 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSearch-Based LLMs for Code Optimization
Aug 22, 2024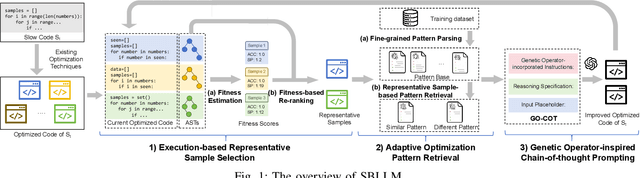



The code written by developers usually suffers from efficiency problems and contain various performance bugs. These inefficiencies necessitate the research of automated refactoring methods for code optimization. Early research in code optimization employs rule-based methods and focuses on specific inefficiency issues, which are labor-intensive and suffer from the low coverage issue. Recent work regards the task as a sequence generation problem, and resorts to deep learning (DL) techniques such as large language models (LLMs). These methods typically prompt LLMs to directly generate optimized code. Although these methods show state-of-the-art performance, such one-step generation paradigm is hard to achieve an optimal solution. First, complex optimization methods such as combinatorial ones are hard to be captured by LLMs. Second, the one-step generation paradigm poses challenge in precisely infusing the knowledge required for effective code optimization within LLMs, resulting in under-optimized code.To address these problems, we propose to model this task from the search perspective, and propose a search-based LLMs framework named SBLLM that enables iterative refinement and discovery of improved optimization methods. SBLLM synergistically integrate LLMs with evolutionary search and consists of three key components: 1) an execution-based representative sample selection part that evaluates the fitness of each existing optimized code and prioritizes promising ones to pilot the generation of improved code; 2) an adaptive optimization pattern retrieval part that infuses targeted optimization patterns into the model for guiding LLMs towards rectifying and progressively enhancing their optimization methods; and 3) a genetic operator-inspired chain-of-thought prompting part that aids LLMs in combining different optimization methods and generating improved optimization methods.
