 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSliceSemOcc: Vertical Slice Based Multimodal 3D Semantic Occupancy Representation
Sep 04, 2025Driven by autonomous driving's demands for precise 3D perception, 3D semantic occupancy prediction has become a pivotal research topic. Unlike bird's-eye-view (BEV) methods, which restrict scene representation to a 2D plane, occupancy prediction leverages a complete 3D voxel grid to model spatial structures in all dimensions, thereby capturing semantic variations along the vertical axis. However, most existing approaches overlook height-axis information when processing voxel features. And conventional SENet-style channel attention assigns uniform weight across all height layers, limiting their ability to emphasize features at different heights. To address these limitations, we propose SliceSemOcc, a novel vertical slice based multimodal framework for 3D semantic occupancy representation. Specifically, we extract voxel features along the height-axis using both global and local vertical slices. Then, a global local fusion module adaptively reconciles fine-grained spatial details with holistic contextual information. Furthermore, we propose the SEAttention3D module, which preserves height-wise resolution through average pooling and assigns dynamic channel attention weights to each height layer. Extensive experiments on nuScenes-SurroundOcc and nuScenes-OpenOccupancy datasets verify that our method significantly enhances mean IoU, achieving especially pronounced gains on most small-object categories. Detailed ablation studies further validate the effectiveness of the proposed SliceSemOcc framework.
SLENet: A Guidance-Enhanced Network for Underwater Camouflaged Object Detection
Sep 04, 2025
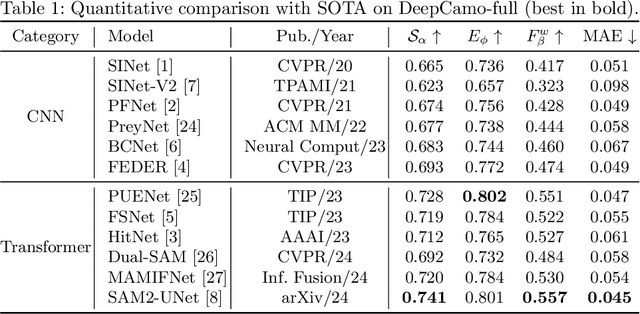

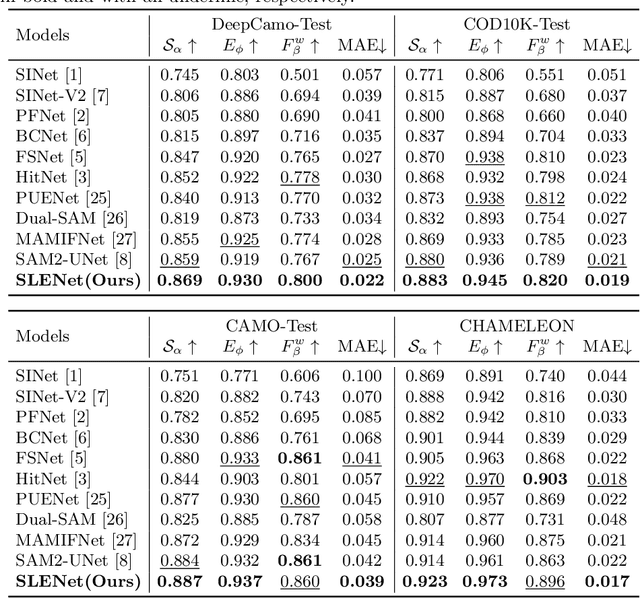
Underwater Camouflaged Object Detection (UCOD) aims to identify objects that blend seamlessly into underwater environments. This task is critically important to marine ecology. However, it remains largely underexplored and accurate identification is severely hindered by optical distortions, water turbidity, and the complex traits of marine organisms. To address these challenges, we introduce the UCOD task and present DeepCamo, a benchmark dataset designed for this domain. We also propose Semantic Localization and Enhancement Network (SLENet), a novel framework for UCOD. We first benchmark state-of-the-art COD models on DeepCamo to reveal key issues, upon which SLENet is built. In particular, we incorporate Gamma-Asymmetric Enhancement (GAE) module and a Localization Guidance Branch (LGB) to enhance multi-scale feature representation while generating a location map enriched with global semantic information. This map guides the Multi-Scale Supervised Decoder (MSSD) to produce more accurate predictions. Experiments on our DeepCamo dataset and three benchmark COD datasets confirm SLENet's superior performance over SOTA methods, and underscore its high generality for the broader COD task.
