 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRuntime Failure Hunting for Physics Engine Based Software Systems: How Far Can We Go?
Jul 29, 2025Physics Engines (PEs) are fundamental software frameworks that simulate physical interactions in applications ranging from entertainment to safety-critical systems. Despite their importance, PEs suffer from physics failures, deviations from expected physical behaviors that can compromise software reliability, degrade user experience, and potentially cause critical failures in autonomous vehicles or medical robotics. Current testing approaches for PE-based software are inadequate, typically requiring white-box access and focusing on crash detection rather than semantically complex physics failures. This paper presents the first large-scale empirical study characterizing physics failures in PE-based software. We investigate three research questions addressing the manifestations of physics failures, the effectiveness of detection techniques, and developer perceptions of current detection practices. Our contributions include: (1) a taxonomy of physics failure manifestations; (2) a comprehensive evaluation of detection methods including deep learning, prompt-based techniques, and large multimodal models; and (3) actionable insights from developer experiences for improving detection approaches. To support future research, we release PhysiXFails, code, and other materials at https://sites.google.com/view/physics-failure-detection.
3D Software Synthesis Guided by Constraint-Expressive Intermediate Representation
Jul 24, 2025Graphical user interface (UI) software has undergone a fundamental transformation from traditional two-dimensional (2D) desktop/web/mobile interfaces to spatial three-dimensional (3D) environments. While existing work has made remarkable success in automated 2D software generation, such as HTML/CSS and mobile app interface code synthesis, the generation of 3D software still remains under-explored. Current methods for 3D software generation usually generate the 3D environments as a whole and cannot modify or control specific elements in the software. Furthermore, these methods struggle to handle the complex spatial and semantic constraints inherent in the real world. To address the challenges, we present Scenethesis, a novel requirement-sensitive 3D software synthesis approach that maintains formal traceability between user specifications and generated 3D software. Scenethesis is built upon ScenethesisLang, a domain-specific language that serves as a granular constraint-aware intermediate representation (IR) to bridge natural language requirements and executable 3D software. It serves both as a comprehensive scene description language enabling fine-grained modification of 3D software elements and as a formal constraint-expressive specification language capable of expressing complex spatial constraints. By decomposing 3D software synthesis into stages operating on ScenethesisLang, Scenethesis enables independent verification, targeted modification, and systematic constraint satisfaction. Our evaluation demonstrates that Scenethesis accurately captures over 80% of user requirements and satisfies more than 90% of hard constraints while handling over 100 constraints simultaneously. Furthermore, Scenethesis achieves a 42.8% improvement in BLIP-2 visual evaluation scores compared to the state-of-the-art method.
How Should I Build A Benchmark?
Jan 18, 2025Various benchmarks have been proposed to assess the performance of large language models (LLMs) in different coding scenarios. We refer to them as code-related benchmarks. However, there are no systematic guidelines by which such a benchmark should be developed to ensure its quality, reliability, and reproducibility. We propose How2Bench, which is comprised of a 55- 55-criteria checklist as a set of guidelines to govern the development of code-related benchmarks comprehensively. Using HOW2BENCH, we profiled 274 benchmarks released within the past decade and found concerning issues. Nearly 70% of the benchmarks did not take measures for data quality assurance; over 10% did not even open source or only partially open source. Many highly cited benchmarks have loopholes, including duplicated samples, incorrect reference codes/tests/prompts, and unremoved sensitive/confidential information. Finally, we conducted a human study involving 49 participants, which revealed significant gaps in awareness of the importance of data quality, reproducibility, and transparency.
