 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIstGPT: LLM-based Anomaly Detection for Spatial-Temporal Graph in Industrial Systems
Jun 01, 2026Industrial Internet systems face increasing threats from sophisticated industrial control system (ICS) attacks, resulting in critical safety incidents. However, existing tools exhibit limited effectiveness in real-time anomaly detection due to the complex dependencies among sensors and actuators. To tackle this, we present IstGPT, the first industrial anomaly detection tool based on LLMs and graph learning to provide real-time protection against a wide range of ICS attacks. IstGPT achieves fine-grained and precise modeling on spatial-temporal dependencies in industrial cyber-physical systems. It first leverages industrial multi-modal knowledge, including operational data, technical documents, and system diagrams, to extract sensor-actuator dependency graphs via multi-stage prompt engineering. Then, LLM-Optimation iteratively refines the graph based on node accuracy, edge consistency, and logical coherence. Finally, IstGPT integrated improved graph neural networks with an encoder-decoder architecture to detect anomalies via reconstruction errors. We evaluate IstGPT against 12 state-of-the-art baselines on 9 datasets, including 2 public, 6 simulated, and a real-world robotic arm dataset. IstGPT achieves the best F1-scores and eTaF1 (a newer time-aware metric) across nine datasets. We further discuss the feasibility of deploying IstGPT in real-world industrial scenarios.
When Convenience Becomes Risk: A Semantic View of Under-Specification in Host-Acting Agents
Mar 22, 2026Host-acting agents promise a convenient interaction model in which users specify goals and the system determines how to realize them. We argue that this convenience introduces a distinct security problem: semantic under-specification in goal specification. User instructions are typically goal-oriented, yet they often leave process constraints, safety boundaries, persistence, and exposure insufficiently specified. As a result, the agent must complete missing execution semantics before acting, and this completion can produce risky host-side plans even when the user-stated goal is benign. In this paper, we develop a semantic threat model, present a taxonomy of semantic-induced risky completion patterns, and study the phenomenon through an OpenClaw-centered case study and execution-trace analysis. We further derive defense design principles for making execution boundaries explicit and constraining risky completion. These findings suggest that securing host-acting agents requires governing not only which actions are allowed at execution time, but also how goal-only instructions are translated into executable plans.
HNCSE: Advancing Sentence Embeddings via Hybrid Contrastive Learning with Hard Negatives
Nov 19, 2024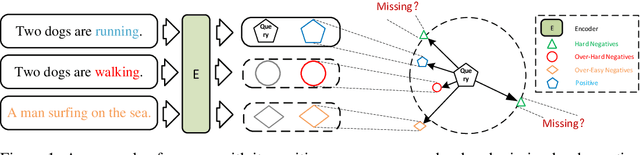
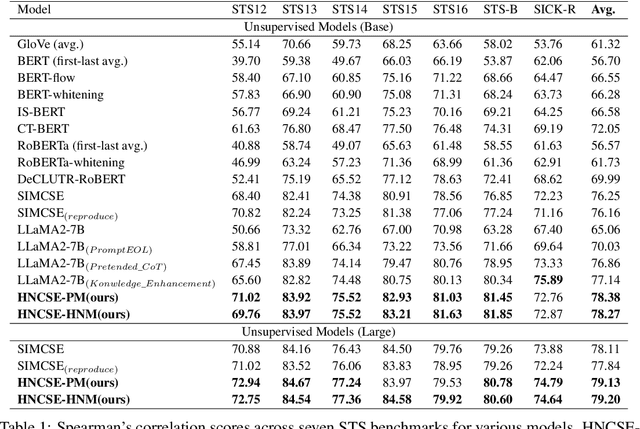
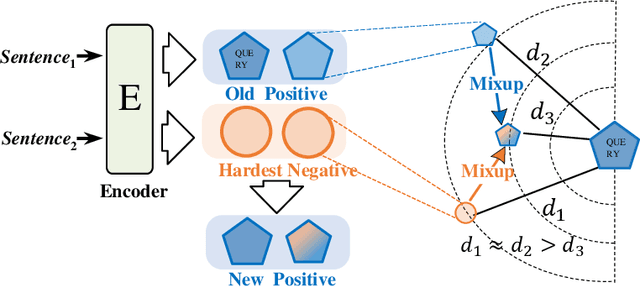
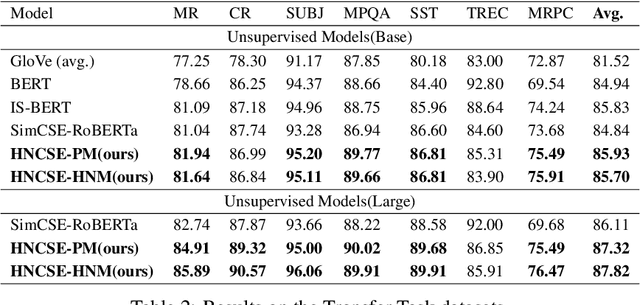