Energy-Based Pseudo-Label Refining for Source-free Domain Adaptation
Apr 23, 2025
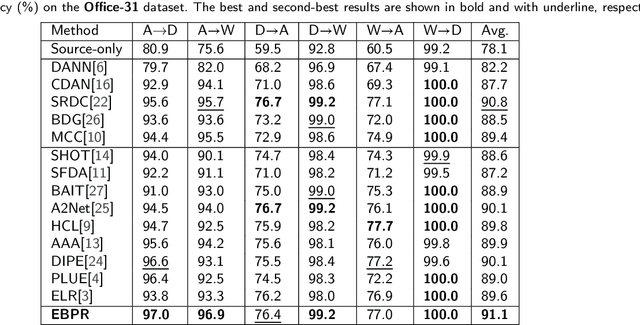


Source-free domain adaptation (SFDA), which involves adapting models without access to source data, is both demanding and challenging. Existing SFDA techniques typically rely on pseudo-labels generated from confidence levels, leading to negative transfer due to significant noise. To tackle this problem, Energy-Based Pseudo-Label Refining (EBPR) is proposed for SFDA. Pseudo-labels are created for all sample clusters according to their energy scores. Global and class energy thresholds are computed to selectively filter pseudo-labels. Furthermore, a contrastive learning strategy is introduced to filter difficult samples, aligning them with their augmented versions to learn more discriminative features. Our method is validated on the Office-31, Office-Home, and VisDA-C datasets, consistently finding that our model outperformed state-of-the-art methods.
SPARNet: Continual Test-Time Adaptation via Sample Partitioning Strategy and Anti-Forgetting Regularization
Jan 01, 2025



Test-time Adaptation (TTA) aims to improve model performance when the model encounters domain changes after deployment. The standard TTA mainly considers the case where the target domain is static, while the continual TTA needs to undergo a sequence of domain changes. This encounters a significant challenge as the model needs to adapt for the long-term and is unaware of when the domain changes occur. The quality of pseudo-labels is hard to guarantee. Noisy pseudo-labels produced by simple self-training methods can cause error accumulation and catastrophic forgetting. In this work, we propose a new framework named SPARNet which consists of two parts, sample partitioning strategy and anti-forgetting regularization. The sample partition strategy divides samples into two groups, namely reliable samples and unreliable samples. According to the characteristics of each group of samples, we choose different strategies to deal with different groups of samples. This ensures that reliable samples contribute more to the model. At the same time, the negative impacts of unreliable samples are eliminated by the mean teacher's consistency learning. Finally, we introduce a regularization term to alleviate the catastrophic forgetting problem, which can limit important parameters from excessive changes. This term enables long-term adaptation of parameters in the network. The effectiveness of our method is demonstrated in continual TTA scenario by conducting a large number of experiments on CIFAR10-C, CIFAR100-C and ImageNet-C.
B2Net: Camouflaged Object Detection via Boundary Aware and Boundary Fusion
Dec 31, 2024Camouflaged object detection (COD) aims to identify objects in images that are well hidden in the environment due to their high similarity to the background in terms of texture and color. However, existing most boundary-guided camouflage object detection algorithms tend to generate object boundaries early in the network, and inaccurate edge priors often introduce noises in object detection. Address on this issue, we propose a novel network named B2Net aiming to enhance the accuracy of obtained boundaries by reusing boundary-aware modules at different stages of the network. Specifically, we present a Residual Feature Enhanced Module (RFEM) with the goal of integrating more discriminative feature representations to enhance detection accuracy and reliability. After that, the Boundary Aware Module (BAM) is introduced to explore edge cues twice by integrating spatial information from low-level features and semantic information from high-level features. Finally, we design the Cross-scale Boundary Fusion Module(CBFM) that integrate information across different scales in a top-down manner, merging boundary features with object features to obtain a comprehensive feature representation incorporating boundary information. Extensive experimental results on three challenging benchmark datasets demonstrate that our proposed method B2Net outperforms 15 state-of-art methods under widely used evaluation metrics. Code will be made publicly available.
