 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRECUR: Resource Exhaustion Attack via Recursive-Entropy Guided Counterfactual Utilization and Reflection
Feb 09, 2026Large Reasoning Models (LRMs) employ reasoning to address complex tasks. Such explicit reasoning requires extended context lengths, resulting in substantially higher resource consumption. Prior work has shown that adversarially crafted inputs can trigger redundant reasoning processes, exposing LRMs to resource-exhaustion vulnerabilities. However, the reasoning process itself, especially its reflective component, has received limited attention, even though it can lead to over-reflection and consume excessive computing power. In this paper, we introduce Recursive Entropy to quantify the risk of resource consumption in reflection, thereby revealing the safety issues inherent in inference itself. Based on Recursive Entropy, we introduce RECUR, a resource exhaustion attack via Recursive Entropy guided Counterfactual Utilization and Reflection. It constructs counterfactual questions to verify the inherent flaws and risks of LRMs. Extensive experiments demonstrate that, under benign inference, recursive entropy exhibits a pronounced decreasing trend. RECUR disrupts this trend, increasing the output length by up to 11x and decreasing throughput by 90%. Our work provides a new perspective on robust reasoning.
HeteroSample: Meta-path Guided Sampling for Heterogeneous Graph Representation Learning
Nov 11, 2024
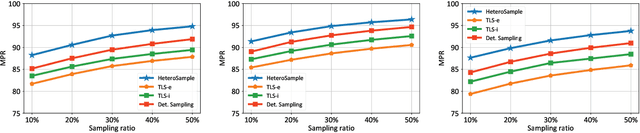
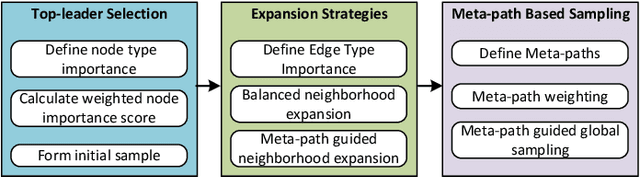
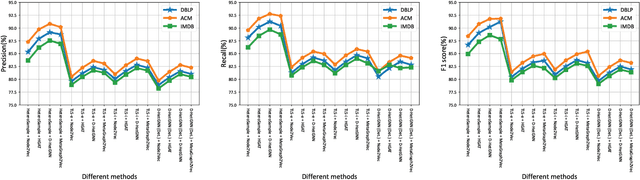
The rapid expansion of Internet of Things (IoT) has resulted in vast, heterogeneous graphs that capture complex interactions among devices, sensors, and systems. Efficient analysis of these graphs is critical for deriving insights in IoT scenarios such as smart cities, industrial IoT, and intelligent transportation systems. However, the scale and diversity of IoT-generated data present significant challenges, and existing methods often struggle with preserving the structural integrity and semantic richness of these complex graphs. Many current approaches fail to maintain the balance between computational efficiency and the quality of the insights generated, leading to potential loss of critical information necessary for accurate decision-making in IoT applications. We introduce HeteroSample, a novel sampling method designed to address these challenges by preserving the structural integrity, node and edge type distributions, and semantic patterns of IoT-related graphs. HeteroSample works by incorporating the novel top-leader selection, balanced neighborhood expansion, and meta-path guided sampling strategies. The key idea is to leverage the inherent heterogeneous structure and semantic relationships encoded by meta-paths to guide the sampling process. This approach ensures that the resulting subgraphs are representative of the original data while significantly reducing computational overhead. Extensive experiments demonstrate that HeteroSample outperforms state-of-the-art methods, achieving up to 15% higher F1 scores in tasks such as link prediction and node classification, while reducing runtime by 20%.These advantages make HeteroSample a transformative tool for scalable and accurate IoT applications, enabling more effective and efficient analysis of complex IoT systems, ultimately driving advancements in smart cities, industrial IoT, and beyond.
