 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSonicverse: A Multisensory Simulation Platform for Embodied Household Agents that See and Hear
Jun 01, 2023



Developing embodied agents in simulation has been a key research topic in recent years. Exciting new tasks, algorithms, and benchmarks have been developed in various simulators. However, most of them assume deaf agents in silent environments, while we humans perceive the world with multiple senses. We introduce Sonicverse, a multisensory simulation platform with integrated audio-visual simulation for training household agents that can both see and hear. Sonicverse models realistic continuous audio rendering in 3D environments in real-time. Together with a new audio-visual VR interface that allows humans to interact with agents with audio, Sonicverse enables a series of embodied AI tasks that need audio-visual perception. For semantic audio-visual navigation in particular, we also propose a new multi-task learning model that achieves state-of-the-art performance. In addition, we demonstrate Sonicverse's realism via sim-to-real transfer, which has not been achieved by other simulators: an agent trained in Sonicverse can successfully perform audio-visual navigation in real-world environments. Sonicverse is available at: https://github.com/StanfordVL/Sonicverse.
NLP-based Cross-Layer 5G Vulnerabilities Detection via Fuzzing Generated Run-Time Profiling
May 14, 2023The effectiveness and efficiency of 5G software stack vulnerability and unintended behavior detection are essential for 5G assurance, especially for its applications in critical infrastructures. Scalability and automation are the main challenges in testing approaches and cybersecurity research. In this paper, we propose an innovative approach for automatically detecting vulnerabilities, unintended emergent behaviors, and performance degradation in 5G stacks via run-time profiling documents corresponding to fuzz testing in code repositories. Piloting on srsRAN, we map the run-time profiling via Logging Information (LogInfo) generated by fuzzing test to a high dimensional metric space first and then construct feature spaces based on their timestamp information. Lastly, we further leverage machine learning-based classification algorithms, including Logistic Regression, K-Nearest Neighbors, and Random Forest to categorize the impacts on performance and security attributes. The performance of the proposed approach has high accuracy, ranging from $ 93.4 \% $ to $ 95.9 \% $, in detecting the fuzzing impacts. In addition, the proof of concept could identify and prioritize real-time vulnerabilities on 5G infrastructures and critical applications in various verticals.
Contextualize differential privacy in image database: a lightweight image differential privacy approach based on principle component analysis inverse
Feb 19, 2022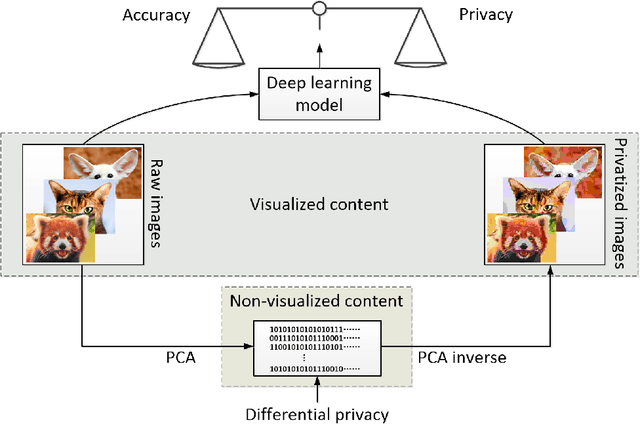


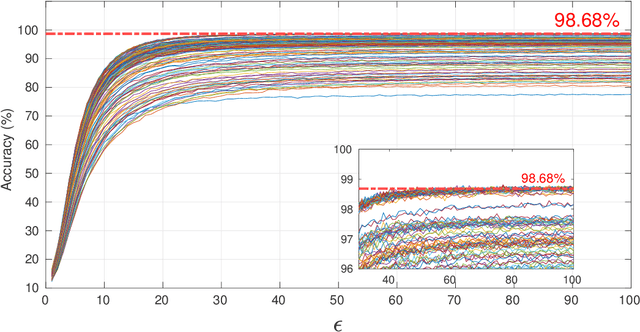
Differential privacy (DP) has been the de-facto standard to preserve privacy-sensitive information in database. Nevertheless, there lacks a clear and convincing contextualization of DP in image database, where individual images' indistinguishable contribution to a certain analysis can be achieved and observed when DP is exerted. As a result, the privacy-accuracy trade-off due to integrating DP is insufficiently demonstrated in the context of differentially-private image database. This work aims at contextualizing DP in image database by an explicit and intuitive demonstration of integrating conceptional differential privacy with images. To this end, we design a lightweight approach dedicating to privatizing image database as a whole and preserving the statistical semantics of the image database to an adjustable level, while making individual images' contribution to such statistics indistinguishable. The designed approach leverages principle component analysis (PCA) to reduce the raw image with large amount of attributes to a lower dimensional space whereby DP is performed, so as to decrease the DP load of calculating sensitivity attribute-by-attribute. The DP-exerted image data, which is not visible in its privatized format, is visualized through PCA inverse such that both a human and machine inspector can evaluate the privatization and quantify the privacy-accuracy trade-off in an analysis on the privatized image database. Using the devised approach, we demonstrate the contextualization of DP in images by two use cases based on deep learning models, where we show the indistinguishability of individual images induced by DP and the privatized images' retention of statistical semantics in deep learning tasks, which is elaborated by quantitative analyses on the privacy-accuracy trade-off under different privatization settings.
Cloud-based Federated Boosting for Mobile Crowdsensing
May 09, 2020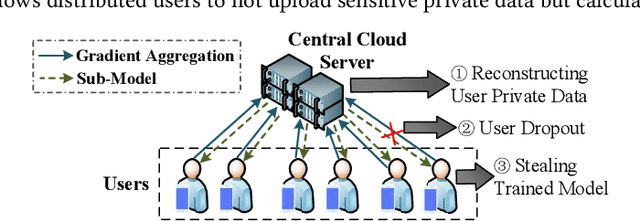