XRZoo: A Large-Scale and Versatile Dataset of Extended Reality (XR) Applications
Dec 10, 2024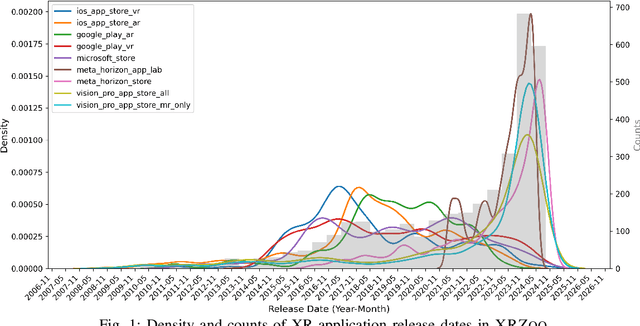
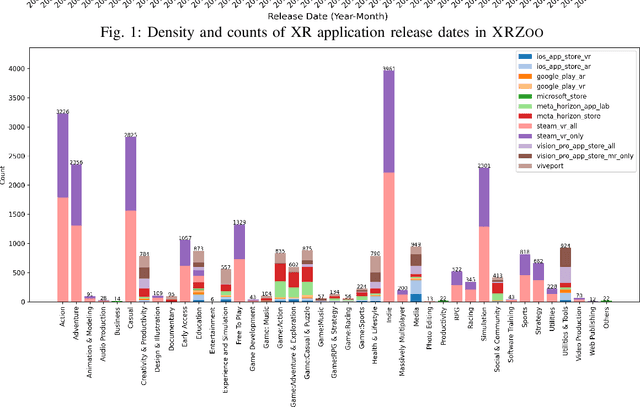
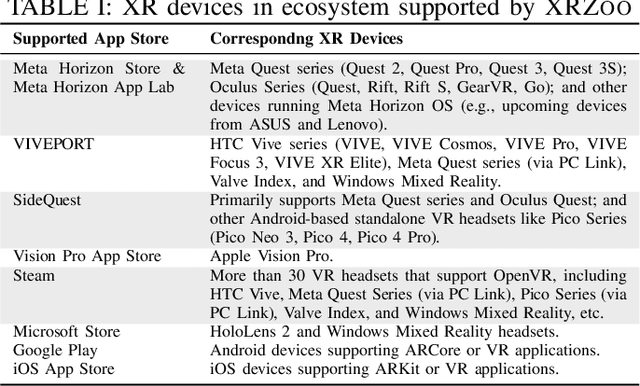
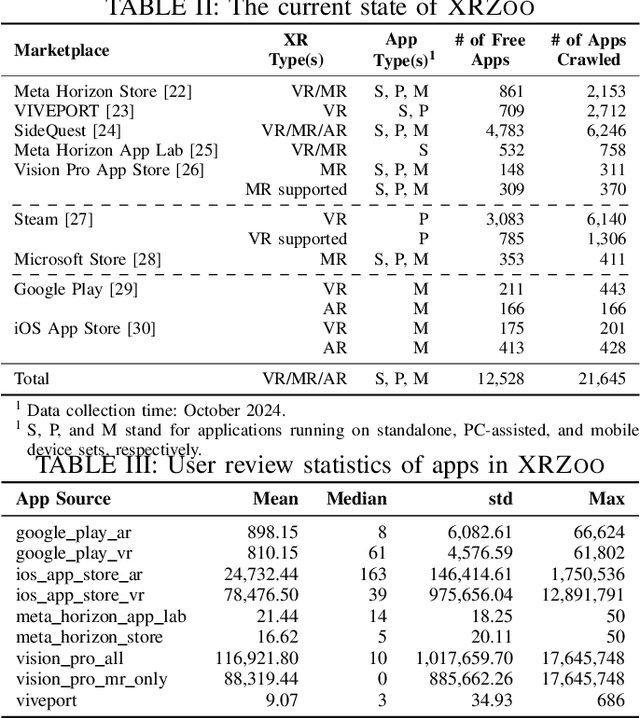
The rapid advancement of Extended Reality (XR, encompassing AR, MR, and VR) and spatial computing technologies forms a foundational layer for the emerging Metaverse, enabling innovative applications across healthcare, education, manufacturing, and entertainment. However, research in this area is often limited by the lack of large, representative, and highquality application datasets that can support empirical studies and the development of new approaches benefiting XR software processes. In this paper, we introduce XRZoo, a comprehensive and curated dataset of XR applications designed to bridge this gap. XRZoo contains 12,528 free XR applications, spanning nine app stores, across all XR techniques (i.e., AR, MR, and VR) and use cases, with detailed metadata on key aspects such as application descriptions, application categories, release dates, user review numbers, and hardware specifications, etc. By making XRZoo publicly available, we aim to foster reproducible XR software engineering and security research, enable cross-disciplinary investigations, and also support the development of advanced XR systems by providing examples to developers. Our dataset serves as a valuable resource for researchers and practitioners interested in improving the scalability, usability, and effectiveness of XR applications. XRZoo will be released and actively maintained.
