 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeS-MDMA: Sensitivity-Aware Model Division Multiple Access for Satellite-Ground Semantic Communication
Jan 25, 2026Satellite-ground semantic communication (SemCom) is expected to play a pivotal role in convergence of communication and AI (ComAI), particularly in enabling intelligent and efficient multi-user data transmission. However, the inherent bandwidth constraints and user interference in satellite-ground systems pose significant challenges to semantic fidelity and transmission robustness. To address these issues, we propose a sensitivity-aware model division multiple access (S-MDMA) framework tailored for bandwidth-limited multi-user scenarios. The proposed framework first performs semantic extraction and merging based on the MDMA architecture to consolidate redundant information. To further improve transmission efficiency, a semantic sensitivity sorting algorithm is presented, which can selectively retain key semantic features. In addition, to mitigate inter-user interference, the framework incorporates orthogonal embedding of semantic features and introduces a multi-user reconstruction loss function to guide joint optimization. Experimental results on open-source datasets demonstrate that S-MDMA consistently outperforms existing methods, achieving robust and high-fidelity reconstruction across diverse signal-to-noise ratio (SNR) conditions and user configurations.
JIANG: Chinese Open Foundation Language Model
Aug 01, 2023
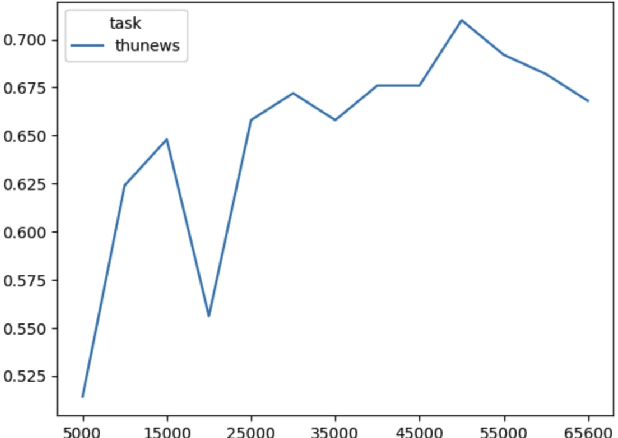


With the advancements in large language model technology, it has showcased capabilities that come close to those of human beings across various tasks. This achievement has garnered significant interest from companies and scientific research institutions, leading to substantial investments in the research and development of these models. While numerous large models have emerged during this period, the majority of them have been trained primarily on English data. Although they exhibit decent performance in other languages, such as Chinese, their potential remains limited due to factors like vocabulary design and training corpus. Consequently, their ability to fully express their capabilities in Chinese falls short. To address this issue, we introduce the model named JIANG (Chinese pinyin of ginger) specifically designed for the Chinese language. We have gathered a substantial amount of Chinese corpus to train the model and have also optimized its structure. The extensive experimental results demonstrate the excellent performance of our model.
Deep Learning with Passive Optical Nonlinear Mapping
Jul 18, 2023Deep learning has fundamentally transformed artificial intelligence, but the ever-increasing complexity in deep learning models calls for specialized hardware accelerators. Optical accelerators can potentially offer enhanced performance, scalability, and energy efficiency. However, achieving nonlinear mapping, a critical component of neural networks, remains challenging optically. Here, we introduce a design that leverages multiple scattering in a reverberating cavity to passively induce optical nonlinear random mapping, without the need for additional laser power. A key advantage emerging from our work is that we show we can perform optical data compression, facilitated by multiple scattering in the cavity, to efficiently compress and retain vital information while also decreasing data dimensionality. This allows rapid optical information processing and generation of low dimensional mixtures of highly nonlinear features. These are particularly useful for applications demanding high-speed analysis and responses such as in edge computing devices. Utilizing rapid optical information processing capabilities, our optical platforms could potentially offer more efficient and real-time processing solutions for a broad range of applications. We demonstrate the efficacy of our design in improving computational performance across tasks, including classification, image reconstruction, key-point detection, and object detection, all achieved through optical data compression combined with a digital decoder. Notably, we observed high performance, at an extreme compression ratio, for real-time pedestrian detection. Our findings pave the way for novel algorithms and architectural designs for optical computing.