Privacy-preserving Universal Adversarial Defense for Black-box Models
Aug 20, 2024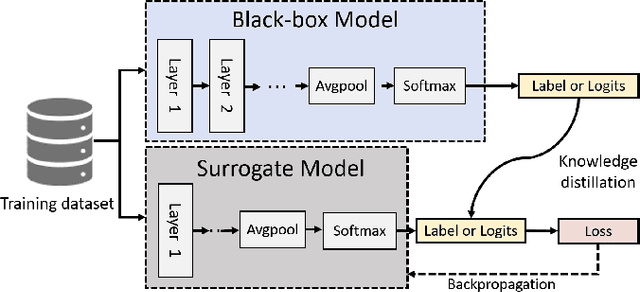
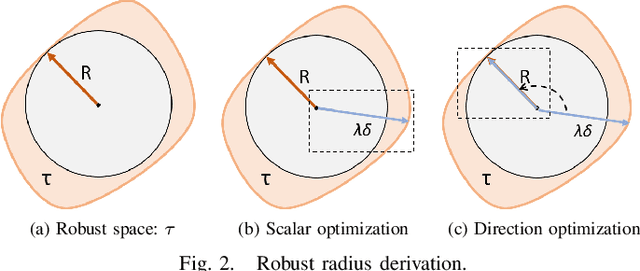
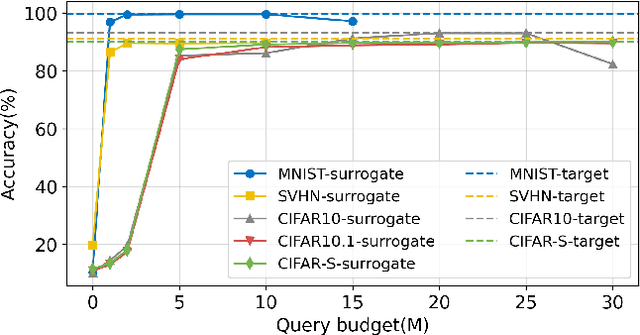
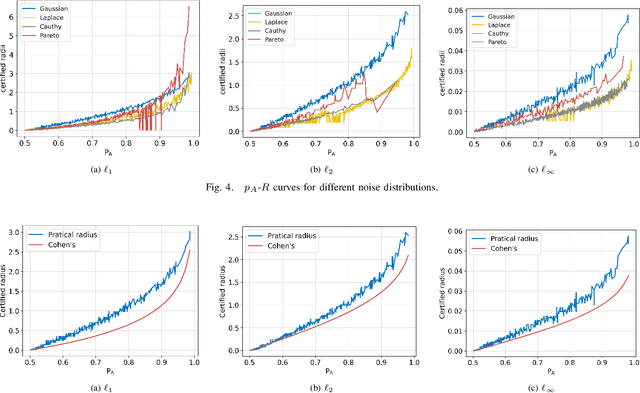
Deep neural networks (DNNs) are increasingly used in critical applications such as identity authentication and autonomous driving, where robustness against adversarial attacks is crucial. These attacks can exploit minor perturbations to cause significant prediction errors, making it essential to enhance the resilience of DNNs. Traditional defense methods often rely on access to detailed model information, which raises privacy concerns, as model owners may be reluctant to share such data. In contrast, existing black-box defense methods fail to offer a universal defense against various types of adversarial attacks. To address these challenges, we introduce DUCD, a universal black-box defense method that does not require access to the target model's parameters or architecture. Our approach involves distilling the target model by querying it with data, creating a white-box surrogate while preserving data privacy. We further enhance this surrogate model using a certified defense based on randomized smoothing and optimized noise selection, enabling robust defense against a broad range of adversarial attacks. Comparative evaluations between the certified defenses of the surrogate and target models demonstrate the effectiveness of our approach. Experiments on multiple image classification datasets show that DUCD not only outperforms existing black-box defenses but also matches the accuracy of white-box defenses, all while enhancing data privacy and reducing the success rate of membership inference attacks.
Sok: Comprehensive Security Overview, Challenges, and Future Directions of Voice-Controlled Systems
May 27, 2024



The integration of Voice Control Systems (VCS) into smart devices and their growing presence in daily life accentuate the importance of their security. Current research has uncovered numerous vulnerabilities in VCS, presenting significant risks to user privacy and security. However, a cohesive and systematic examination of these vulnerabilities and the corresponding solutions is still absent. This lack of comprehensive analysis presents a challenge for VCS designers in fully understanding and mitigating the security issues within these systems. Addressing this gap, our study introduces a hierarchical model structure for VCS, providing a novel lens for categorizing and analyzing existing literature in a systematic manner. We classify attacks based on their technical principles and thoroughly evaluate various attributes, such as their methods, targets, vectors, and behaviors. Furthermore, we consolidate and assess the defense mechanisms proposed in current research, offering actionable recommendations for enhancing VCS security. Our work makes a significant contribution by simplifying the complexity inherent in VCS security, aiding designers in effectively identifying and countering potential threats, and setting a foundation for future advancements in VCS security research.