DecoratingFusion: A LiDAR-Camera Fusion Network with the Combination of Point-level and Feature-level Fusion
Dec 31, 2024Lidars and cameras play essential roles in autonomous driving, offering complementary information for 3D detection. The state-of-the-art fusion methods integrate them at the feature level, but they mostly rely on the learned soft association between point clouds and images, which lacks interpretability and neglects the hard association between them. In this paper, we combine feature-level fusion with point-level fusion, using hard association established by the calibration matrices to guide the generation of object queries. Specifically, in the early fusion stage, we use the 2D CNN features of images to decorate the point cloud data, and employ two independent sparse convolutions to extract the decorated point cloud features. In the mid-level fusion stage, we initialize the queries with a center heatmap and embed the predicted class labels as auxiliary information into the queries, making the initial positions closer to the actual centers of the targets. Extensive experiments conducted on two popular datasets, i.e. KITTI, Waymo, demonstrate the superiority of DecoratingFusion.
SIDE: Self-supervised Intermediate Domain Exploration for Source-free Domain Adaptation
Oct 13, 2023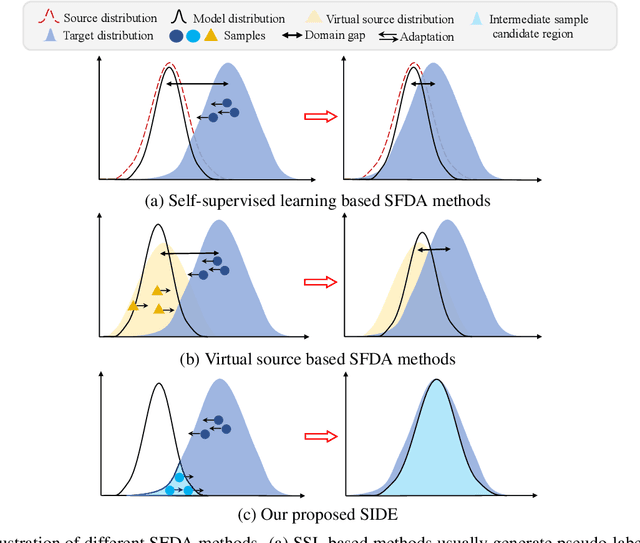
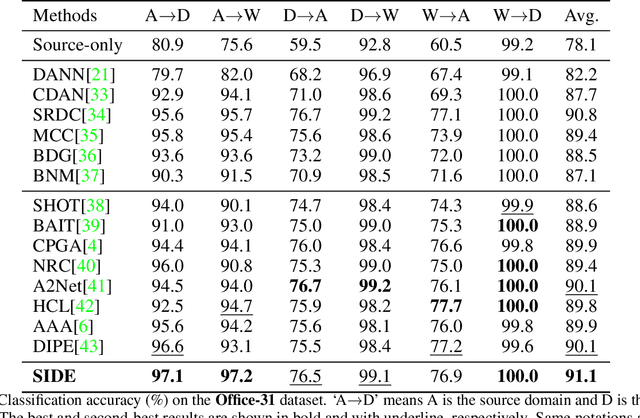
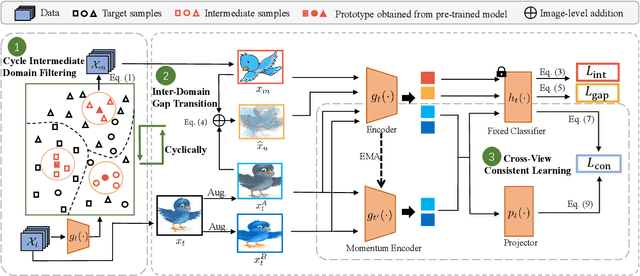
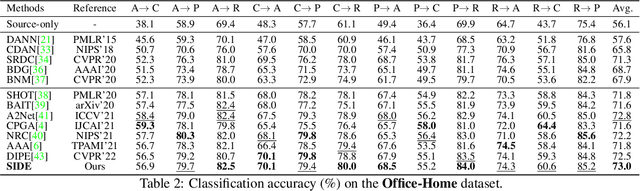
Domain adaptation aims to alleviate the domain shift when transferring the knowledge learned from the source domain to the target domain. Due to privacy issues, source-free domain adaptation (SFDA), where source data is unavailable during adaptation, has recently become very demanding yet challenging. Existing SFDA methods focus on either self-supervised learning of target samples or reconstruction of virtual source data. The former overlooks the transferable knowledge in the source model, whilst the latter introduces even more uncertainty. To address the above issues, this paper proposes self-supervised intermediate domain exploration (SIDE) that effectively bridges the domain gap with an intermediate domain, where samples are cyclically filtered out in a self-supervised fashion. First, we propose cycle intermediate domain filtering (CIDF) to cyclically select intermediate samples with similar distributions over source and target domains. Second, with the aid of those intermediate samples, an inter-domain gap transition (IDGT) module is developed to mitigate possible distribution mismatches between the source and target data. Finally, we introduce cross-view consistency learning (CVCL) to maintain the intrinsic class discriminability whilst adapting the model to the target domain. Extensive experiments on three popular benchmarks, i.e. Office-31, Office-Home and VisDA-C, show that our proposed SIDE achieves competitive performance against state-of-the-art methods.