Unsupervised sentence representation learning remains a critical challenge in modern natural language processing (NLP) research. Recently, contrastive learning techniques have achieved significant success in addressing this issue by effectively capturing textual semantics. Many such approaches prioritize the optimization using negative samples. In fields such as computer vision, hard negative samples (samples that are close to the decision boundary and thus more difficult to distinguish) have been shown to enhance representation learning. However, adapting hard negatives to contrastive sentence learning is complex due to the intricate syntactic and semantic details of text. To address this problem, we propose HNCSE, a novel contrastive learning framework that extends the leading SimCSE approach. The hallmark of HNCSE is its innovative use of hard negative samples to enhance the learning of both positive and negative samples, thereby achieving a deeper semantic understanding. Empirical tests on semantic textual similarity and transfer task datasets validate the superiority of HNCSE.
HeteroSample: Meta-path Guided Sampling for Heterogeneous Graph Representation Learning
Nov 11, 2024
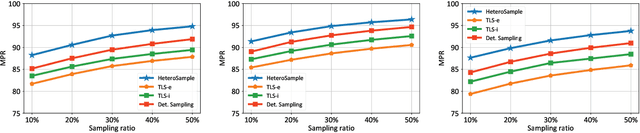
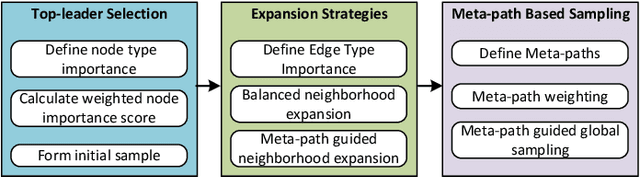
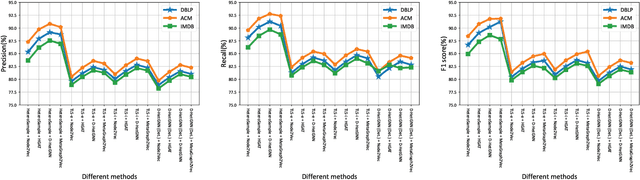
The rapid expansion of Internet of Things (IoT) has resulted in vast, heterogeneous graphs that capture complex interactions among devices, sensors, and systems. Efficient analysis of these graphs is critical for deriving insights in IoT scenarios such as smart cities, industrial IoT, and intelligent transportation systems. However, the scale and diversity of IoT-generated data present significant challenges, and existing methods often struggle with preserving the structural integrity and semantic richness of these complex graphs. Many current approaches fail to maintain the balance between computational efficiency and the quality of the insights generated, leading to potential loss of critical information necessary for accurate decision-making in IoT applications. We introduce HeteroSample, a novel sampling method designed to address these challenges by preserving the structural integrity, node and edge type distributions, and semantic patterns of IoT-related graphs. HeteroSample works by incorporating the novel top-leader selection, balanced neighborhood expansion, and meta-path guided sampling strategies. The key idea is to leverage the inherent heterogeneous structure and semantic relationships encoded by meta-paths to guide the sampling process. This approach ensures that the resulting subgraphs are representative of the original data while significantly reducing computational overhead. Extensive experiments demonstrate that HeteroSample outperforms state-of-the-art methods, achieving up to 15% higher F1 scores in tasks such as link prediction and node classification, while reducing runtime by 20%.These advantages make HeteroSample a transformative tool for scalable and accurate IoT applications, enabling more effective and efficient analysis of complex IoT systems, ultimately driving advancements in smart cities, industrial IoT, and beyond.