Emerging Threats in Deep Learning-Based Autonomous Driving: A Comprehensive Survey
Oct 19, 2022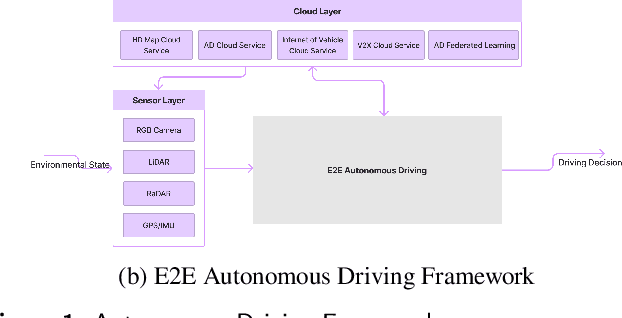
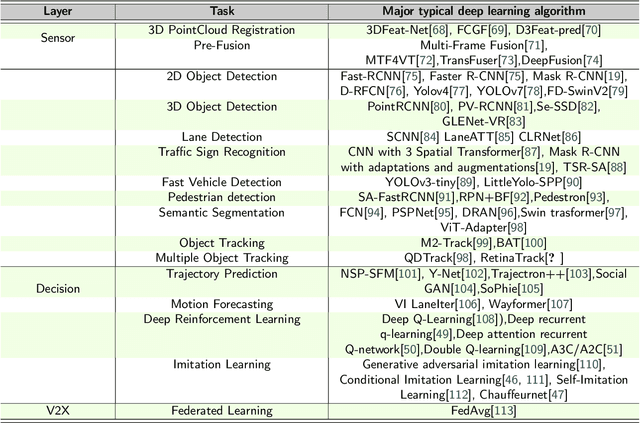
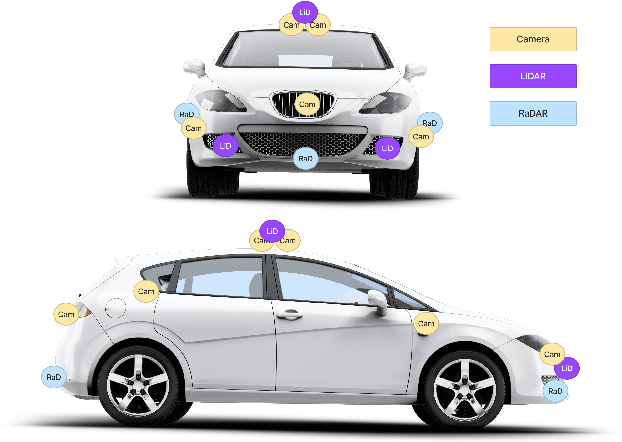
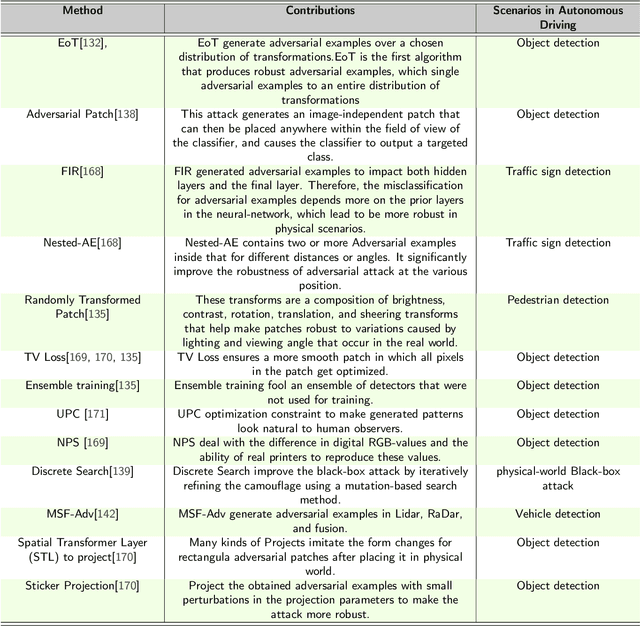
Since the 2004 DARPA Grand Challenge, the autonomous driving technology has witnessed nearly two decades of rapid development. Particularly, in recent years, with the application of new sensors and deep learning technologies extending to the autonomous field, the development of autonomous driving technology has continued to make breakthroughs. Thus, many carmakers and high-tech giants dedicated to research and system development of autonomous driving. However, as the foundation of autonomous driving, the deep learning technology faces many new security risks. The academic community has proposed deep learning countermeasures against the adversarial examples and AI backdoor, and has introduced them into the autonomous driving field for verification. Deep learning security matters to autonomous driving system security, and then matters to personal safety, which is an issue that deserves attention and research.This paper provides an summary of the concepts, developments and recent research in deep learning security technologies in autonomous driving. Firstly, we briefly introduce the deep learning framework and pipeline in the autonomous driving system, which mainly include the deep learning technologies and algorithms commonly used in this field. Moreover, we focus on the potential security threats of the deep learning based autonomous driving system in each functional layer in turn. We reviews the development of deep learning attack technologies to autonomous driving, investigates the State-of-the-Art algorithms, and reveals the potential risks. At last, we provides an outlook on deep learning security in the autonomous driving field and proposes recommendations for building a safe and trustworthy autonomous driving system.
