 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Object Hallucinations in LVLMs via Attention Imbalance Rectification
Mar 25, 2026Object hallucination in Large Vision-Language Models (LVLMs) severely compromises their reliability in real-world applications, posing a critical barrier to their deployment in high-stakes scenarios such as autonomous driving and medical image analysis. Through systematic empirical investigation, we identify that the imbalanced attention allocation, both across modalities (i.e., vision and language) and within modalities (among individual tokens), exhibits a strong causal correlation with the occurrence of object hallucination. Leveraging this insight, we introduce a novel concept termed attention imbalance, which not only quantifies the degree of attention disparity but also visually delineates the underlying patterns (e.g., over-attentiveness to irrelevant language tokens or under-attentiveness to discriminative visual features) that drive object hallucination. To mitigate object hallucination, we further propose Attention Imbalance Rectification (AIR), a lightweight decoding-time intervention method that reallocates attention weights and adjusts attention distributions to rectify modality-wise and token-wise imbalances. Extensive evaluations on four mainstream LVLMs and three benchmarks (CHAIR, POPE, and MM-Vet) with seven baselines demonstrate that AIR consistently reduces object hallucination rates, achieving up to a 35.1% reduction compared to the baselines, while improving up to 15.9% of LVLMs' general capability across diverse vision-language tasks.
FID-Net: A Feature-Enhanced Deep Learning Network for Forest Infestation Detection
Dec 15, 2025Forest pests threaten ecosystem stability, requiring efficient monitoring. To overcome the limitations of traditional methods in large-scale, fine-grained detection, this study focuses on accurately identifying infected trees and analyzing infestation patterns. We propose FID-Net, a deep learning model that detects pest-affected trees from UAV visible-light imagery and enables infestation analysis via three spatial metrics. Based on YOLOv8n, FID-Net introduces a lightweight Feature Enhancement Module (FEM) to extract disease-sensitive cues, an Adaptive Multi-scale Feature Fusion Module (AMFM) to align and fuse dual-branch features (RGB and FEM-enhanced), and an Efficient Channel Attention (ECA) mechanism to enhance discriminative information efficiently. From detection results, we construct a pest situation analysis framework using: (1) Kernel Density Estimation to locate infection hotspots; (2) neighborhood evaluation to assess healthy trees' infection risk; (3) DBSCAN clustering to identify high-density healthy clusters as priority protection zones. Experiments on UAV imagery from 32 forest plots in eastern Tianshan, China, show that FID-Net achieves 86.10% precision, 75.44% recall, 82.29% mAP@0.5, and 64.30% mAP@0.5:0.95, outperforming mainstream YOLO models. Analysis confirms infected trees exhibit clear clustering, supporting targeted forest protection. FID-Net enables accurate tree health discrimination and, combined with spatial metrics, provides reliable data for intelligent pest monitoring, early warning, and precise management.
SliceSemOcc: Vertical Slice Based Multimodal 3D Semantic Occupancy Representation
Sep 04, 2025Driven by autonomous driving's demands for precise 3D perception, 3D semantic occupancy prediction has become a pivotal research topic. Unlike bird's-eye-view (BEV) methods, which restrict scene representation to a 2D plane, occupancy prediction leverages a complete 3D voxel grid to model spatial structures in all dimensions, thereby capturing semantic variations along the vertical axis. However, most existing approaches overlook height-axis information when processing voxel features. And conventional SENet-style channel attention assigns uniform weight across all height layers, limiting their ability to emphasize features at different heights. To address these limitations, we propose SliceSemOcc, a novel vertical slice based multimodal framework for 3D semantic occupancy representation. Specifically, we extract voxel features along the height-axis using both global and local vertical slices. Then, a global local fusion module adaptively reconciles fine-grained spatial details with holistic contextual information. Furthermore, we propose the SEAttention3D module, which preserves height-wise resolution through average pooling and assigns dynamic channel attention weights to each height layer. Extensive experiments on nuScenes-SurroundOcc and nuScenes-OpenOccupancy datasets verify that our method significantly enhances mean IoU, achieving especially pronounced gains on most small-object categories. Detailed ablation studies further validate the effectiveness of the proposed SliceSemOcc framework.
