 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Prompt Alchemist: Automated LLM-Tailored Prompt Optimization for Test Case Generation
Jan 02, 2025



Test cases are essential for validating the reliability and quality of software applications. Recent studies have demonstrated the capability of Large Language Models (LLMs) to generate useful test cases for given source code. However, the existing work primarily relies on human-written plain prompts, which often leads to suboptimal results since the performance of LLMs can be highly influenced by the prompts. Moreover, these approaches use the same prompt for all LLMs, overlooking the fact that different LLMs might be best suited to different prompts. Given the wide variety of possible prompt formulations, automatically discovering the optimal prompt for each LLM presents a significant challenge. Although there are methods on automated prompt optimization in the natural language processing field, they are hard to produce effective prompts for the test case generation task. First, the methods iteratively optimize prompts by simply combining and mutating existing ones without proper guidance, resulting in prompts that lack diversity and tend to repeat the same errors in the generated test cases. Second, the prompts are generally lack of domain contextual knowledge, limiting LLMs' performance in the task.
Medchain: Bridging the Gap Between LLM Agents and Clinical Practice through Interactive Sequential Benchmarking
Dec 02, 2024



Clinical decision making (CDM) is a complex, dynamic process crucial to healthcare delivery, yet it remains a significant challenge for artificial intelligence systems. While Large Language Model (LLM)-based agents have been tested on general medical knowledge using licensing exams and knowledge question-answering tasks, their performance in the CDM in real-world scenarios is limited due to the lack of comprehensive testing datasets that mirror actual medical practice. To address this gap, we present MedChain, a dataset of 12,163 clinical cases that covers five key stages of clinical workflow. MedChain distinguishes itself from existing benchmarks with three key features of real-world clinical practice: personalization, interactivity, and sequentiality. Further, to tackle real-world CDM challenges, we also propose MedChain-Agent, an AI system that integrates a feedback mechanism and a MCase-RAG module to learn from previous cases and adapt its responses. MedChain-Agent demonstrates remarkable adaptability in gathering information dynamically and handling sequential clinical tasks, significantly outperforming existing approaches. The relevant dataset and code will be released upon acceptance of this paper.
Search-Based LLMs for Code Optimization
Aug 22, 2024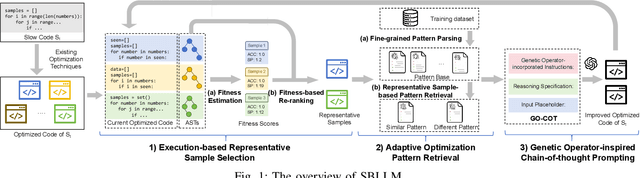