Degradation-Aware Self-Attention Based Transformer for Blind Image Super-Resolution
Oct 06, 2023



Compared to CNN-based methods, Transformer-based methods achieve impressive image restoration outcomes due to their abilities to model remote dependencies. However, how to apply Transformer-based methods to the field of blind super-resolution (SR) and further make an SR network adaptive to degradation information is still an open problem. In this paper, we propose a new degradation-aware self-attention-based Transformer model, where we incorporate contrastive learning into the Transformer network for learning the degradation representations of input images with unknown noise. In particular, we integrate both CNN and Transformer components into the SR network, where we first use the CNN modulated by the degradation information to extract local features, and then employ the degradation-aware Transformer to extract global semantic features. We apply our proposed model to several popular large-scale benchmark datasets for testing, and achieve the state-of-the-art performance compared to existing methods. In particular, our method yields a PSNR of 32.43 dB on the Urban100 dataset at $\times$2 scale, 0.94 dB higher than DASR, and 26.62 dB on the Urban100 dataset at $\times$4 scale, 0.26 dB improvement over KDSR, setting a new benchmark in this area. Source code is available at: https://github.com/I2-Multimedia-Lab/DSAT/tree/main.
FGFusion: Fine-Grained Lidar-Camera Fusion for 3D Object Detection
Sep 21, 2023
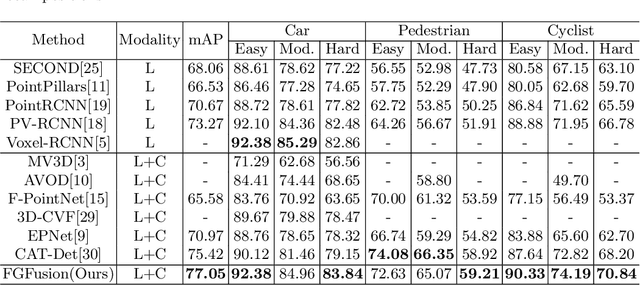

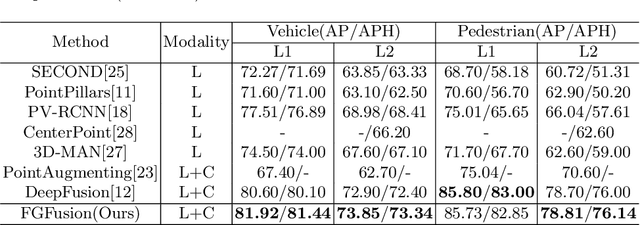
Lidars and cameras are critical sensors that provide complementary information for 3D detection in autonomous driving. While most prevalent methods progressively downscale the 3D point clouds and camera images and then fuse the high-level features, the downscaled features inevitably lose low-level detailed information. In this paper, we propose Fine-Grained Lidar-Camera Fusion (FGFusion) that make full use of multi-scale features of image and point cloud and fuse them in a fine-grained way. First, we design a dual pathway hierarchy structure to extract both high-level semantic and low-level detailed features of the image. Second, an auxiliary network is introduced to guide point cloud features to better learn the fine-grained spatial information. Finally, we propose multi-scale fusion (MSF) to fuse the last N feature maps of image and point cloud. Extensive experiments on two popular autonomous driving benchmarks, i.e. KITTI and Waymo, demonstrate the effectiveness of our method.
