 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSLENet: A Guidance-Enhanced Network for Underwater Camouflaged Object Detection
Sep 04, 2025
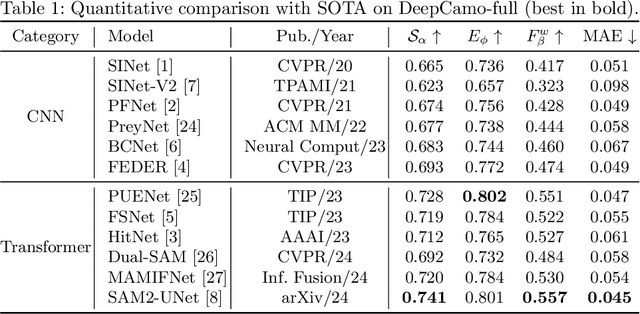

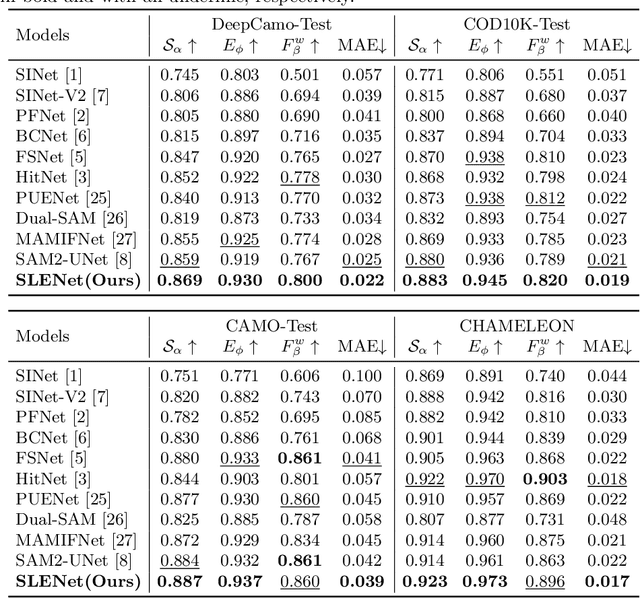
Underwater Camouflaged Object Detection (UCOD) aims to identify objects that blend seamlessly into underwater environments. This task is critically important to marine ecology. However, it remains largely underexplored and accurate identification is severely hindered by optical distortions, water turbidity, and the complex traits of marine organisms. To address these challenges, we introduce the UCOD task and present DeepCamo, a benchmark dataset designed for this domain. We also propose Semantic Localization and Enhancement Network (SLENet), a novel framework for UCOD. We first benchmark state-of-the-art COD models on DeepCamo to reveal key issues, upon which SLENet is built. In particular, we incorporate Gamma-Asymmetric Enhancement (GAE) module and a Localization Guidance Branch (LGB) to enhance multi-scale feature representation while generating a location map enriched with global semantic information. This map guides the Multi-Scale Supervised Decoder (MSSD) to produce more accurate predictions. Experiments on our DeepCamo dataset and three benchmark COD datasets confirm SLENet's superior performance over SOTA methods, and underscore its high generality for the broader COD task.
Low-power Spike-based Wearable Analytics on RRAM Crossbars
Feb 10, 2025



This work introduces a spike-based wearable analytics system utilizing Spiking Neural Networks (SNNs) deployed on an In-memory Computing engine based on RRAM crossbars, which are known for their compactness and energy-efficiency. Given the hardware constraints and noise characteristics of the underlying RRAM crossbars, we propose online adaptation of pre-trained SNNs in real-time using Direct Feedback Alignment (DFA) against traditional backpropagation (BP). Direct Feedback Alignment (DFA) learning, that allows layer-parallel gradient computations, acts as a fast, energy & area-efficient method for online adaptation of SNNs on RRAM crossbars, unleashing better algorithmic performance against those adapted using BP. Through extensive simulations using our in-house hardware evaluation engine called DFA_Sim, we find that DFA achieves upto 64.1% lower energy consumption, 10.1% lower area overhead, and a 2.1x reduction in latency compared to BP, while delivering upto 7.55% higher inference accuracy on human activity recognition (HAR) tasks.