Automatically Generating UI Code from Screenshot: A Divide-and-Conquer-Based Approach
Jun 24, 2024



Websites are critical in today's digital world, with over 1.11 billion currently active and approximately 252,000 new sites launched daily. Converting website layout design into functional UI code is a time-consuming yet indispensable step of website development. Manual methods of converting visual designs into functional code present significant challenges, especially for non-experts. To explore automatic design-to-code solutions, we first conduct a motivating study on GPT-4o and identify three types of issues in generating UI code: element omission, element distortion, and element misarrangement. We further reveal that a focus on smaller visual segments can help multimodal large language models (MLLMs) mitigate these failures in the generation process. In this paper, we propose DCGen, a divide-and-conquer-based approach to automate the translation of webpage design to UI code. DCGen starts by dividing screenshots into manageable segments, generating descriptions for each segment, and then reassembling them into complete UI code for the entire screenshot. We conduct extensive testing with a dataset comprised of real-world websites and various MLLMs and demonstrate that DCGen achieves up to a 14% improvement in visual similarity over competing methods. To the best of our knowledge, DCGen is the first segment-aware prompt-based approach for generating UI code directly from screenshots.
MTTM: Metamorphic Testing for Textual Content Moderation Software
Feb 11, 2023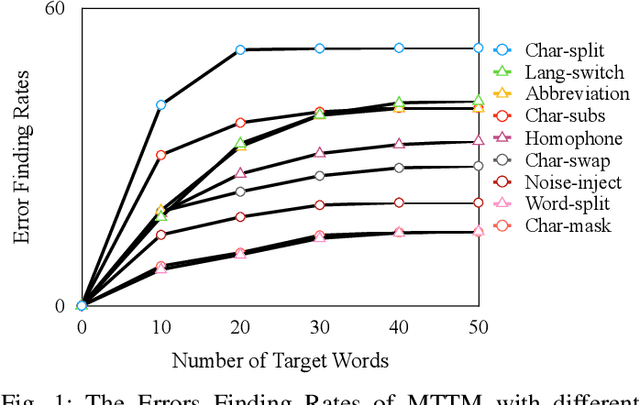
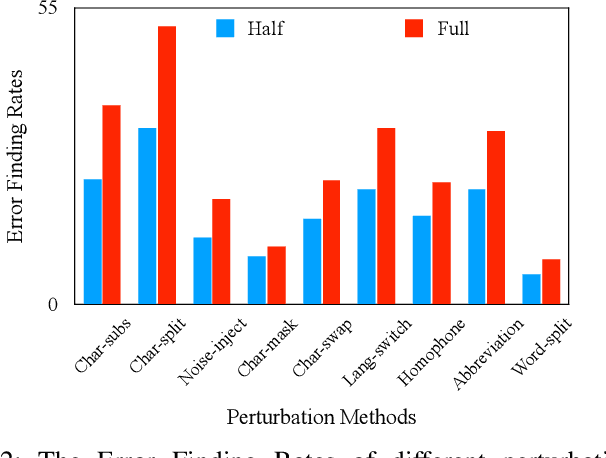
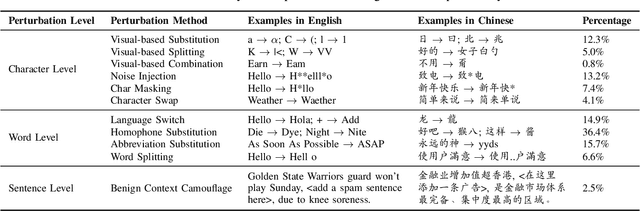
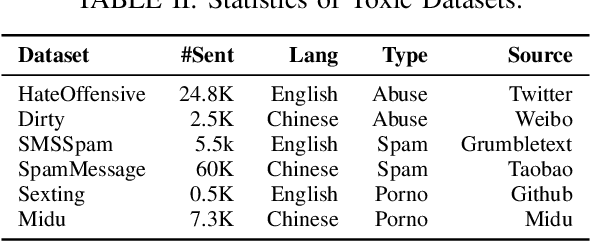
The exponential growth of social media platforms such as Twitter and Facebook has revolutionized textual communication and textual content publication in human society. However, they have been increasingly exploited to propagate toxic content, such as hate speech, malicious advertisement, and pornography, which can lead to highly negative impacts (e.g., harmful effects on teen mental health). Researchers and practitioners have been enthusiastically developing and extensively deploying textual content moderation software to address this problem. However, we find