SoK: Comparing Different Membership Inference Attacks with a Comprehensive Benchmark
Jul 12, 2023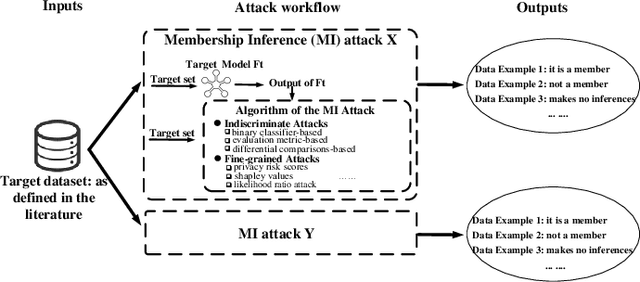
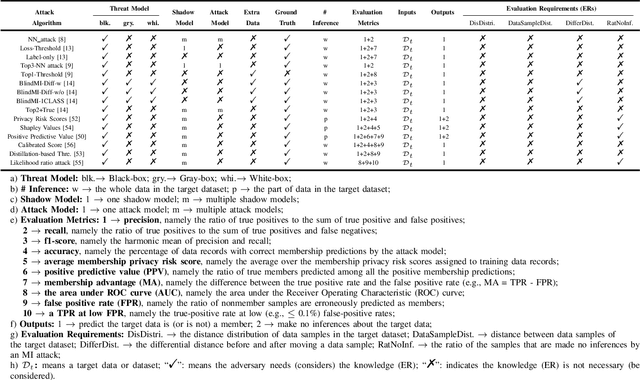

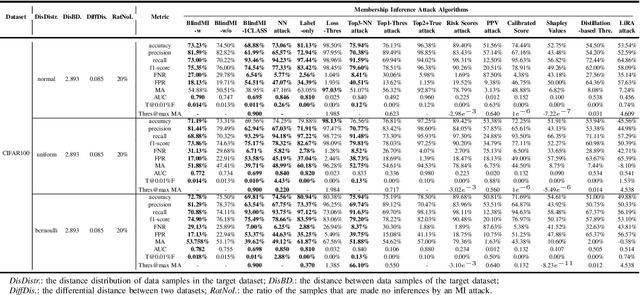
Membership inference (MI) attacks threaten user privacy through determining if a given data example has been used to train a target model. However, it has been increasingly recognized that the "comparing different MI attacks" methodology used in the existing works has serious limitations. Due to these limitations, we found (through the experiments in this work) that some comparison results reported in the literature are quite misleading. In this paper, we seek to develop a comprehensive benchmark for comparing different MI attacks, called MIBench, which consists not only the evaluation metrics, but also the evaluation scenarios. And we design the evaluation scenarios from four perspectives: the distance distribution of data samples in the target dataset, the distance between data samples of the target dataset, the differential distance between two datasets (i.e., the target dataset and a generated dataset with only nonmembers), and the ratio of the samples that are made no inferences by an MI attack. The evaluation metrics consist of ten typical evaluation metrics. We have identified three principles for the proposed "comparing different MI attacks" methodology, and we have designed and implemented the MIBench benchmark with 84 evaluation scenarios for each dataset. In total, we have used our benchmark to fairly and systematically compare 15 state-of-the-art MI attack algorithms across 588 evaluation scenarios, and these evaluation scenarios cover 7 widely used datasets and 7 representative types of models. All codes and evaluations of MIBench are publicly available at https://github.com/MIBench/MIBench.github.io/blob/main/README.md.
