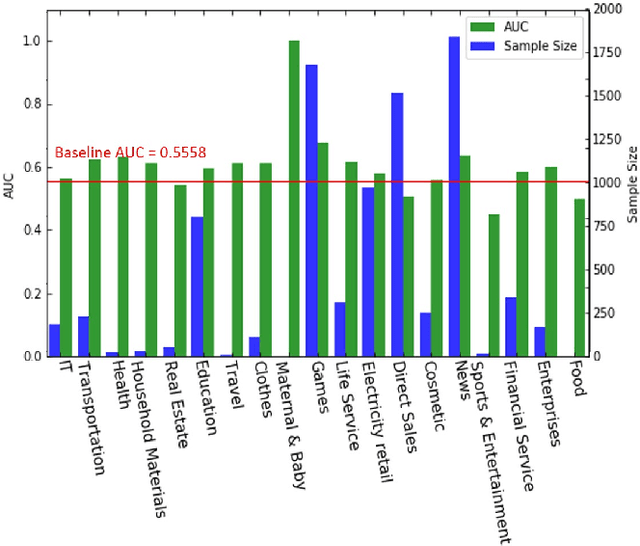
The applications of short-termuser generated video(UGV),such as snapchat, youtube short-term videos, booms recently,raising lots of multimodal machine learning tasks. Amongthem, learning the correspondence between audio and vi-sual information from videos is a challenging one. Mostprevious work of theaudio-visual correspondence(AVC)learning only investigated on constrained videos or simplesettings, which may not fit the application of UGV. In thispaper, we proposed new principles for AVC and introduced anew framework to set sight on the themes of videos to facili-tate AVC learning. We also released the KWAI-AD-AudViscorpus which contained 85432 short advertisement videos(around 913 hours) made by users. We evaluated our pro-posed approach on this corpus and it was able to outperformthe baseline by 23.15% absolute differenc