 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAXIOM: Benchmarking LLM-as-a-Judge for Code via Rule-Based Perturbation and Multisource Quality Calibration
Dec 23, 2025Large language models (LLMs) have been increasingly deployed in real-world software engineering, fostering the development of code evaluation metrics to study the quality of LLM-generated code. Conventional rule-based metrics merely score programs based on their surface-level similarities with reference programs instead of analyzing functionality and code quality in depth. To address this limitation, researchers have developed LLM-as-a-judge metrics, prompting LLMs to evaluate and score code, and curated various code evaluation benchmarks to validate their effectiveness. However, these benchmarks suffer from critical limitations, hindering reliable assessments of evaluation capability: Some feature coarse-grained binary labels, which reduce rich code behavior to a single bit of information, obscuring subtle errors. Others propose fine-grained but subjective, vaguely-defined evaluation criteria, introducing unreliability in manually-annotated scores, which is the ground-truth they rely on. Furthermore, they often use uncontrolled data synthesis methods, leading to unbalanced score distributions that poorly represent real-world code generation scenarios. To curate a diverse benchmark with programs of well-balanced distributions across various quality levels and streamline the manual annotation procedure, we propose AXIOM, a novel perturbation-based framework for synthesizing code evaluation benchmarks at scale. It reframes program scores as the refinement effort needed for deployment, consisting of two stages: (1) Rule-guided perturbation, which prompts LLMs to apply sequences of predefined perturbation rules to existing high-quality programs to modify their functionality and code quality, enabling us to precisely control each program's target score to achieve balanced score distributions. (2) Multisource quality calibration, which first selects a subset of...
Benchmarking LLMs for Fine-Grained Code Review with Enriched Context in Practice
Nov 10, 2025



Code review is a cornerstone of software quality assurance, and recent advances in Large Language Models (LLMs) have shown promise in automating this process. However, existing benchmarks for LLM-based code review face three major limitations. (1) Lack of semantic context: most benchmarks provide only code diffs without textual information such as issue descriptions, which are crucial for understanding developer intent. (2) Data quality issues: without rigorous validation, many samples are noisy-e.g., reviews on outdated or irrelevant code-reducing evaluation reliability. (3) Coarse granularity: most benchmarks operate at the file or commit level, overlooking the fine-grained, line-level reasoning essential for precise review. We introduce ContextCRBench, a high-quality, context-rich benchmark for fine-grained LLM evaluation in code review. Our construction pipeline comprises: (1) Raw Data Crawling, collecting 153.7K issues and pull requests from top-tier repositories; (2) Comprehensive Context Extraction, linking issue-PR pairs for textual context and extracting the full surrounding function or class for code context; and (3) Multi-stage Data Filtering, combining rule-based and LLM-based validation to remove outdated, malformed, or low-value samples, resulting in 67,910 context-enriched entries. ContextCRBench supports three evaluation scenarios aligned with the review workflow: (1) hunk-level quality assessment, (2) line-level defect localization, and (3) line-level comment generation. Evaluating eight leading LLMs (four closed-source and four open-source) reveals that textual context yields greater performance gains than code context alone, while current LLMs remain far from human-level review ability. Deployed at ByteDance, ContextCRBench drives a self-evolving code review system, improving performance by 61.98% and demonstrating its robustness and industrial utility.