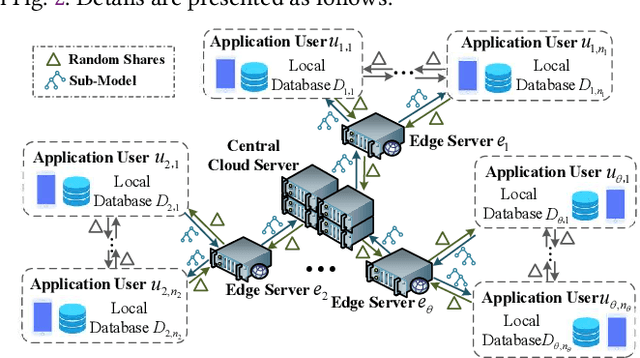
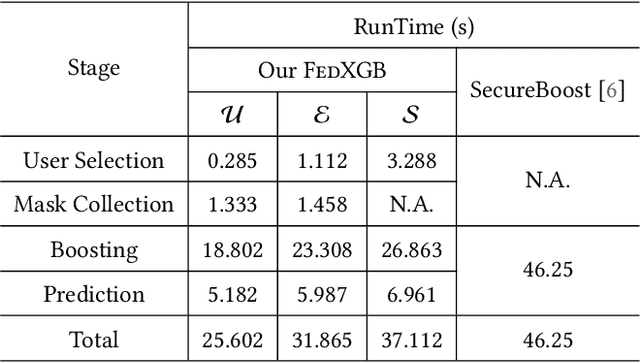
The application of federated extreme gradient boosting to mobile crowdsensing apps brings several benefits, in particular high performance on efficiency and classification. However, it also brings a new challenge for data and model privacy protection. Besides it being vulnerable to Generative Adversarial Network (GAN) based user data reconstruction attack, there is not the existing architecture that considers how to preserve model privacy. In this paper, we propose a secret sharing based federated learning architecture FedXGB to achieve the privacy-preserving extreme gradient boosting for mobile crowdsensing. Specifically, we first build a secure classification and regression tree (CART) of XGBoost using secret sharing. Then, we propose a secure prediction protocol to protect the model privacy of XGBoost in mobile crowdsensing. We conduct a comprehensive theoretical analysis and extensive experiments to evaluate the security, effectiveness, and efficiency of FedXGB. The results indicate that FedXGB is secure against the honest-but-curious adversaries and attains less than 1% accuracy loss compared with the original XGBoost model.
Revocable Federated Learning: A Benchmark of Federated Forest
Nov 08, 2019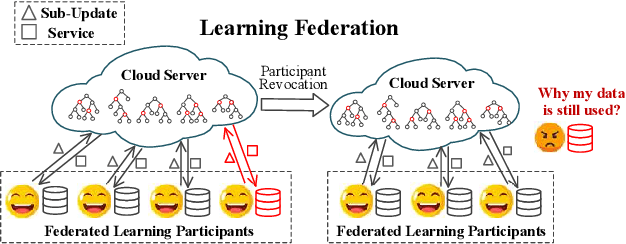

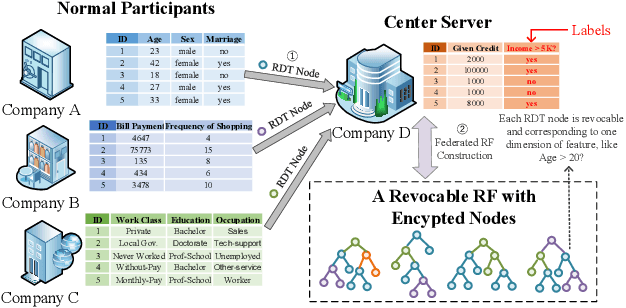
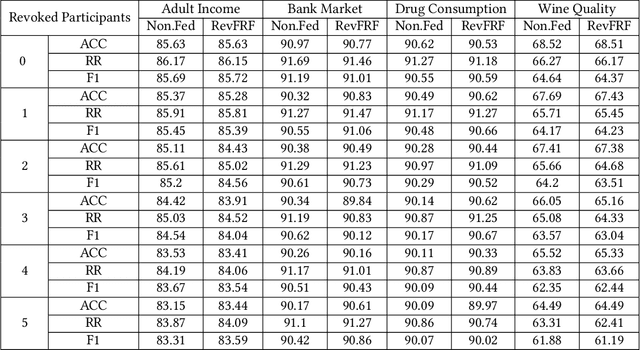
A learning federation is composed of multiple participants who use the federated learning technique to collaboratively train a machine learning model without directly revealing the local data. Nevertheless, the existing federated learning frameworks have a serious defect that even a participant is revoked, its data are still remembered by the trained model. In a company-level cooperation, allowing the remaining companies to use a trained model that contains the memories from a revoked company is obviously unacceptable, because it can lead to a big conflict of interest. Therefore, we emphatically discuss the participant revocation problem of federated learning and design a revocable federated random forest (RF) framework, RevFRF, to further illustrate the concept of revocable federated learning. In RevFRF, we first define the security problems to be resolved by a revocable federated RF. Then, a suite of homomorphic encryption based secure protocols are designed for federated RF construction, prediction and revocation. Through theoretical analysis and experiments, we show that the protocols can securely and efficiently implement collaborative training of an RF and ensure that the memories of a revoked participant in the trained RF are securely removed.