Contextualize differential privacy in image database: a lightweight image differential privacy approach based on principle component analysis inverse
Feb 19, 2022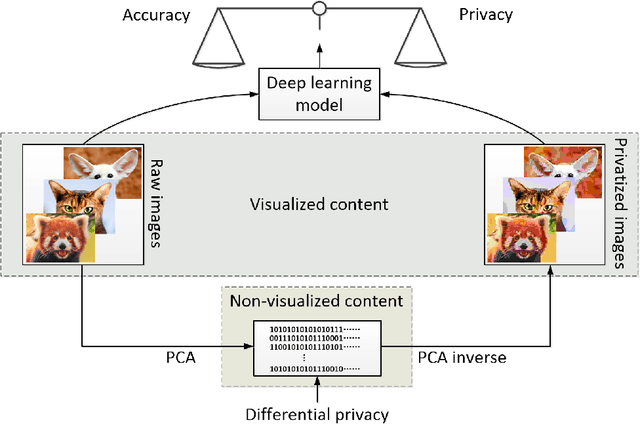


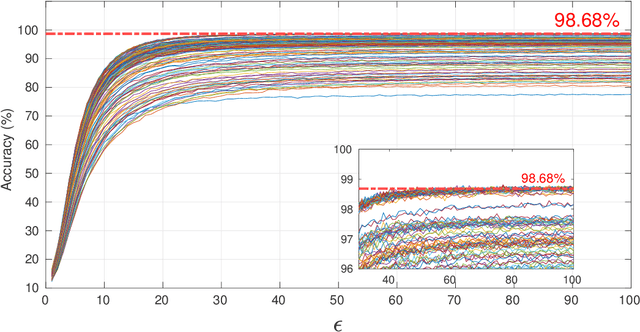
Differential privacy (DP) has been the de-facto standard to preserve privacy-sensitive information in database. Nevertheless, there lacks a clear and convincing contextualization of DP in image database, where individual images' indistinguishable contribution to a certain analysis can be achieved and observed when DP is exerted. As a result, the privacy-accuracy trade-off due to integrating DP is insufficiently demonstrated in the context of differentially-private image database. This work aims at contextualizing DP in image database by an explicit and intuitive demonstration of integrating conceptional differential privacy with images. To this end, we design a lightweight approach dedicating to privatizing image database as a whole and preserving the statistical semantics of the image database to an adjustable level, while making individual images' contribution to such statistics indistinguishable. The designed approach leverages principle component analysis (PCA) to reduce the raw image with large amount of attributes to a lower dimensional space whereby DP is performed, so as to decrease the DP load of calculating sensitivity attribute-by-attribute. The DP-exerted image data, which is not visible in its privatized format, is visualized through PCA inverse such that both a human and machine inspector can evaluate the privatization and quantify the privacy-accuracy trade-off in an analysis on the privatized image database. Using the devised approach, we demonstrate the contextualization of DP in images by two use cases based on deep learning models, where we show the indistinguishability of individual images induced by DP and the privatized images' retention of statistical semantics in deep learning tasks, which is elaborated by quantitative analyses on the privacy-accuracy trade-off under different privatization settings.