Decoupled Entity Representation Learning for Pinterest Ads Ranking
Sep 04, 2025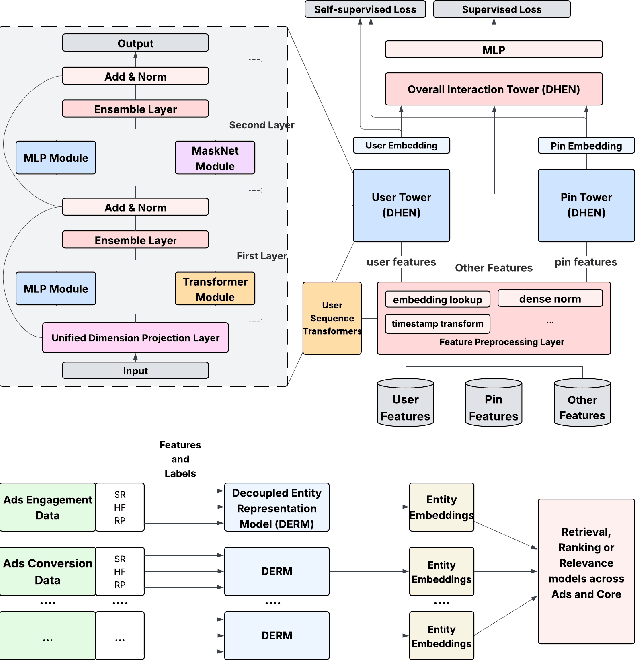



In this paper, we introduce a novel framework following an upstream-downstream paradigm to construct user and item (Pin) embeddings from diverse data sources, which are essential for Pinterest to deliver personalized Pins and ads effectively. Our upstream models are trained on extensive data sources featuring varied signals, utilizing complex architectures to capture intricate relationships between users and Pins on Pinterest. To ensure scalability of the upstream models, entity embeddings are learned, and regularly refreshed, rather than real-time computation, allowing for asynchronous interaction between the upstream and downstream models. These embeddings are then integrated as input features in numerous downstream tasks, including ad retrieval and ranking models for CTR and CVR predictions. We demonstrate that our framework achieves notable performance improvements in both offline and online settings across various downstream tasks. This framework has been deployed in Pinterest's production ad ranking systems, resulting in significant gains in online metrics.
SLENet: A Guidance-Enhanced Network for Underwater Camouflaged Object Detection
Sep 04, 2025
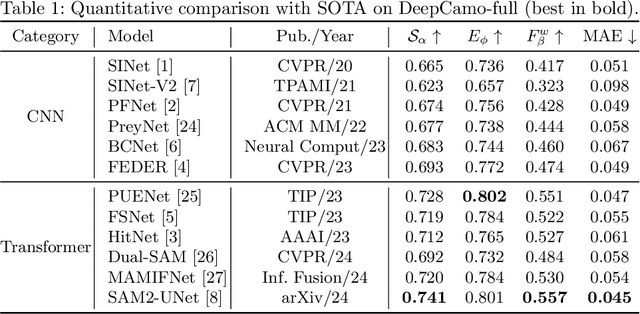

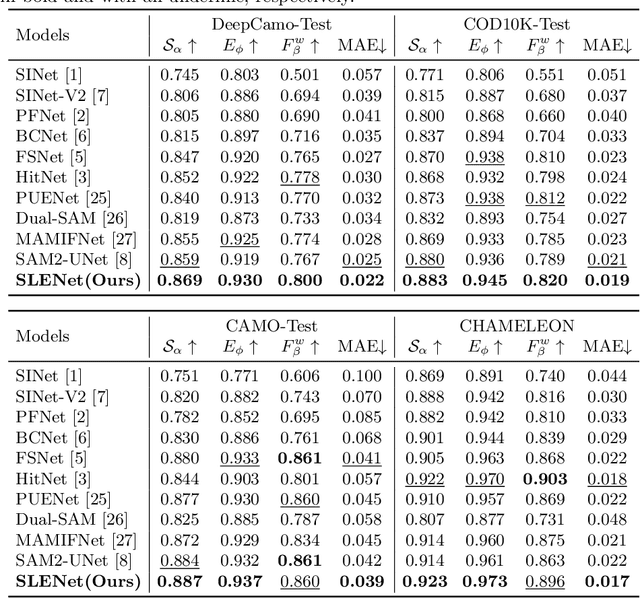
Underwater Camouflaged Object Detection (UCOD) aims to identify objects that blend seamlessly into underwater environments. This task is critically important to marine ecology. However, it remains largely underexplored and accurate identification is severely hindered by optical distortions, water turbidity, and the complex traits of marine organisms. To address these challenges, we introduce the UCOD task and present DeepCamo, a benchmark dataset designed for this domain. We also propose Semantic Localization and Enhancement Network (SLENet), a novel framework for UCOD. We first benchmark state-of-the-art COD models on DeepCamo to reveal key issues, upon which SLENet is built. In particular, we incorporate Gamma-Asymmetric Enhancement (GAE) module and a Localization Guidance Branch (LGB) to enhance multi-scale feature representation while generating a location map enriched with global semantic information. This map guides the Multi-Scale Supervised Decoder (MSSD) to produce more accurate predictions. Experiments on our DeepCamo dataset and three benchmark COD datasets confirm SLENet's superior performance over SOTA methods, and underscore its high generality for the broader COD task.
SynDec: A Synthesize-then-Decode Approach for Arbitrary Textual Style Transfer via Large Language Models