Polycentric Clustering and Structural Regularization for Source-free Unsupervised Domain Adaptation
Oct 14, 2022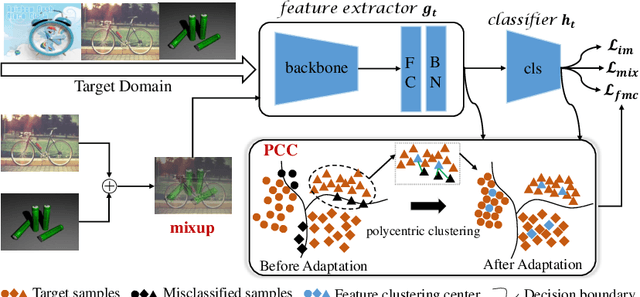
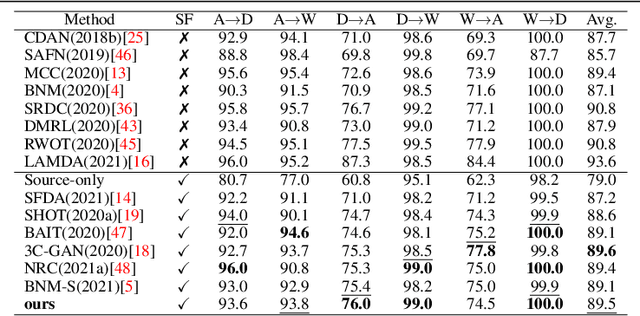
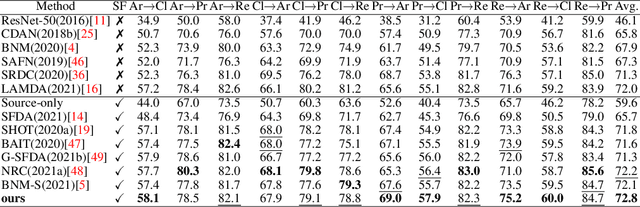
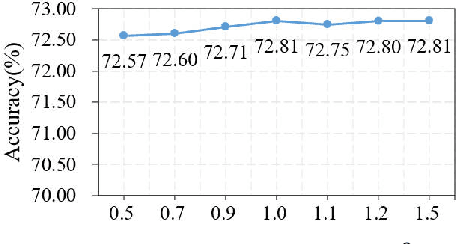
Source-Free Domain Adaptation (SFDA) aims to solve the domain adaptation problem by transferring the knowledge learned from a pre-trained source model to an unseen target domain. Most existing methods assign pseudo-labels to the target data by generating feature prototypes. However, due to the discrepancy in the data distribution between the source domain and the target domain and category imbalance in the target domain, there are severe class biases in the generated feature prototypes and noisy pseudo-labels. Besides, the data structure of the target domain is often ignored, which is crucial for clustering. In this paper, a novel framework named PCSR is proposed to tackle SFDA via a novel intra-class Polycentric Clustering and Structural Regularization strategy. Firstly, an inter-class balanced sampling strategy is proposed to generate representative feature prototypes for each class. Furthermore, k-means clustering is introduced to generate multiple clustering centers for each class in the target domain to obtain robust pseudo-labels. Finally, to enhance the model's generalization, structural regularization is introduced for the target domain. Extensive experiments on three UDA benchmark datasets show that our method performs better or similarly against the other state of the art methods, demonstrating our approach's superiority for visual domain adaptation problems.