Boosting Vulnerability Detection of LLMs via Curriculum Preference Optimization with Synthetic Reasoning Data
Jun 09, 2025



Large language models (LLMs) demonstrate considerable proficiency in numerous coding-related tasks; however, their capabilities in detecting software vulnerabilities remain limited. This limitation primarily stems from two factors: (1) the absence of reasoning data related to vulnerabilities, which hinders the models' ability to capture underlying vulnerability patterns; and (2) their focus on learning semantic representations rather than the reason behind them, thus failing to recognize semantically similar vulnerability samples. Furthermore, the development of LLMs specialized in vulnerability detection is challenging, particularly in environments characterized by the scarcity of high-quality datasets. In this paper, we propose a novel framework ReVD that excels at mining vulnerability patterns through reasoning data synthesizing and vulnerability-specific preference optimization. Specifically, we construct forward and backward reasoning processes for vulnerability and corresponding fixed code, ensuring the synthesis of high-quality reasoning data. Moreover, we design the triplet supervised fine-tuning followed by curriculum online preference optimization for enabling ReVD to better understand vulnerability patterns. The extensive experiments conducted on PrimeVul and SVEN datasets demonstrate that ReVD sets new state-of-the-art for LLM-based software vulnerability detection, e.g., 12.24\%-22.77\% improvement in the accuracy. The source code and data are available at https://github.com/Xin-Cheng-Wen/PO4Vul.
Exploring the Landscape of Text-to-SQL with Large Language Models: Progresses, Challenges and Opportunities
May 28, 2025



Converting natural language (NL) questions into SQL queries, referred to as Text-to-SQL, has emerged as a pivotal technology for facilitating access to relational databases, especially for users without SQL knowledge. Recent progress in large language models (LLMs) has markedly propelled the field of natural language processing (NLP), opening new avenues to improve text-to-SQL systems. This study presents a systematic review of LLM-based text-to-SQL, focusing on four key aspects: (1) an analysis of the research trends in LLM-based text-to-SQL; (2) an in-depth analysis of existing LLM-based text-to-SQL techniques from diverse perspectives; (3) summarization of existing text-to-SQL datasets and evaluation metrics; and (4) discussion on potential obstacles and avenues for future exploration in this domain. This survey seeks to furnish researchers with an in-depth understanding of LLM-based text-to-SQL, sparking new innovations and advancements in this field.
LFTF: Locating First and Then Fine-Tuning for Mitigating Gender Bias in Large Language Models
May 21, 2025Nowadays, Large Language Models (LLMs) have attracted widespread attention due to their powerful performance. However, due to the unavoidable exposure to socially biased data during training, LLMs tend to exhibit social biases, particularly gender bias. To better explore and quantifying the degree of gender bias in LLMs, we propose a pair of datasets named GenBiasEval and GenHintEval, respectively. The GenBiasEval is responsible for evaluating the degree of gender bias in LLMs, accompanied by an evaluation metric named AFGB-Score (Absolutely Fair Gender Bias Score). Meanwhile, the GenHintEval is used to assess whether LLMs can provide responses consistent with prompts that contain gender hints, along with the accompanying evaluation metric UB-Score (UnBias Score). Besides, in order to mitigate gender bias in LLMs more effectively, we present the LFTF (Locating First and Then Fine-Tuning) algorithm.The algorithm first ranks specific LLM blocks by their relevance to gender bias in descending order using a metric called BMI (Block Mitigating Importance Score). Based on this ranking, the block most strongly associated with gender bias is then fine-tuned using a carefully designed loss function. Numerous experiments have shown that our proposed LFTF algorithm can significantly mitigate gender bias in LLMs while maintaining their general capabilities.
CodeVisionary: An Agent-based Framework for Evaluating Large Language Models in Code Generation
Apr 18, 2025Large language models (LLMs) have demonstrated strong capabilities in code generation, underscoring the critical need for rigorous and comprehensive evaluation. Existing evaluation approaches fall into three categories, including human-centered, metric-based, and LLM-based. Considering that human-centered approaches are labour-intensive and metric-based ones overly rely on reference answers, LLM-based approaches are gaining increasing attention due to their stronger contextual understanding capabilities and superior efficiency. However, the performance of LLM-based approaches remains limited due to: (1) lack of multisource domain knowledge, and (2) insufficient comprehension of complex code. To mitigate the limitations, we propose CodeVisionary, the first LLM-based agent framework for evaluating LLMs in code generation. CodeVisionary consists of two stages: (1) Multiscore knowledge analysis stage, which aims to gather multisource and comprehensive domain knowledge by formulating and executing a stepwise evaluation plan. (2) Negotiation-based scoring stage, which involves multiple judges engaging in discussions to better comprehend the complex code and reach a consensus on the evaluation score. Extensive experiments demonstrate that CodeVisionary achieves the best performance for evaluating LLMs in code generation, outperforming the best baseline methods with average improvements of 0.202, 0.139, and 0.117 in Pearson, Spearman, and Kendall-Tau coefficients, respectively. Besides, CodeVisionary provides detailed evaluation reports, which assist developers in identifying shortcomings and making improvements. The resources of CodeVisionary are available at https://anonymous.4open.science/r/CodeVisionary.