The code written by developers usually suffers from efficiency problems and contain various performance bugs. These inefficiencies necessitate the research of automated refactoring methods for code optimization. Early research in code optimization employs rule-based methods and focuses on specific inefficiency issues, which are labor-intensive and suffer from the low coverage issue. Recent work regards the task as a sequence generation problem, and resorts to deep learning (DL) techniques such as large language models (LLMs). These methods typically prompt LLMs to directly generate optimized code. Although these methods show state-of-the-art performance, such one-step generation paradigm is hard to achieve an optimal solution. First, complex optimization methods such as combinatorial ones are hard to be captured by LLMs. Second, the one-step generation paradigm poses challenge in precisely infusing the knowledge required for effective code optimization within LLMs, resulting in under-optimized code.To address these problems, we propose to model this task from the search perspective, and propose a search-based LLMs framework named SBLLM that enables iterative refinement and discovery of improved optimization methods. SBLLM synergistically integrate LLMs with evolutionary search and consists of three key components: 1) an execution-based representative sample selection part that evaluates the fitness of each existing optimized code and prioritizes promising ones to pilot the generation of improved code; 2) an adaptive optimization pattern retrieval part that infuses targeted optimization patterns into the model for guiding LLMs towards rectifying and progressively enhancing their optimization methods; and 3) a genetic operator-inspired chain-of-thought prompting part that aids LLMs in combining different optimization methods and generating improved optimization methods.
Performance Issue Identification in Cloud Systems with Relational-Temporal Anomaly Detection
Aug 01, 2023Performance issues permeate large-scale cloud service systems, which can lead to huge revenue losses. To ensure reliable performance, it's essential to accurately identify and localize these issues using service monitoring metrics. Given the complexity and scale of modern cloud systems, this task can be challenging and may require extensive expertise and resources beyond the capacity of individual humans. Some existing methods tackle this problem by analyzing each metric independently to detect anomalies. However, this could incur overwhelming alert storms that are difficult for engineers to diagnose manually. To pursue better performance, not only the temporal patterns of metrics but also the correlation between metrics (i.e., relational patterns) should be considered, which can be formulated as a multivariate metrics anomaly detection problem. However, most of the studies fall short of extracting these two types of features explicitly. Moreover, there exist some unlabeled anomalies mixed in the training data, which may hinder the detection performance. To address these limitations, we propose the Relational- Temporal Anomaly Detection Model (RTAnomaly) that combines the relational and temporal information of metrics. RTAnomaly employs a graph attention layer to learn the dependencies among metrics, which will further help pinpoint the anomalous metrics that may cause the anomaly effectively. In addition, we exploit the concept of positive unlabeled learning to address the issue of potential anomalies in the training data. To evaluate our method, we conduct experiments on a public dataset and two industrial datasets. RTAnomaly outperforms all the baseline models by achieving an average F1 score of 0.929 and Hit@3 of 0.920, demonstrating its superiority.
Validating Multimedia Content Moderation Software via Semantic Fusion
May 23, 2023The exponential growth of social media platforms, such as Facebook and TikTok, has revolutionized communication and content publication in human society. Users on these platforms can publish multimedia content that delivers information via the combination of text, audio, images, and video. Meanwhile, the multimedia content release facility has been increasingly exploited to propagate toxic content, such as hate speech, malicious advertisements, and pornography. To this end, content moderation software has been widely deployed on these platforms to detect and blocks toxic content. However, due to the complexity of content moderation models and the difficulty of understanding information across multiple modalities, existing content moderation software can fail to detect toxic content, which often leads to extremely negative impacts. We introduce Semantic Fusion, a general, effective methodology for validating multimedia content moderation software. Our key idea is to fuse two or more existing single-modal inputs (e.g., a textual sentence and an image) into a new input that combines the semantics of its ancestors in a novel manner and has toxic nature by construction. This fused input is then used for validating multimedia content moderation software. We realized Semantic Fusion as DUO, a practical content moderation software testing tool. In our evaluation, we employ DUO to test five commercial content moderation software and two state-of-the-art models against three kinds of toxic content. The results show that DUO achieves up to 100% error finding rate (EFR) when testing moderation software. In addition, we leverage the test cases generated by DUO to retrain the two models we explored, which largely improves model robustness while maintaining the accuracy on the original test set.
BiasAsker: Measuring the Bias in Conversational AI System
May 21, 2023Powered by advanced Artificial Intelligence (AI) techniques, conversational AI systems, such as ChatGPT and digital assistants like Siri, have been widely deployed in daily life. However, such systems may still produce content containing biases and stereotypes, causing potential social problems. Due to the data-driven, black-box nature of modern AI techniques, comprehensively identifying and measuring biases in conversational systems remains a challenging task. Particularly, it is hard to generate inputs that can comprehensively trigger potential bias due to the lack of data containing both social groups as well as biased properties. In addition, modern conversational systems can produce diverse responses (e.g., chatting and explanation), which makes existing bias detection methods simply based on the sentiment and the toxicity hardly being adopted. In this paper, we propose BiasAsker, an automated framework to identify and measure social bias in conversational AI systems. To obtain social groups and biased properties, we construct a comprehensive social bias dataset, containing a total of 841 groups and 8,110 biased properties. Given the dataset, BiasAsker automatically generates questions and adopts a novel method based on existence measurement to identify two types of biases (i.e., absolute bias and related bias) in conversational systems. Extensive experiments on 8 commercial systems and 2 famous research models, such as ChatGPT and GPT-3, show that 32.83% of the questions generated by BiasAsker can trigger biased behaviors in these widely deployed conversational systems. All the code, data, and experimental results have been released to facilitate future research.
ChatGPT or Grammarly? Evaluating ChatGPT on Grammatical Error Correction Benchmark
Mar 15, 2023