Research on Dual Channel News Headline Classification Based on ERNIE Pre-training Model
Feb 14, 2022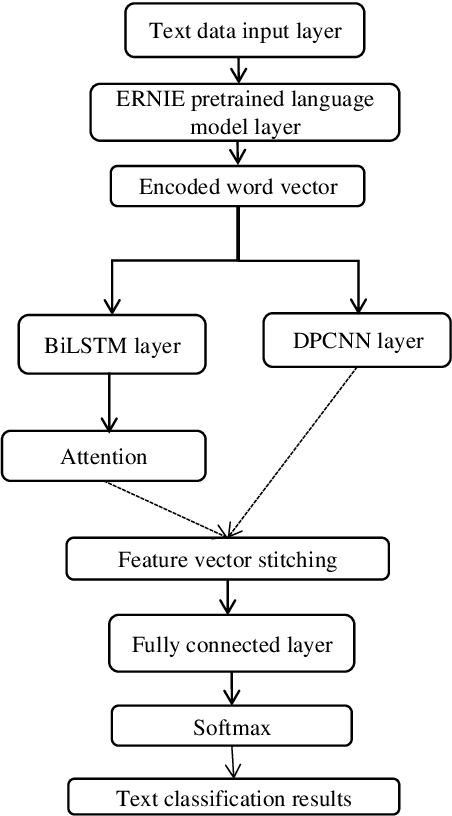
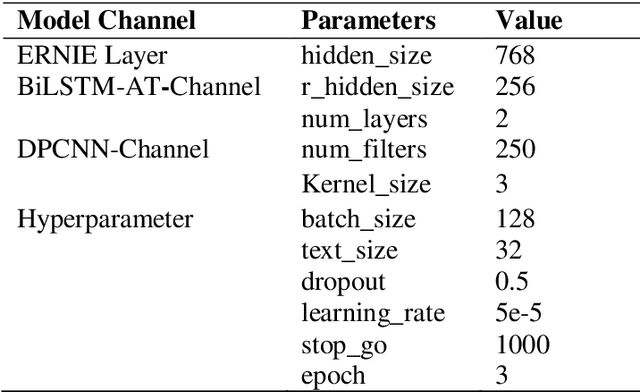
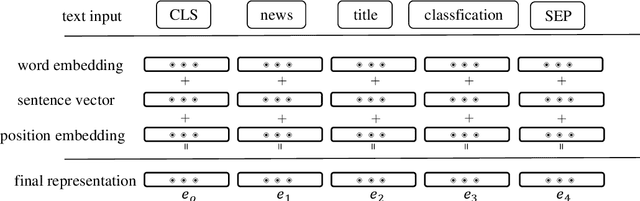
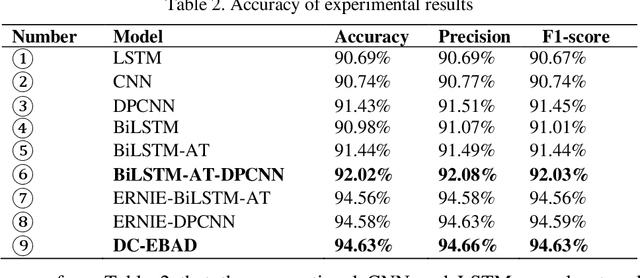
The classification of news headlines is an important direction in the field of NLP, and its data has the characteristics of compactness, uniqueness and various forms. Aiming at the problem that the traditional neural network model cannot adequately capture the underlying feature information of the data and cannot jointly extract key global features and deep local features, a dual-channel network model DC-EBAD based on the ERNIE pre-training model is proposed. Use ERNIE to extract the lexical, semantic and contextual feature information at the bottom of the text, generate dynamic word vector representations fused with context, and then use the BiLSTM-AT network channel to secondary extract the global features of the data and use the attention mechanism to give key parts higher The weight of the DPCNN channel is used to overcome the long-distance text dependence problem and obtain deep local features. The local and global feature vectors are spliced, and finally passed to the fully connected layer, and the final classification result is output through Softmax. The experimental results show that the proposed model improves the accuracy, precision and F1-score of news headline classification compared with the traditional neural network model and the single-channel model under the same conditions. It can be seen that it can perform well in the multi-classification application of news headline text under large data volume.