An LLM-based Agent for Reliable Docker Environment Configuration
Feb 19, 2025Environment configuration is a critical yet time-consuming step in software development, especially when dealing with unfamiliar code repositories. While Large Language Models (LLMs) demonstrate the potential to accomplish software engineering tasks, existing methods for environment configuration often rely on manual efforts or fragile scripts, leading to inefficiencies and unreliable outcomes. We introduce Repo2Run, the first LLM-based agent designed to fully automate environment configuration and generate executable Dockerfiles for arbitrary Python repositories. We address two major challenges: (1) enabling the LLM agent to configure environments within isolated Docker containers, and (2) ensuring the successful configuration process is recorded and accurately transferred to a Dockerfile without error. To achieve this, we propose atomic configuration synthesis, featuring a dual-environment architecture (internal and external environment) with a rollback mechanism to prevent environment "pollution" from failed commands, guaranteeing atomic execution (execute fully or not at all) and a Dockerfile generator to transfer successful configuration steps into runnable Dockerfiles. We evaluate Repo2Run~on our proposed benchmark of 420 recent Python repositories with unit tests, where it achieves an 86.0% success rate, outperforming the best baseline by 63.9%.
Can LLMs Replace Human Evaluators? An Empirical Study of LLM-as-a-Judge in Software Engineering
Feb 10, 2025Recently, large language models (LLMs) have been deployed to tackle various software engineering (SE) tasks like code generation, significantly advancing the automation of SE tasks. However, assessing the quality of these LLM-generated code and text remains challenging. The commonly used Pass@k metric necessitates extensive unit tests and configured environments, demands a high labor cost, and is not suitable for evaluating LLM-generated text. Conventional metrics like BLEU, which measure only lexical rather than semantic similarity, have also come under scrutiny. In response, a new trend has emerged to employ LLMs for automated evaluation, known as LLM-as-a-judge. These LLM-as-a-judge methods are claimed to better mimic human assessment than conventional metrics without relying on high-quality reference answers. Nevertheless, their exact human alignment in SE tasks remains unexplored. In this paper, we empirically explore LLM-as-a-judge methods for evaluating SE tasks, focusing on their alignment with human judgments. We select seven LLM-as-a-judge methods that utilize general-purpose LLMs, alongside two LLMs specifically fine-tuned for evaluation. After generating and manually scoring LLM responses on three recent SE datasets of code translation, code generation, and code summarization, we then prompt these methods to evaluate each response. Finally, we compare the scores generated by these methods with human evaluation. The results indicate that output-based methods reach the highest Pearson correlation of 81.32 and 68.51 with human scores in code translation and generation, achieving near-human evaluation, noticeably outperforming ChrF++, one of the best conventional metrics, at 34.23 and 64.92. Such output-based methods prompt LLMs to output judgments directly, and exhibit more balanced score distributions that resemble human score patterns. Finally, we provide...