JIANG: Chinese Open Foundation Language Model
Aug 01, 2023


With the advancements in large language model technology, it has showcased capabilities that come close to those of human beings across various tasks. This achievement has garnered significant interest from companies and scientific research institutions, leading to substantial investments in the research and development of these models. While numerous large models have emerged during this period, the majority of them have been trained primarily on English data. Although they exhibit decent performance in other languages, such as Chinese, their potential remains limited due to factors like vocabulary design and training corpus. Consequently, their ability to fully express their capabilities in Chinese falls short. To address this issue, we introduce the model named JIANG (Chinese pinyin of ginger) specifically designed for the Chinese language. We have gathered a substantial amount of Chinese corpus to train the model and have also optimized its structure. The extensive experimental results demonstrate the excellent performance of our model.
Accelerating Code Search with Deep Hashing and Code Classification
Mar 31, 2022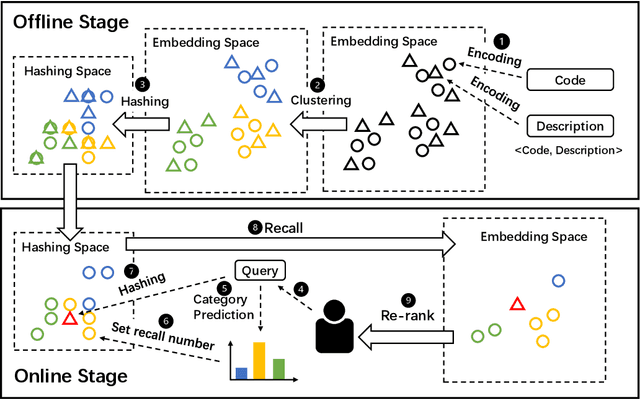
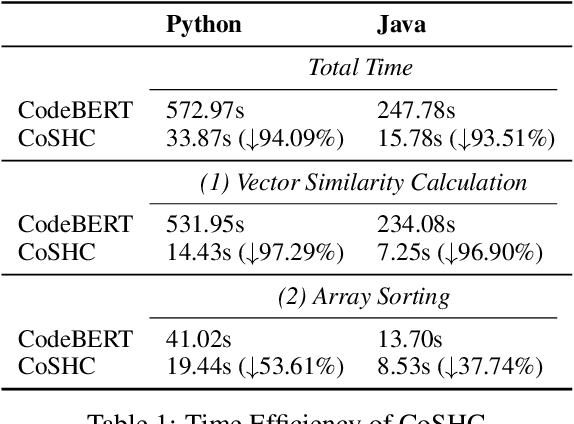
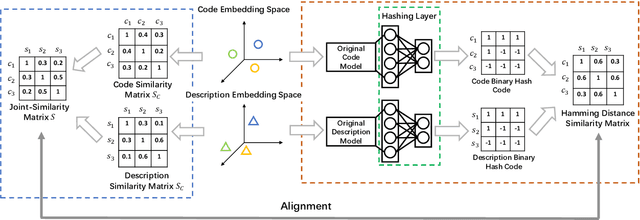
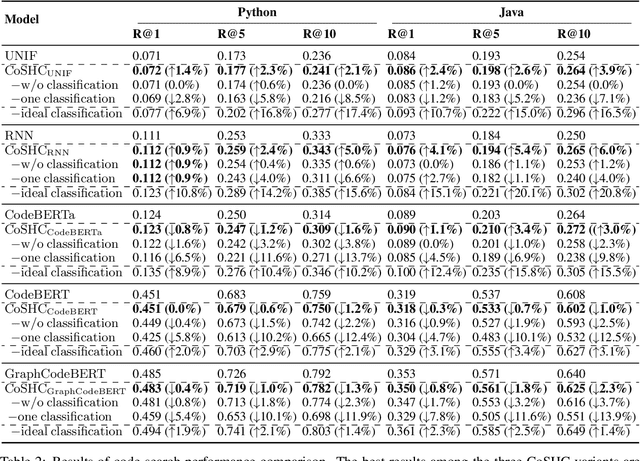
Code search is to search reusable code snippets from source code corpus based on natural languages queries. Deep learning-based methods of code search have shown promising results. However, previous methods focus on retrieval accuracy but lacked attention to the efficiency of the retrieval process. We propose a novel method CoSHC to accelerate code search with deep hashing and code classification, aiming to perform an efficient code search without sacrificing too much accuracy. To evaluate the effectiveness of CoSHC, we apply our method to five code search models. Extensive experimental results indicate that compared with previous code search baselines, CoSHC can save more than 90% of retrieval time meanwhile preserving at least 99% of retrieval accuracy.