that malicious users can evade moderation by changing only a few words in the toxic content. Moreover, modern content moderation software performance against malicious inputs remains underexplored. To this end, we propose MTTM, a Metamorphic Testing framework for Textual content Moderation software. Specifically, we conduct a pilot study on 2,000 text messages collected from real users and summarize eleven metamorphic relations across three perturbation levels: character, word, and sentence. MTTM employs these metamorphic relations on toxic textual contents to generate test cases, which are still toxic yet likely to evade moderation. In our evaluation, we employ MTTM to test three commercial textual content moderation software and two state-of-the-art moderation algorithms against three kinds of toxic content. The results show that MTTM achieves up to 83.9%, 51%, and 82.5% error finding rates (EFR) when testing commercial moderation software provided by Google, Baidu, and Huawei, respectively, and it obtains up to 91.2% EFR when testing the state-of-the-art algorithms from the academy. In addition, we leverage the test cases generated by MTTM to retrain the model we explored, which largely improves model robustness (0% to 5.9% EFR) while maintaining the accuracy on the original test set.
Temporal Collaborative Ranking Via Personalized Transformer
Aug 15, 2019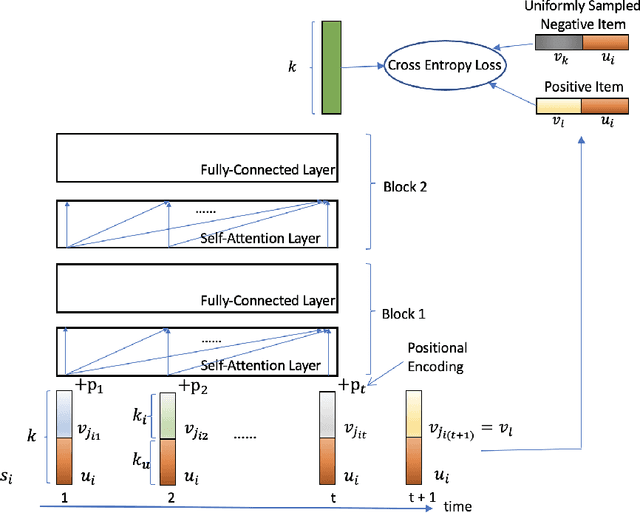
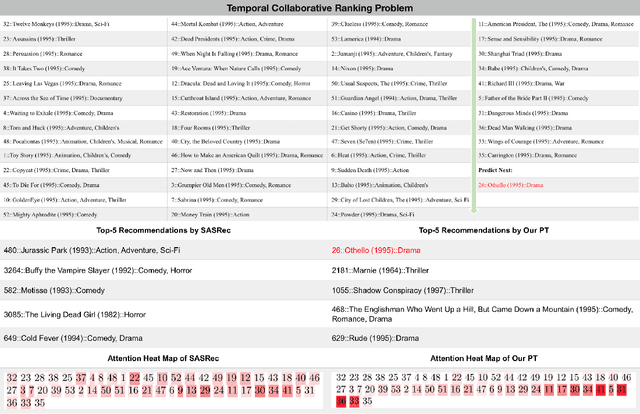

The collaborative ranking problem has been an important open research question as most recommendation problems can be naturally formulated as ranking problems. While much of collaborative ranking methodology assumes static ranking data, the importance of temporal information to improving ranking performance is increasingly apparent. Recent advances in deep learning, especially the discovery of various attention mechanisms and newer architectures in addition to widely used RNN and CNN in natural language processing, have allowed us to make better use of the temporal ordering of items that each user has engaged with. In particular, the SASRec model, inspired by the popular Transformer model in natural languages processing, has achieved state-of-art results in the temporal collaborative ranking problem and enjoyed more than 10x speed-up when compared