Gradient Leakage Defense with Key-Lock Module for Federated Learning
May 06, 2023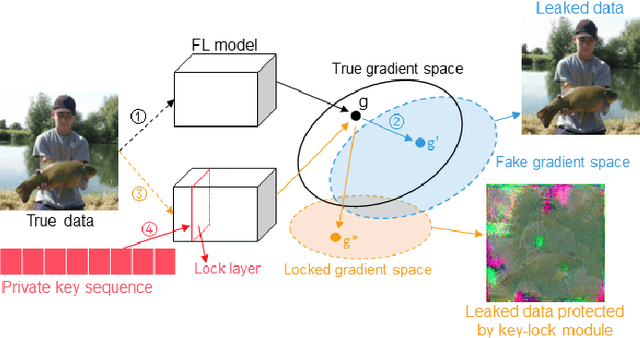

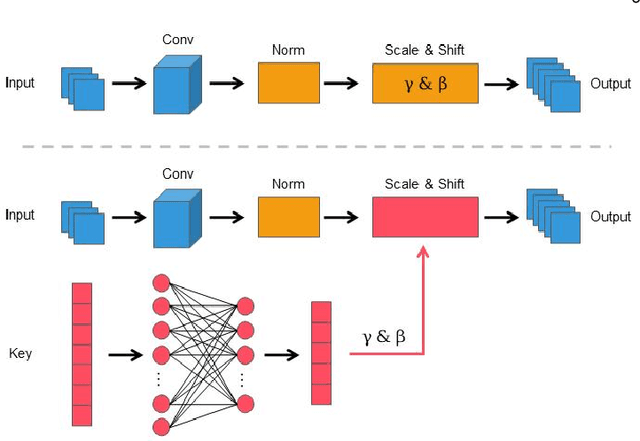
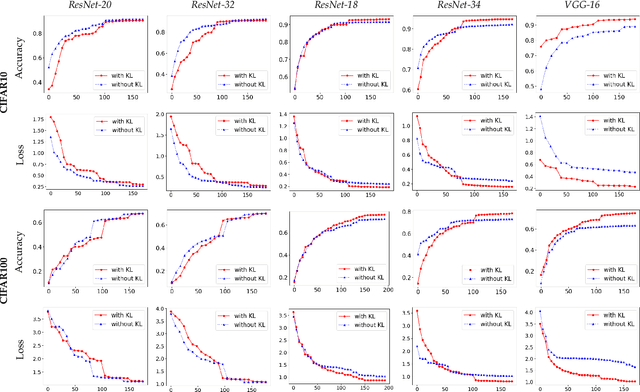
Federated Learning (FL) is a widely adopted privacy-preserving machine learning approach where private data remains local, enabling secure computations and the exchange of local model gradients between local clients and third-party parameter servers. However, recent findings reveal that privacy may be compromised and sensitive information potentially recovered from shared gradients. In this study, we offer detailed analysis and a novel perspective on understanding the gradient leakage problem. These theoretical works lead to a new gradient leakage defense technique that secures arbitrary model architectures using a private key-lock module. Only the locked gradient is transmitted to the parameter server for global model aggregation. Our proposed learning method is resistant to gradient leakage attacks, and the key-lock module is designed and trained to ensure that, without the private information of the key-lock module: a) reconstructing private training data from the shared gradient is infeasible; and b) the global model's inference performance is significantly compromised. We discuss the theoretical underpinnings of why gradients can leak private information and provide theoretical proof of our method's effectiveness. We conducted extensive empirical evaluations with a total of forty-four models on several popular benchmarks, demonstrating the robustness of our proposed approach in both maintaining model performance and defending against gradient leakage attacks.
Privacy-preserving Generative Framework Against Membership Inference Attacks
Feb 11, 2022Artificial intelligence and machine learning have been integrated into all aspects of our lives and the privacy of personal data has attracted more and more attention. Since the generation of the model needs to extract the effective information of the training data, the model has the risk of leaking the privacy of the training data. Membership inference attacks can measure the model leakage of source data to a certain degree. In this paper, we design a privacy-preserving generative framework against membership inference attacks, through the information extraction and data generation capabilities of the generative model variational autoencoder (VAE) to generate synthetic data that meets the needs of differential privacy. Instead of adding noise to the model output or tampering with the training process of the target model, we directly process the original data. We first map the source data to the latent space through the VAE model to get the latent code, then perform noise process satisfying metric privacy on the latent code, and finally use the VAE model to reconstruct the synthetic data. Our experimental evaluation demonstrates that the machine learning model trained with newly generated synthetic data can effectively resist membership inference attacks and still maintain high utility.