* Accepted in 2025 IEEE International Symposium on Circuits and Systems (ISCAS)
Highly Efficient Rotation-Invariant Spectral Embedding for Scalable Incomplete Multi-View Clustering
Jan 21, 2025



Incomplete multi-view clustering presents significant challenges due to missing views. Although many existing graph-based methods aim to recover missing instances or complete similarity matrices with promising results, they still face several limitations: (1) Recovered data may be unsuitable for spectral clustering, as these methods often ignore guidance from spectral analysis; (2) Complex optimization processes require high computational burden, hindering scalability to large-scale problems; (3) Most methods do not address the rotational mismatch problem in spectral embeddings. To address these issues, we propose a highly efficient rotation-invariant spectral embedding (RISE) method for scalable incomplete multi-view clustering. RISE learns view-specific embeddings from incomplete bipartite graphs to capture the complementary information. Meanwhile, a complete consensus representation with second-order rotation-invariant property is recovered from these incomplete embeddings in a unified model. Moreover, we design a fast alternating optimization algorithm with linear complexity and promising convergence to solve the proposed formulation. Extensive experiments on multiple datasets demonstrate the effectiveness, scalability, and efficiency of RISE compared to the state-of-the-art methods.
Privacy-preserving Universal Adversarial Defense for Black-box Models
Aug 20, 2024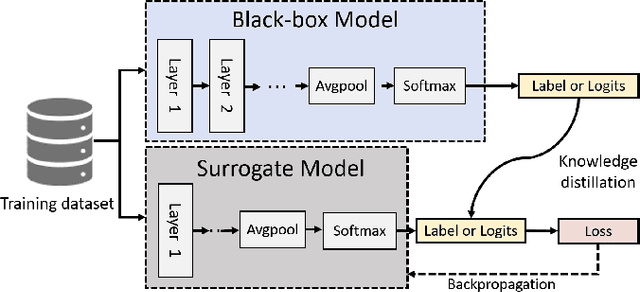
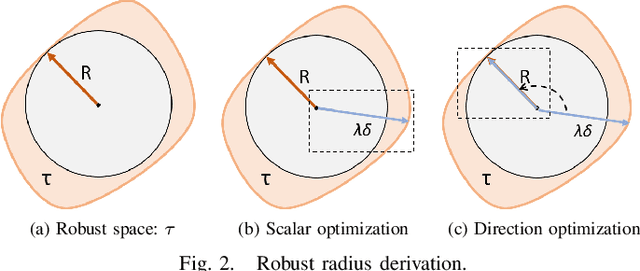
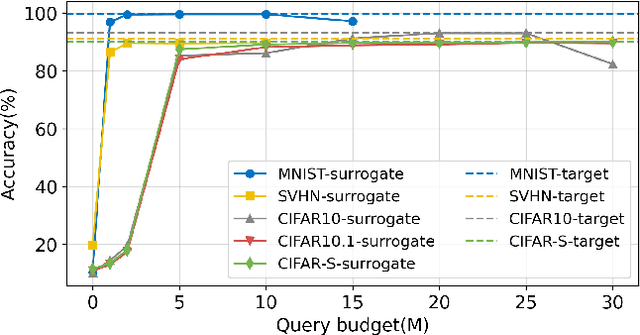
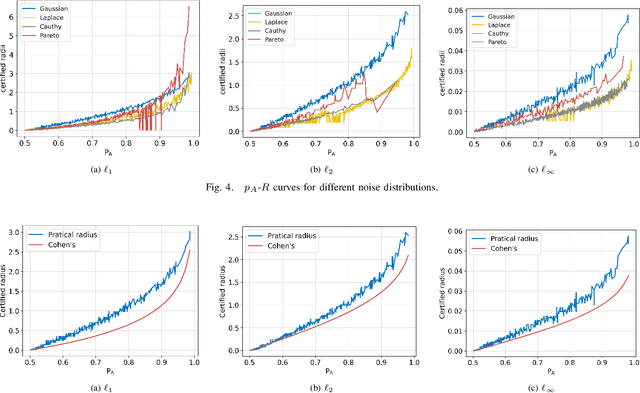
Deep neural networks (DNNs) are increasingly used in critical applications such as identity authentication and autonomous driving, where robustness against adversarial attacks is crucial. These attacks can exploit minor perturbations to cause significant prediction errors, making it essential to enhance the resilience of DNNs. Traditional defense methods often rely on access to detailed model information, which raises privacy concerns, as model owners may be reluctant to share such data. In contrast, existing black-box defense methods fail to offer a universal defense against various types of adversarial attacks. To address these challenges, we introduce DUCD, a universal black-box defense method that does not require access to the target model's parameters or architecture. Our approach involves distilling the target model by querying it with data, creating a white-box surrogate while preserving data privacy. We further enhance this surrogate model using a certified defense based on randomized smoothing and optimized noise selection, enabling robust defense against a broad range of adversarial attacks. Comparative evaluations between the certified defenses of the surrogate and target models demonstrate the effectiveness of our approach. Experiments on multiple image classification datasets show that DUCD not only outperforms existing black-box defenses but also matches the accuracy of white-box defenses, all while enhancing data privacy and reducing the success rate of membership inference attacks.