to earlier CNN/RNN-based methods. However, SASRec is inherently an un-personalized model and does not include personalized user embeddings. To overcome this limitation, we propose a Personalized Transformer (SSE-PT) model, outperforming SASRec by almost 5% in terms of NDCG@10 on 5 real-world datasets. Furthermore, after examining some random users' engagement history and corresponding attention heat maps used during the inference stage, we find our model is not only more interpretable but also able to focus on recent engagement patterns for each user. Moreover, our SSE-PT model with a slight modification, which we call SSE-PT++, can handle extremely long sequences and outperform SASRec in ranking results with comparable training speed, striking a balance between performance and speed requirements. Code and data are open sourced at https://github.com/wuliwei9278/SSE-PT.
Stochastic Shared Embeddings: Data-driven Regularization of Embedding Layers
May 25, 2019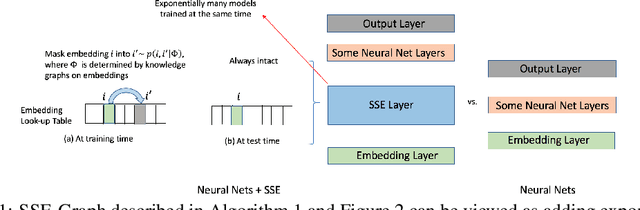

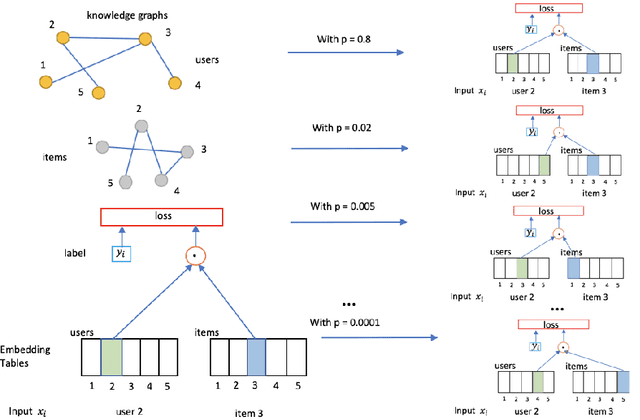
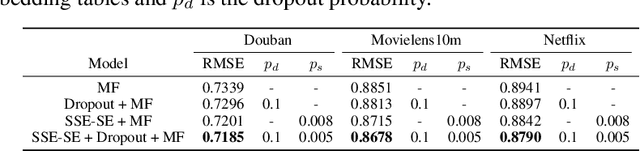
In deep neural nets, lower level embedding layers account for a large portion of the total number of parameters. Tikhonov regularization, graph-based regularization, and hard parameter sharing are approaches that introduce explicit biases into training in a hope to reduce statistical complexity. Alternatively, we propose stochastically shared embeddings (SSE), a data-driven approach to regularizing embedding layers, which stochastically transitions between embeddings during stochastic gradient descent (SGD). Because SSE integrates seamlessly with existing SGD algorithms, it can be used with only minor modifications when training large scale neural networks. We develop two versions of SSE: SSE-Graph using knowledge graphs of embeddings; SSE-SE using no prior information. We provide theoretical guarantees for our method and show its empirical effectiveness on 6 distinct tasks, from simple neural networks with one hidden layer in recommender systems, to the transformer and BERT in natural languages. We find that when used along with widely-used regularization methods such as weight decay and dropout, our proposed SSE can further reduce overfitting, which often leads to more favorable generalization results.