SN-Graph: a Minimalist 3D Object Representation for Classification
May 31, 2021
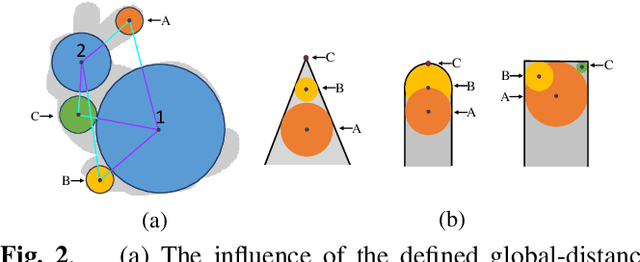
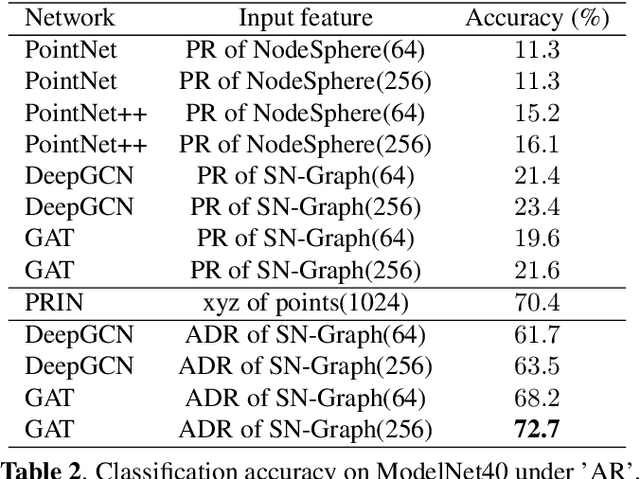
Using deep learning techniques to process 3D objects has achieved many successes. However, few methods focus on the representation of 3D objects, which could be more effective for specific tasks than traditional representations, such as point clouds, voxels, and multi-view images. In this paper, we propose a Sphere Node Graph (SN-Graph) to represent 3D objects. Specifically, we extract a certain number of internal spheres (as nodes) from the signed distance field (SDF), and then establish connections (as edges) among the sphere nodes to construct a graph, which is seamlessly suitable for 3D analysis using graph neural network (GNN). Experiments conducted on the ModelNet40 dataset show that when there are fewer nodes in the graph or the tested objects are rotated arbitrarily, the classification accuracy of SN-Graph is significantly higher than the state-of-the-art methods.
An Object Detection based Solver for Google's Image reCAPTCHA v2
Apr 07, 2021
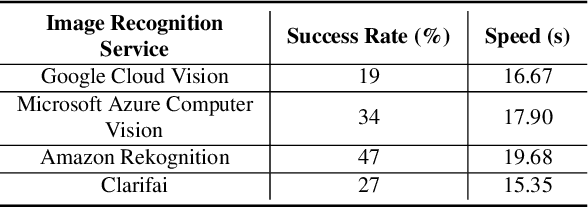
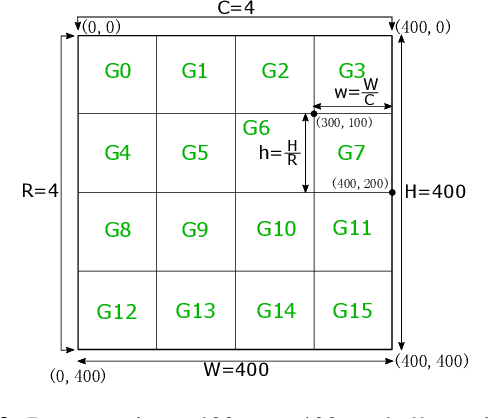
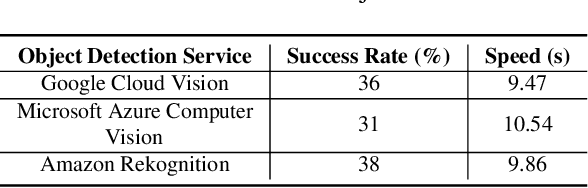
Previous work showed that reCAPTCHA v2's image challenges could be solved by automated programs armed with Deep Neural Network (DNN) image classifiers and vision APIs provided by off-the-shelf image recognition services. In response to emerging threats, Google has made significant updates to its image reCAPTCHA v2 challenges that can render the prior approaches ineffective to a great extent. In this paper, we investigate the robustness of the latest version of reCAPTCHA v2 against advanced object detection based solvers. We propose a fully automated object detection based system that breaks the most advanced challenges of reCAPTCHA v2 with an online success rate of 83.25%, the highest success rate to date, and it takes only 19.93 seconds (including network delays) on average to crack a challenge. We also study the updated security features of reCAPTCHA v2, such as anti-recognition mechanisms, improved anti-bot detection techniques, and adjustable security preferences. Our extensive experiments show that while these security features can provide some resistance against automated attacks, adversaries can still bypass most of them. Our experimental findings indicate that the recent advances in object detection technologies pose a severe threat to the security of image captcha designs relying on simple object detection as their underlying AI problem.