May 19, 2025Large Language Models (LLMs) are emerging as dominant forces for textual style transfer. However, for arbitrary style transfer, LLMs face two key challenges: (1) considerable reliance on manually-constructed prompts and (2) rigid stylistic biases inherent in LLMs. In this paper, we propose a novel Synthesize-then-Decode (SynDec) approach, which automatically synthesizes high-quality prompts and amplifies their roles during decoding process. Specifically, our approach synthesizes prompts by selecting representative few-shot samples, conducting a four-dimensional style analysis, and reranking the candidates. At LLM decoding stage, the TST effect is amplified by maximizing the contrast in output probabilities between scenarios with and without the synthesized prompt, as well as between prompts and negative samples. We conduct extensive experiments and the results show that SynDec outperforms existing state-of-the-art LLM-based methods on five out of six benchmarks (e.g., achieving up to a 9\% increase in accuracy for modern-to-Elizabethan English transfer). Detailed ablation studies further validate the effectiveness of SynDec.
Exploring Pose-Guided Imitation Learning for Robotic Precise Insertion
May 14, 2025Recent studies have proved that imitation learning shows strong potential in the field of robotic manipulation. However, existing methods still struggle with precision manipulation task and rely on inefficient image/point cloud observations. In this paper, we explore to introduce SE(3) object pose into imitation learning and propose the pose-guided efficient imitation learning methods for robotic precise insertion task. First, we propose a precise insertion diffusion policy which utilizes the relative SE(3) pose as the observation-action pair. The policy models the source object SE(3) pose trajectory relative to the target object. Second, we explore to introduce the RGBD data to the pose-guided diffusion policy. Specifically, we design a goal-conditioned RGBD encoder to capture the discrepancy between the current state and the goal state. In addition, a pose-guided residual gated fusion method is proposed, which takes pose features as the backbone, and the RGBD features selectively compensate for pose feature deficiencies through an adaptive gating mechanism. Our methods are evaluated on 6 robotic precise insertion tasks, demonstrating competitive performance with only 7-10 demonstrations. Experiments demonstrate that the proposed methods can successfully complete precision insertion tasks with a clearance of about 0.01 mm. Experimental results highlight its superior efficiency and generalization capability compared to existing baselines. Code will be available at https://github.com/sunhan1997/PoseInsert.