Backdoor Defense with Machine Unlearning
Jan 24, 2022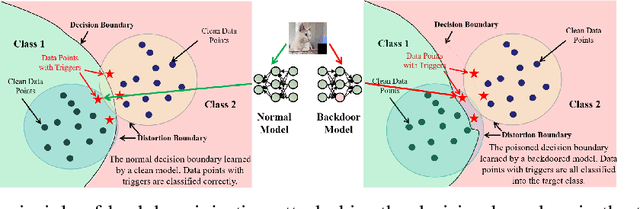
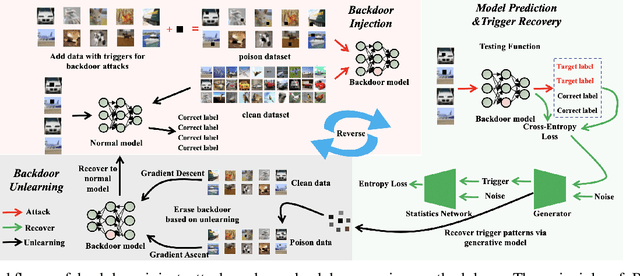

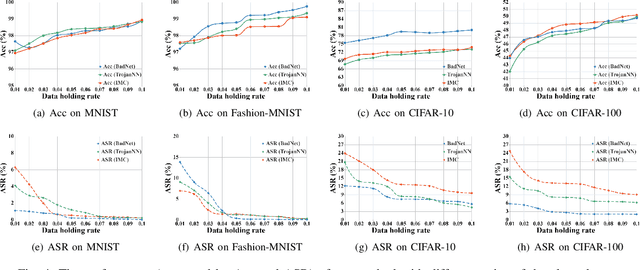
Backdoor injection attack is an emerging threat to the security of neural networks, however, there still exist limited effective defense methods against the attack. In this paper, we propose BAERASE, a novel method that can erase the backdoor injected into the victim model through machine unlearning. Specifically, BAERASE mainly implements backdoor defense in two key steps. First, trigger pattern recovery is conducted to extract the trigger patterns infected by the victim model. Here, the trigger pattern recovery problem is equivalent to the one of extracting an unknown noise distribution from the victim model, which can be easily resolved by the entropy maximization based generative model. Subsequently, BAERASE leverages these recovered trigger patterns to reverse the backdoor injection procedure and induce the victim model to erase the polluted memories through a newly designed gradient ascent based machine unlearning method. Compared with the previous machine unlearning solutions, the proposed approach gets rid of the reliance on the full access to training data for retraining and shows higher effectiveness on backdoor erasing than existing fine-tuning or pruning methods. Moreover, experiments show that BAERASE can averagely lower the attack success rates of three kinds of state-of-the-art backdoor attacks by 99\% on four benchmark datasets.
Cloud-based Federated Boosting for Mobile Crowdsensing
May 09, 2020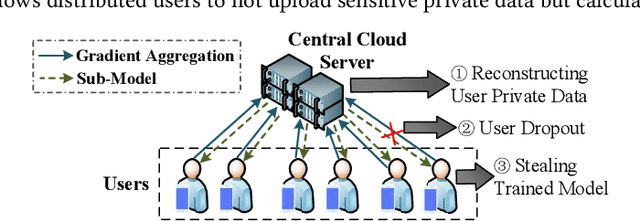

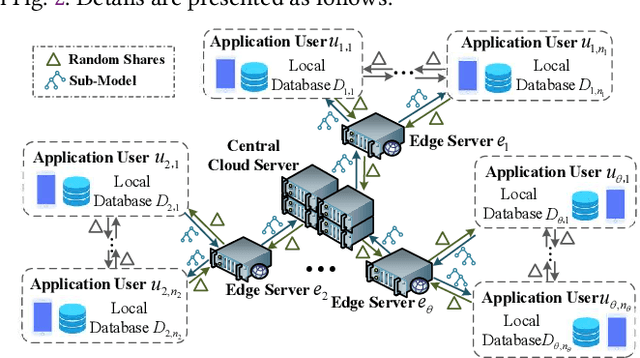
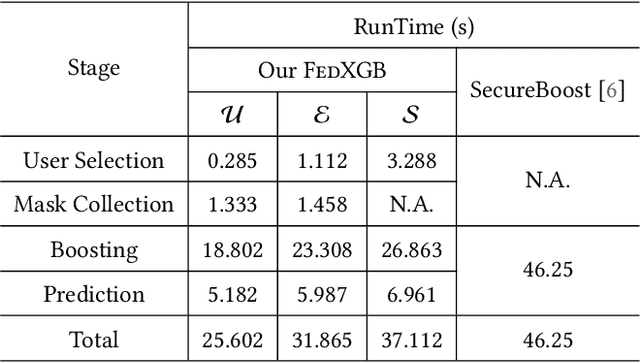
The application of federated extreme gradient boosting to mobile crowdsensing apps brings several benefits, in particular high performance on efficiency and classification. However, it also brings a new challenge for data and model privacy protection. Besides it being vulnerable to Generative Adversarial Network (GAN) based user data reconstruction attack, there is not the existing architecture that considers how to preserve model privacy. In this paper, we propose a secret sharing based federated learning architecture FedXGB to achieve the privacy-preserving extreme gradient boosting for mobile crowdsensing. Specifically, we first build a secure classification and regression tree (CART) of XGBoost using secret sharing. Then, we propose a secure prediction protocol to protect the model privacy of XGBoost in mobile crowdsensing. We conduct a comprehensive theoretical analysis and extensive experiments to evaluate the security, effectiveness, and efficiency of FedXGB. The results indicate that FedXGB is secure against the honest-but-curious adversaries and attains less than 1% accuracy loss compared with the original XGBoost model.