Diverse Generation while Maintaining Semantic Coordination: A Diffusion-Based Data Augmentation Method for Object Detection
Aug 06, 2024


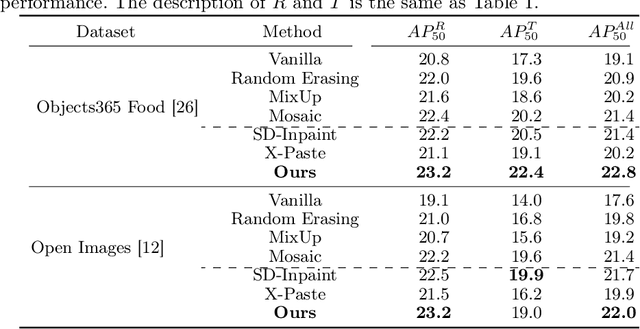
Recent studies emphasize the crucial role of data augmentation in enhancing the performance of object detection models. However,existing methodologies often struggle to effectively harmonize dataset diversity with semantic coordination.To bridge this gap, we introduce an innovative augmentation technique leveraging pre-trained conditional diffusion models to mediate this balance. Our approach encompasses the development of a Category Affinity Matrix, meticulously designed to enhance dataset diversity, and a Surrounding Region Alignment strategy, which ensures the preservation of semantic coordination in the augmented images. Extensive experimental evaluations confirm the efficacy of our method in enriching dataset diversity while seamlessly maintaining semantic coordination. Our method yields substantial average improvements of +1.4AP, +0.9AP, and +3.4AP over existing alternatives on three distinct object detection models, respectively.
Federated learning in food research
Jun 10, 2024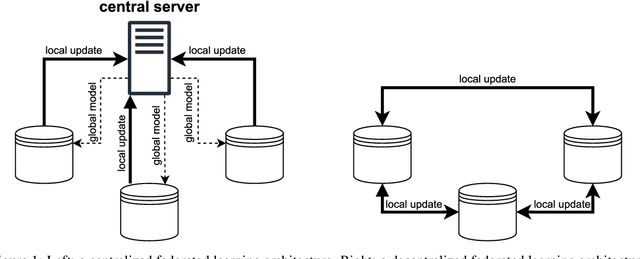
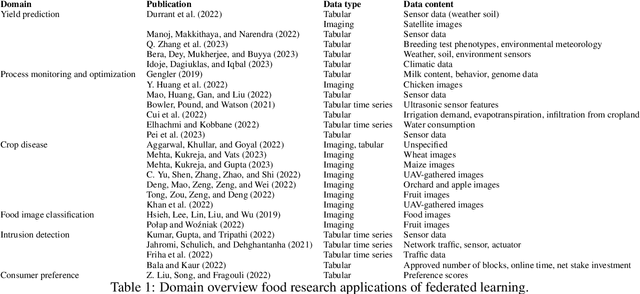
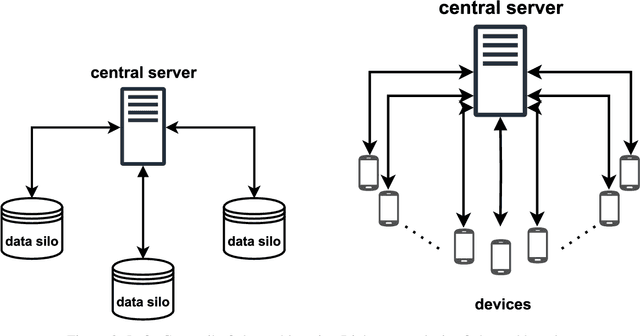

Research in the food domain is at times limited due to data sharing obstacles, such as data ownership, privacy requirements, and regulations. While important, these obstacles can restrict data-driven methods such as machine learning. Federated learning, the approach of training models on locally kept data and only sharing the learned parameters, is a potential technique to alleviate data sharing obstacles. This systematic review investigates the use of federated learning within the food domain, structures included papers in a federated learning framework, highlights knowledge gaps, and discusses potential applications. A total of 41 papers were included in the review. The current applications include solutions to water and milk quality assessment, cybersecurity of water processing, pesticide residue risk analysis, weed detection, and fraud detection, focusing on centralized horizontal federated learning. One of the gaps found was the lack of vertical or transfer federated learning and decentralized architectures.