CLAD: Robust Audio Deepfake Detection Against Manipulation Attacks with Contrastive Learning
Apr 24, 2024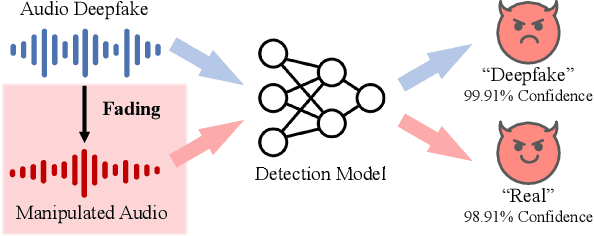
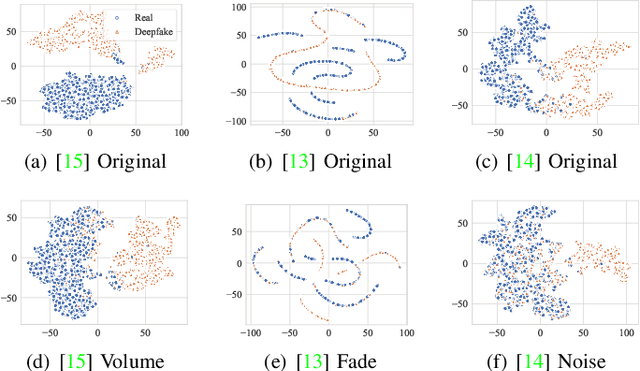
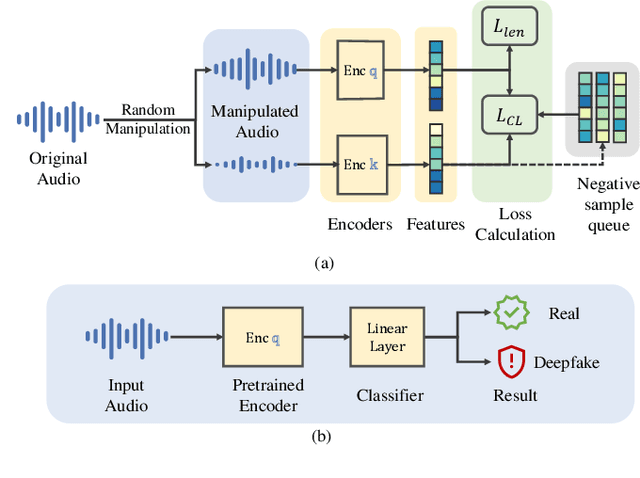
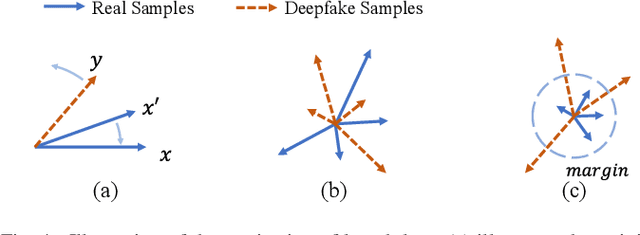
The increasing prevalence of audio deepfakes poses significant security threats, necessitating robust detection methods. While existing detection systems exhibit promise, their robustness against malicious audio manipulations remains underexplored. To bridge the gap, we undertake the first comprehensive study of the susceptibility of the most widely adopted audio deepfake detectors to manipulation attacks. Surprisingly, even manipulations like volume control can significantly bypass detection without affecting human perception. To address this, we propose CLAD (Contrastive Learning-based Audio deepfake Detector) to enhance the robustness against manipulation attacks. The key idea is to incorporate contrastive learning to minimize the variations introduced by manipulations, therefore enhancing detection robustness. Additionally, we incorporate a length loss, aiming to improve the detection accuracy by clustering real audios more closely in the feature space. We comprehensively evaluated the most widely adopted audio deepfake detection models and our proposed CLAD against various manipulation attacks. The detection models exhibited vulnerabilities, with FAR rising to 36.69%, 31.23%, and 51.28% under volume control, fading, and noise injection, respectively. CLAD enhanced robustness, reducing the FAR to 0.81% under noise injection and consistently maintaining an FAR below 1.63% across all tests. Our source code and documentation are available in the artifact repository (https://github.com/CLAD23/CLAD).