Spherical Transformer: Adapting Spherical Signal to CNNs
Jan 24, 2021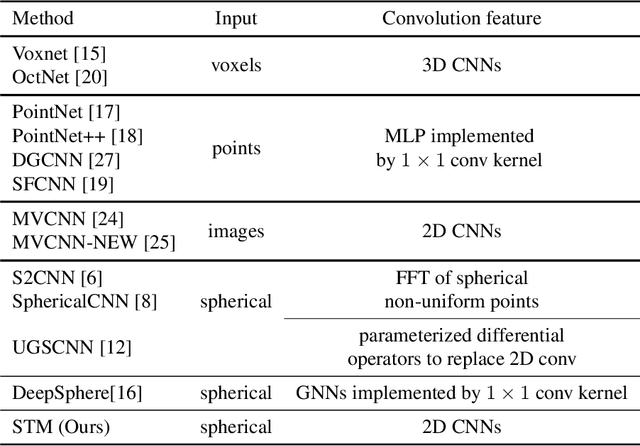
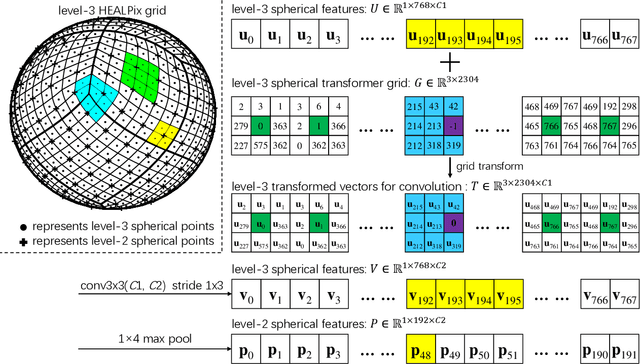
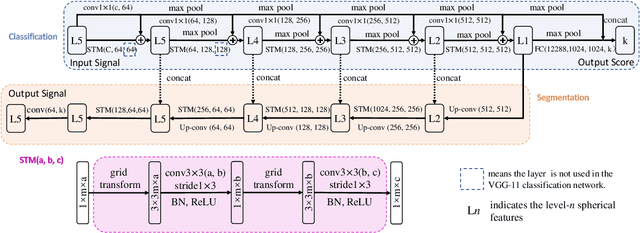
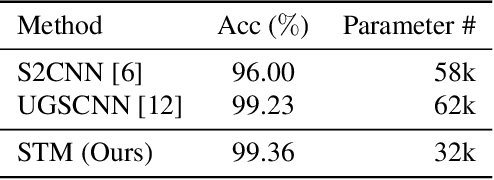
Convolutional neural networks (CNNs) have been widely used in various vision tasks, e.g. image classification, semantic segmentation, etc. Unfortunately, standard 2D CNNs are not well suited for spherical signals such as panorama images or spherical projections, as the sphere is an unstructured grid. In this paper, we present Spherical Transformer which can transform spherical signals into vectors that can be directly processed by standard CNNs such that many well-designed CNNs architectures can be reused across tasks and datasets by pretraining. To this end, the proposed method first uses locally structured sampling methods such as HEALPix to construct a transformer grid by using the information of spherical points and its adjacent points, and then transforms the spherical signals to the vectors through the grid. By building the Spherical Transformer module, we can use multiple CNN architectures directly. We evaluate our approach on the tasks of spherical MNIST recognition, 3D object classification and omnidirectional image semantic segmentation. For 3D object classification, we further propose a rendering-based projection method to improve the performance and a rotational-equivariant model to improve the anti-rotation ability. Experimental results on three tasks show that our approach achieves superior performance over state-of-the-art methods.