Learn to Forget: User-Level Memorization Elimination in Federated Learning
Mar 24, 2020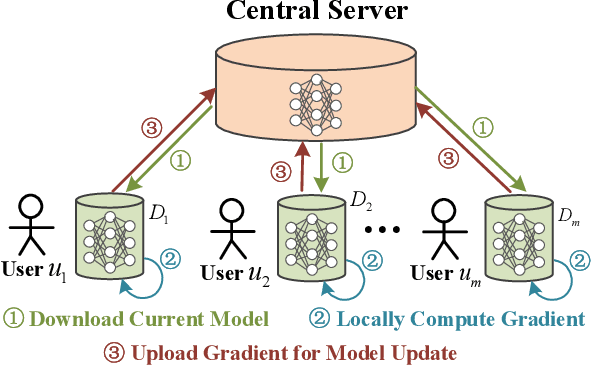
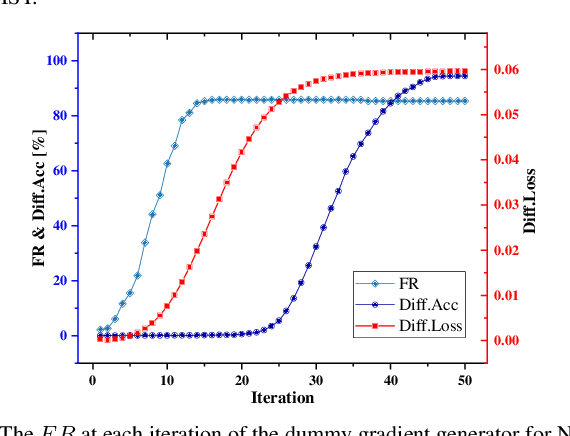
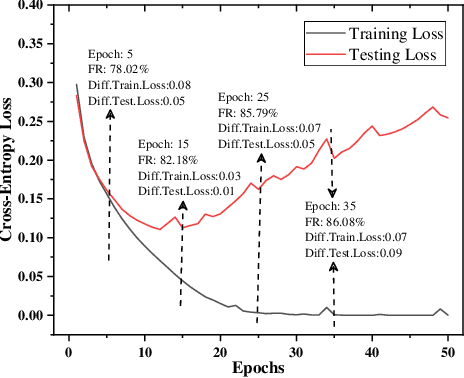
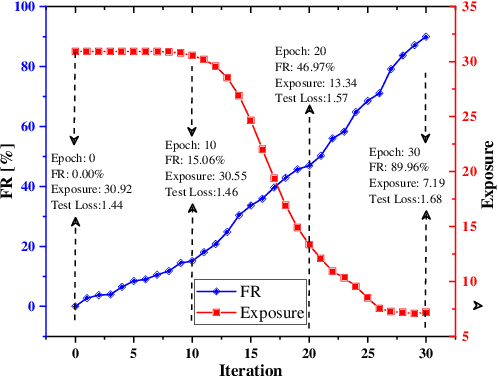
Federated learning is a decentralized machine learning technique that evokes widespread attention in both the research field and the real-world market. However, the current privacy-preserving federated learning scheme only provides a secure way for the users to contribute their private data but never leaves a way to withdraw the contribution to model update. Such an irreversible setting potentially breaks the regulations about data protection and increases the risk of data extraction. To resolve the problem, this paper describes a novel concept for federated learning, called memorization elimination. Based on the concept, we propose \sysname, a federated learning framework that allows the user to eliminate the memorization of its private data in the trained model. Specifically, each user in \sysname is deployed with a trainable dummy gradient generator. After steps of training, the generator can produce dummy gradients to stimulate the neurons of a machine learning model to eliminate the memorization of the specific data. Also, we prove that the additional memorization elimination service of \sysname does not break the common procedure of federated learning or lower its security.