ChatGPT is a cutting-edge artificial intelligence language model developed by OpenAI, which has attracted a lot of attention due to its surprisingly strong ability in answering follow-up questions. In this report, we aim to evaluate ChatGPT on the Grammatical Error Correction(GEC) task, and compare it with commercial GEC product (e.g., Grammarly) and state-of-the-art models (e.g., GECToR). By testing on the CoNLL2014 benchmark dataset, we find that ChatGPT performs not as well as those baselines in terms of the automatic evaluation metrics (e.g., $F_{0.5}$ score), particularly on long sentences. We inspect the outputs and find that ChatGPT goes beyond one-by-one corrections. Specifically, it prefers to change the surface expression of certain phrases or sentence structure while maintaining grammatical correctness. Human evaluation quantitatively confirms this and suggests that ChatGPT produces less under-correction or mis-correction issues but more over-corrections. These results demonstrate that ChatGPT is severely under-estimated by the automatic evaluation metrics and could be a promising tool for GEC.
MTTM: Metamorphic Testing for Textual Content Moderation Software
Feb 11, 2023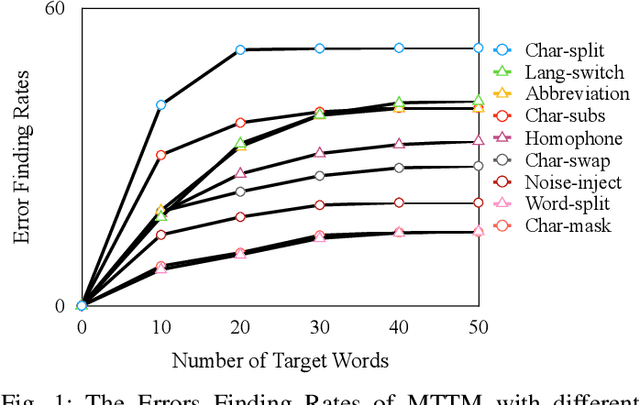
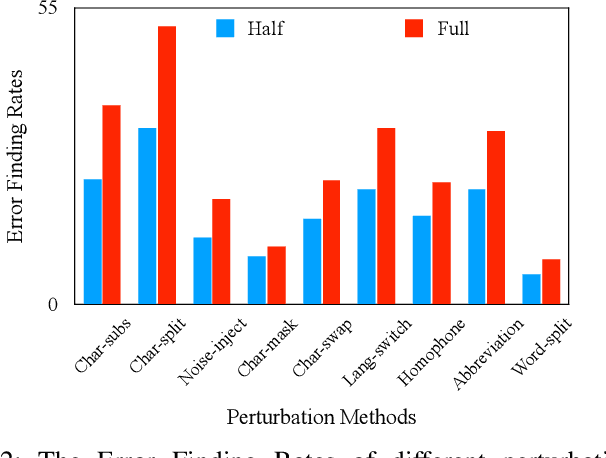
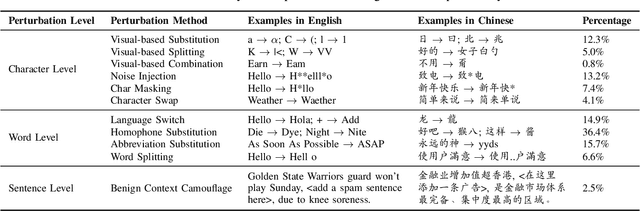
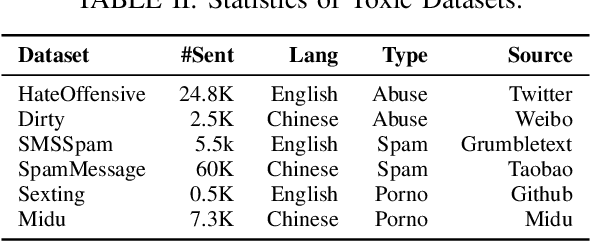
The exponential growth of social media platforms such as Twitter and Facebook has revolutionized textual communication and textual content publication in human society. However, they have been increasingly exploited to propagate toxic content, such as hate speech, malicious advertisement, and pornography, which can lead to highly negative impacts (e.g., harmful effects on teen mental health). Researchers and practitioners have been enthusiastically developing and extensively deploying textual content moderation software to address this problem. However, we find that malicious users can evade moderation by changing only a few words in the toxic content. Moreover, modern content moderation software performance against malicious inputs remains underexplored. To this end, we propose MTTM, a Metamorphic Testing framework for Textual content Moderation software. Specifically, we conduct a pilot study on 2,000 text messages collected from real users and summarize eleven metamorphic relations across three perturbation levels: character, word, and sentence. MTTM employs these metamorphic relations on toxic textual contents to generate test cases, which are still toxic yet likely to evade moderation. In our evaluation, we employ MTTM to test three commercial textual content moderation software and two state-of-the-art moderation algorithms against three kinds of toxic content. The results show that MTTM achieves up to 83.9%, 51%, and 82.5% error finding rates (EFR) when testing commercial moderation software provided by Google, Baidu, and Huawei, respectively, and it obtains up to 91.2% EFR when testing the state-of-the-art algorithms from the academy. In addition, we leverage the test cases generated by MTTM to retrain the model we explored, which largely improves model robustness (0% to 5.9% EFR) while maintaining the accuracy on the original test set.
Understanding and Improving Sequence-to-Sequence Pretraining for Neural Machine Translation
Mar 16, 2022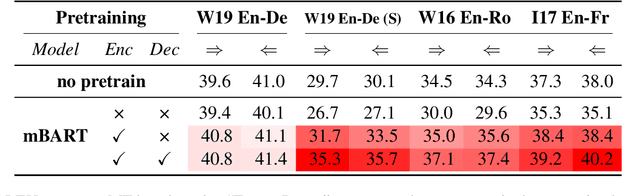
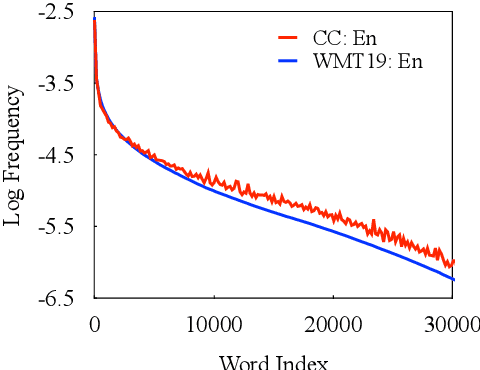