Fast Hybrid Cascade for Voxel-based 3D Object Classification
Nov 09, 2020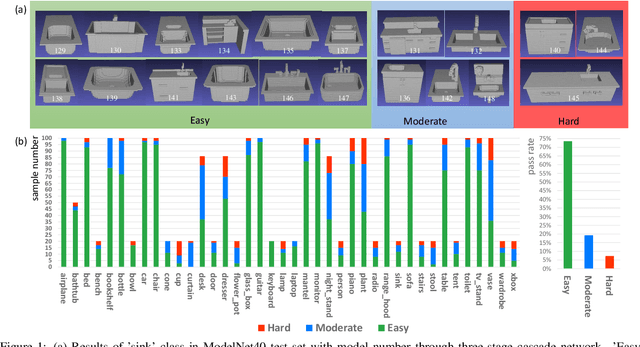
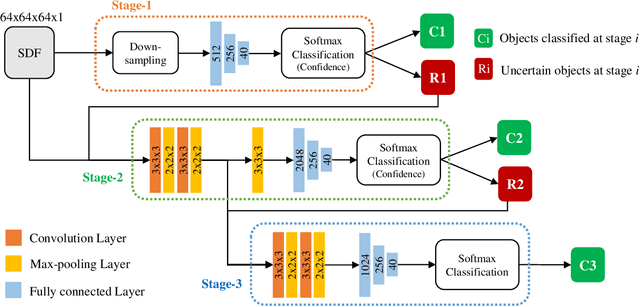

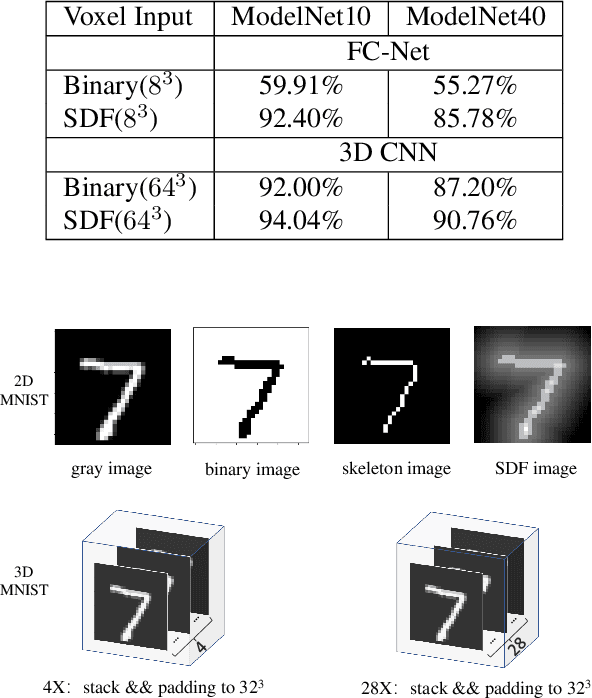
Voxel-based 3D object classification has been frequently studied in recent years. The previous methods often directly convert the classic 2D convolution into a 3D form applied to an object with binary voxel representation. In this paper, we investigate the reason why binary voxel representation is not very suitable for 3D convolution and how to simultaneously improve the performance both in accuracy and speed. We show that by giving each voxel a signed distance value, the accuracy will gain about 30% promotion compared with binary voxel representation using a two-layer fully connected network. We then propose a fast fully connected and convolution hybrid cascade network for voxel-based 3D object classification. This threestage cascade network can divide 3D models into three categories: easy, moderate and hard. Consequently, the mean inference time (0.3ms) can speedup about 5x and 2x compared with the state-of-the-art point cloud and voxel based methods respectively, while achieving the highest accuracy in the latter category of methods (92%). Experiments with ModelNet andMNIST verify the performance of the proposed hybrid cascade network.