Bulk-Switching Memristor-based Compute-In-Memory Module for Deep Neural Network Training
May 23, 2023The need for deep neural network (DNN) models with higher performance and better functionality leads to the proliferation of very large models. Model training, however, requires intensive computation time and energy. Memristor-based compute-in-memory (CIM) modules can perform vector-matrix multiplication (VMM) in situ and in parallel, and have shown great promises in DNN inference applications. However, CIM-based model training faces challenges due to non-linear weight updates, device variations, and low-precision in analog computing circuits. In this work, we experimentally implement a mixed-precision training scheme to mitigate these effects using a bulk-switching memristor CIM module. Lowprecision CIM modules are used to accelerate the expensive VMM operations, with high precision weight updates accumulated in digital units. Memristor devices are only changed when the accumulated weight update value exceeds a pre-defined threshold. The proposed scheme is implemented with a system-on-chip (SoC) of fully integrated analog CIM modules and digital sub-systems, showing fast convergence of LeNet training to 97.73%. The efficacy of training larger models is evaluated using realistic hardware parameters and shows that that analog CIM modules can enable efficient mix-precision DNN training with accuracy comparable to full-precision software trained models. Additionally, models trained on chip are inherently robust to hardware variations, allowing direct mapping to CIM inference chips without additional re-training.
PowerGAN: A Machine Learning Approach for Power Side-Channel Attack on Compute-in-Memory Accelerators
Apr 13, 2023Analog compute-in-memory (CIM) accelerators are becoming increasingly popular for deep neural network (DNN) inference due to their energy efficiency and in-situ vector-matrix multiplication (VMM) capabilities. However, as the use of DNNs expands, protecting user input privacy has become increasingly important. In this paper, we identify a security vulnerability wherein an adversary can reconstruct the user's private input data from a power side-channel attack, under proper data acquisition and pre-processing, even without knowledge of the DNN model. We further demonstrate a machine learning-based attack approach using a generative adversarial network (GAN) to enhance the reconstruction. Our results show that the attack methodology is effective in reconstructing user inputs from analog CIM accelerator power leakage, even when at large noise levels and countermeasures are applied. Specifically, we demonstrate the efficacy of our approach on the U-Net for brain tumor detection in magnetic resonance imaging (MRI) medical images, with a noise-level of 20% standard deviation of the maximum power signal value. Our study highlights a significant security vulnerability in analog CIM accelerators and proposes an effective attack methodology using a GAN to breach user privacy.
RN-Net: Reservoir Nodes-Enabled Neuromorphic Vision Sensing Network
Mar 21, 2023Event-based cameras are inspired by the sparse and asynchronous spike representation of the biological visual system. However, processing the even data requires either using expensive feature descriptors to transform spikes into frames, or using spiking neural networks that are difficult to train. In this work, we propose a neural network architecture based on simple convolution layers integrated with dynamic temporal encoding reservoirs with low hardware and training costs. The Reservoir Nodes-enabled neuromorphic vision sensing Network (RN-Net) allows the network to efficiently process asynchronous temporal features, and achieves the highest accuracy of 99.2% for DVS128 Gesture reported to date, and one of the highest accuracy of 67.5% for DVS Lip dataset at a much smaller network size. By leveraging the internal dynamics of memristors, asynchronous temporal feature encoding can be implemented at very low hardware cost without preprocessing or dedicated memory and arithmetic units. The use of simple DNN blocks and backpropagation based training rules further reduces its implementation cost. Code will be publicly available.
Unified Vision-Language Representation Modeling for E-Commerce Same-Style Products Retrieval
Feb 20, 2023Same-style products retrieval plays an important role in e-commerce platforms, aiming to identify the same products which may have different text descriptions or images. It can be used for similar products retrieval from different suppliers or duplicate products detection of one supplier. Common methods use the image as the detected object, but they only consider the visual features and overlook the attribute information contained in the textual descriptions, and perform weakly for products in image less important industries like machinery, hardware tools and electronic component, even if an additional text matching module is added. In this paper, we propose a unified vision-language modeling method for e-commerce same-style products retrieval, which is designed to represent one product with its textual descriptions and visual contents. It contains one sampling skill to collect positive pairs from user click log with category and relevance constrained, and a novel contrastive loss unit to model the image, text, and image+text representations into one joint embedding space. It is capable of cross-modal product-to-product retrieval, as well as style transfer and user-interactive search. Offline evaluations on annotated data demonstrate its superior retrieval performance, and online testings show it can attract more clicks and conversions. Moreover, this model has already been deployed online for similar products retrieval in alibaba.com, the largest B2B e-commerce platform in the world.