The Evolution of Embedding Table Optimization and Multi-Epoch Training in Pinterest Ads Conversion
May 08, 2025



Deep learning for conversion prediction has found widespread applications in online advertising. These models have become more complex as they are trained to jointly predict multiple objectives such as click, add-to-cart, checkout and other conversion types. Additionally, the capacity and performance of these models can often be increased with the use of embedding tables that encode high cardinality categorical features such as advertiser, user, campaign, and product identifiers (IDs). These embedding tables can be pre-trained, but also learned end-to-end jointly with the model to directly optimize the model objectives. Training these large tables is challenging due to: gradient sparsity, the high cardinality of the categorical features, the non-uniform distribution of IDs and the very high label sparsity. These issues make training prone to both slow convergence and overfitting after the first epoch. Previous works addressed the multi-epoch overfitting issue by using: stronger feature hashing to reduce cardinality, filtering of low frequency IDs, regularization of the embedding tables, re-initialization of the embedding tables after each epoch, etc. Some of these techniques reduce overfitting at the expense of reduced model performance if used too aggressively. In this paper, we share key learnings from the development of embedding table optimization and multi-epoch training in Pinterest Ads Conversion models. We showcase how our Sparse Optimizer speeds up convergence, and how multi-epoch overfitting varies in severity between different objectives in a multi-task model depending on label sparsity. We propose a new approach to deal with multi-epoch overfitting: the use of a frequency-adaptive learning rate on the embedding tables and compare it to embedding re-initialization. We evaluate both methods offline using an industrial large-scale production dataset.
Energy-Based Pseudo-Label Refining for Source-free Domain Adaptation
Apr 23, 2025
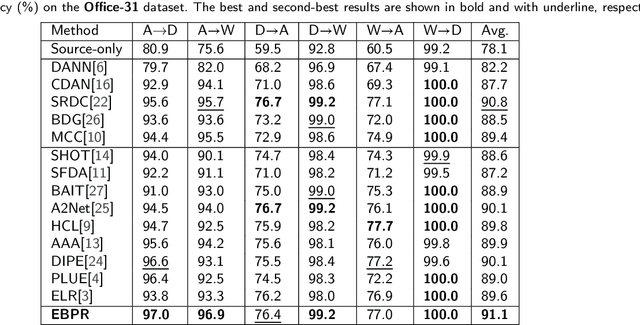


Source-free domain adaptation (SFDA), which involves adapting models without access to source data, is both demanding and challenging. Existing SFDA techniques typically rely on pseudo-labels generated from confidence levels, leading to negative transfer due to significant noise. To tackle this problem, Energy-Based Pseudo-Label Refining (EBPR) is proposed for SFDA. Pseudo-labels are created for all sample clusters according to their energy scores. Global and class energy thresholds are computed to selectively filter pseudo-labels. Furthermore, a contrastive learning strategy is introduced to filter difficult samples, aligning them with their augmented versions to learn more discriminative features. Our method is validated on the Office-31, Office-Home, and VisDA-C datasets, consistently finding that our model outperformed state-of-the-art methods.
On the Practice of Deep Hierarchical Ensemble Network for Ad Conversion Rate Prediction
Apr 10, 2025The predictions of click through rate (CTR) and conversion rate (CVR) play a crucial role in the success of ad-recommendation systems. A Deep Hierarchical Ensemble Network (DHEN) has been proposed to integrate multiple feature crossing modules and has achieved great success in CTR prediction. However, its performance for CVR prediction is unclear in the conversion ads setting, where an ad bids for the probability of a user's off-site actions on a third party website or app, including purchase, add to cart, sign up, etc. A few challenges in DHEN: 1) What feature-crossing modules (MLP, DCN, Transformer, to name a few) should be included in DHEN? 2) How deep and wide should DHEN be to achieve the best trade-off between efficiency and efficacy? 3) What hyper-parameters to choose in each feature-crossing module? Orthogonal to the model architecture, the input personalization features also significantly impact model performance with a high degree of freedom. In this paper, we attack this problem and present our contributions biased to the applied data science side, including: First, we propose a multitask learning framework with DHEN as the single backbone model architecture to predict all CVR tasks, with a detailed study on how to make DHEN work effectively in practice; Second, we build both on-site real-time user behavior sequences and off-site conversion event sequences for CVR prediction purposes, and conduct ablation study on its importance; Last but not least, we propose a self-supervised auxiliary loss to predict future actions in the input sequence, to help resolve the label sparseness issue in CVR prediction. Our method achieves state-of-the-art performance compared to previous single feature crossing modules with pre-trained user personalization features.