Source Code Summarization with Structural Relative Position Guided Transformer
Feb 14, 2022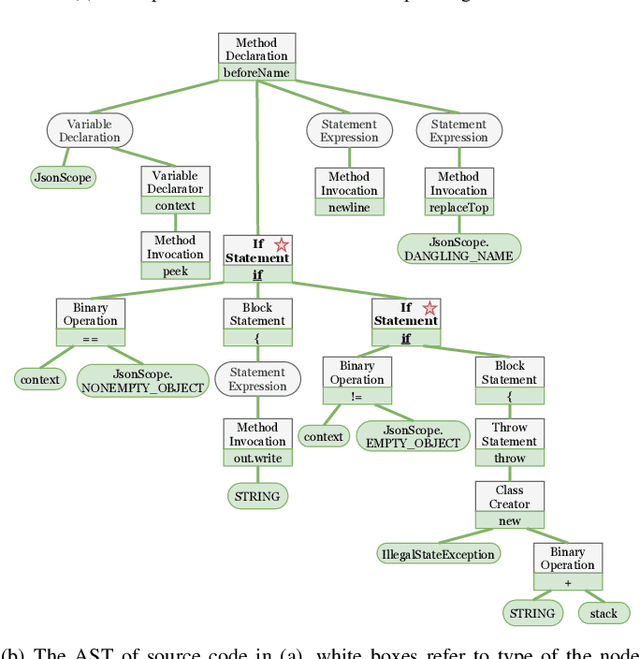
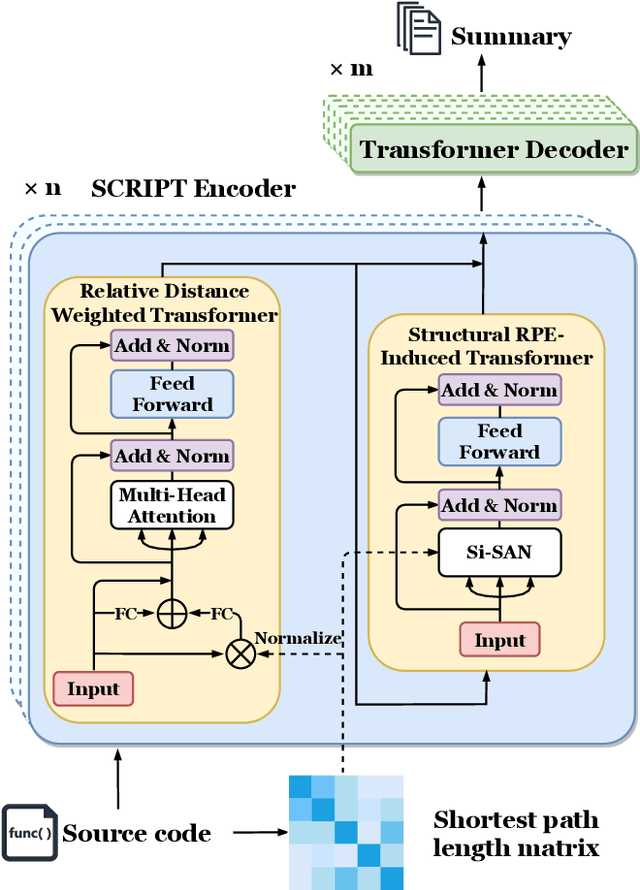
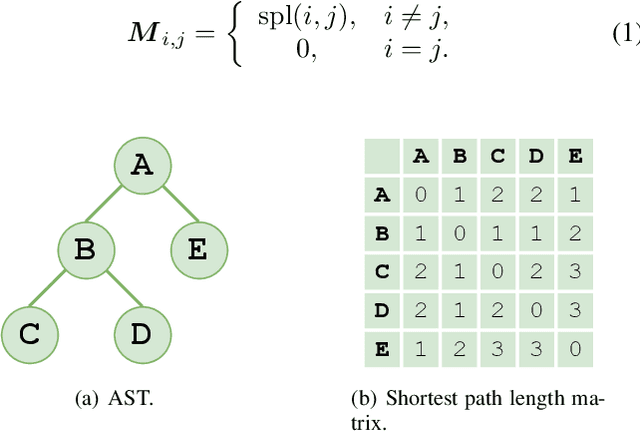
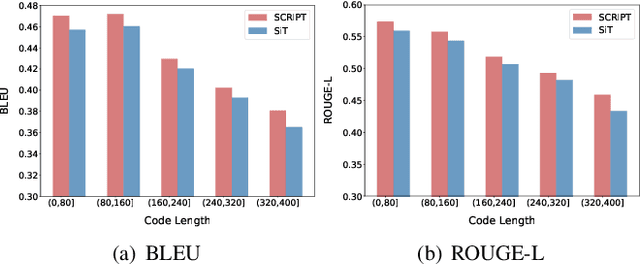
Source code summarization aims at generating concise and clear natural language descriptions for programming languages. Well-written code summaries are beneficial for programmers to participate in the software development and maintenance process. To learn the semantic representations of source code, recent efforts focus on incorporating the syntax structure of code into neural networks such as Transformer. Such Transformer-based approaches can better capture the long-range dependencies than other neural networks including Recurrent Neural Networks (RNNs), however, most of them do not consider the structural relative correlations between tokens, e.g., relative positions in Abstract Syntax Trees (ASTs), which is beneficial for code semantics learning. To model the structural dependency, we propose a Structural Relative Position guided Transformer, named SCRIPT. SCRIPT first obtains the structural relative positions between tokens via parsing the ASTs of source code, and then passes them into two types of Transformer encoders. One Transformer directly adjusts the input according to the structural relative distance; and the other Transformer encodes the structural relative positions during computing the self-attention scores. Finally, we stack these two types of Transformer encoders to learn representations of source code. Experimental results show that the proposed SCRIPT outperforms the state-of-the-art methods by at least 1.6%, 1.4% and 2.8% with respect to BLEU, ROUGE-L and METEOR on benchmark datasets, respectively. We further show that how the proposed SCRIPT captures the structural relative dependencies.