The Prompt Alchemist: Automated LLM-Tailored Prompt Optimization for Test Case Generation
Jan 02, 2025



Test cases are essential for validating the reliability and quality of software applications. Recent studies have demonstrated the capability of Large Language Models (LLMs) to generate useful test cases for given source code. However, the existing work primarily relies on human-written plain prompts, which often leads to suboptimal results since the performance of LLMs can be highly influenced by the prompts. Moreover, these approaches use the same prompt for all LLMs, overlooking the fact that different LLMs might be best suited to different prompts. Given the wide variety of possible prompt formulations, automatically discovering the optimal prompt for each LLM presents a significant challenge. Although there are methods on automated prompt optimization in the natural language processing field, they are hard to produce effective prompts for the test case generation task. First, the methods iteratively optimize prompts by simply combining and mutating existing ones without proper guidance, resulting in prompts that lack diversity and tend to repeat the same errors in the generated test cases. Second, the prompts are generally lack of domain contextual knowledge, limiting LLMs' performance in the task.
CodeRepoQA: A Large-scale Benchmark for Software Engineering Question Answering
Dec 19, 2024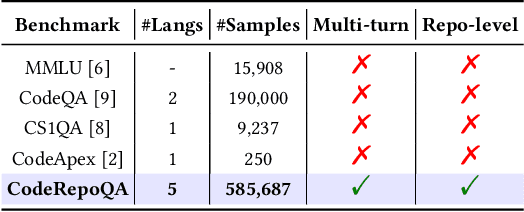
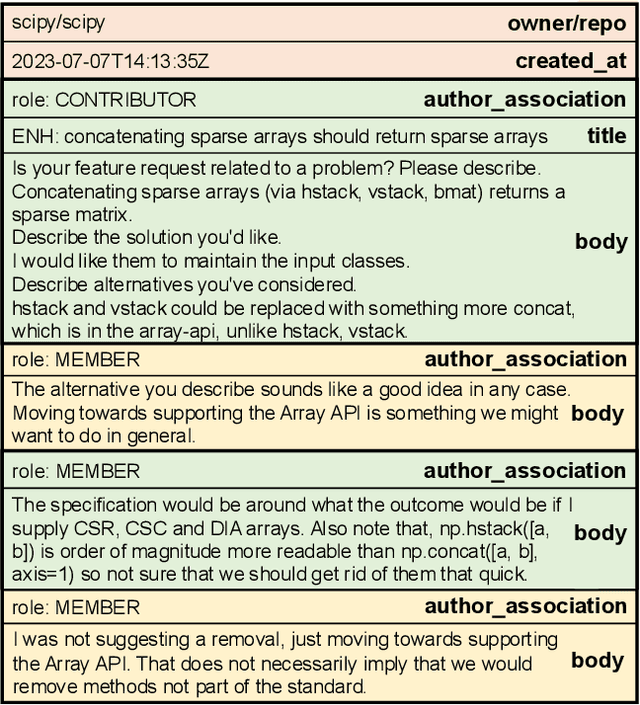

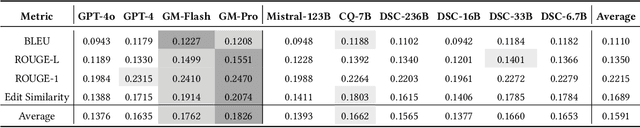
In this work, we introduce CodeRepoQA, a large-scale benchmark specifically designed for evaluating repository-level question-answering capabilities in the field of software engineering. CodeRepoQA encompasses five programming languages and covers a wide range of scenarios, enabling comprehensive evaluation of language models. To construct this dataset, we crawl data from 30 well-known repositories in GitHub, the largest platform for hosting and collaborating on code, and carefully filter raw data. In total, CodeRepoQA is a multi-turn question-answering benchmark with 585,687 entries, covering a diverse array of software engineering scenarios, with an average of 6.62 dialogue turns per entry. We evaluate ten popular large language models on our dataset and provide in-depth analysis. We find that LLMs still have limitations in question-answering capabilities in the field of software engineering, and medium-length contexts are more conducive to LLMs' performance. The entire benchmark is publicly available at https://github.com/kinesiatricssxilm14/CodeRepoQA.