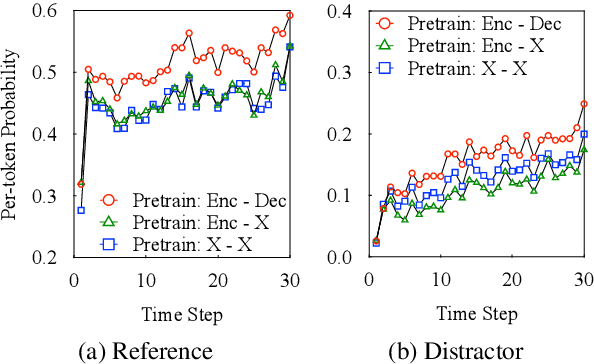
In this paper, we present a substantial step in better understanding the SOTA sequence-to-sequence (Seq2Seq) pretraining for neural machine translation~(NMT). We focus on studying the impact of the jointly pretrained decoder, which is the main difference between Seq2Seq pretraining and previous encoder-based pretraining approaches for NMT. By carefully designing experiments on three language pairs, we find that Seq2Seq pretraining is a double-edged sword: On one hand, it helps NMT models to produce more diverse translations and reduce adequacy-related translation errors. On the other hand, the discrepancies between Seq2Seq pretraining and NMT finetuning limit the translation quality (i.e., domain discrepancy) and induce the over-estimation issue (i.e., objective discrepancy). Based on these observations, we further propose simple and effective strategies, named in-domain pretraining and input adaptation to remedy the domain and objective discrepancies, respectively. Experimental results on several language pairs show that our approach can consistently improve both translation performance and model robustness upon Seq2Seq pretraining.
Discrete Auto-regressive Variational Attention Models for Text Modeling
Jun 16, 2021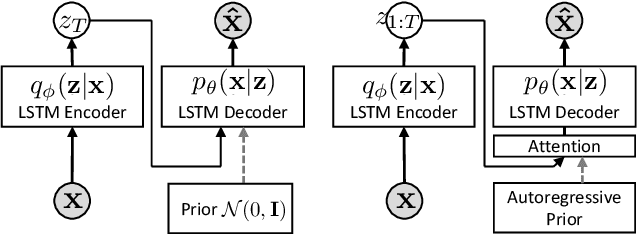

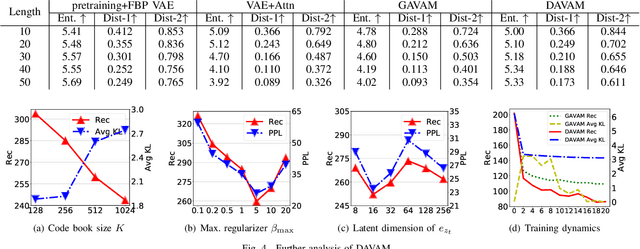

Variational autoencoders (VAEs) have been widely applied for text modeling. In practice, however, they are troubled by two challenges: information underrepresentation and posterior collapse. The former arises as only the last hidden state of LSTM encoder is transformed into the latent space, which is generally insufficient to summarize the data. The latter is a long-standing problem during the training of VAEs as the optimization is trapped to a disastrous local optimum. In this paper, we propose Discrete Auto-regressive Variational Attention Model (DAVAM) to address the challenges. Specifically, we introduce an auto-regressive variational attention approach to enrich the latent space by effectively capturing the semantic dependency from the input. We further design discrete latent space for the variational attention and mathematically show that our model is free from posterior collapse. Extensive experiments on language modeling tasks demonstrate the superiority of DAVAM against several VAE counterparts.