 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSWE-Fuse: Empowering Software Agents via Issue-free Trajectory Learning and Entropy-aware RLVR Training
Mar 09, 2026Large language models (LLMs) have transformed the software engineering landscape. Recently, numerous LLM-based agents have been developed to address real-world software issue fixing tasks. Despite their state-of-the-art performance, Despite achieving state-of-the-art performance, these agents face a significant challenge: \textbf{Insufficient high-quality issue descriptions.} Real-world datasets often exhibit misalignments between issue descriptions and their corresponding solutions, introducing noise and ambiguity that mislead automated agents and limit their problem-solving effectiveness. We propose \textbf{\textit{SWE-Fuse}}, an issue-description-aware training framework that fuses issue-description-guided and issue-free samples for training SWE agents. It consists of two key modules: (1) An issue-free-driven trajectory learning module for mitigating potentially misleading issue descriptions while enabling the model to learn step-by-step debugging processes; and (2) An entropy-aware RLVR training module, which adaptively adjusts training dynamics through entropy-driven clipping. It applies relaxed clipping under high entropy to encourage exploration, and stricter clipping under low entropy to ensure training stability. We evaluate SWE-Fuse on the widely studied SWE-bench Verified benchmark shows to demonstrate its effectiveness in solving real-world software problems. Specifically, SWE-Fuse outperforms the best 8B and 32B baselines by 43.0\% and 60.2\% in solve rate, respectively. Furthermore, integrating SWE-Fuse with test-time scaling (TTS) enables further performance improvements, achieving solve rates of 49.8\% and 65.2\% under TTS@8 for the 8B and 32B models, respectively.
Benchmarking LLMs for Fine-Grained Code Review with Enriched Context in Practice
Nov 10, 2025



Code review is a cornerstone of software quality assurance, and recent advances in Large Language Models (LLMs) have shown promise in automating this process. However, existing benchmarks for LLM-based code review face three major limitations. (1) Lack of semantic context: most benchmarks provide only code diffs without textual information such as issue descriptions, which are crucial for understanding developer intent. (2) Data quality issues: without rigorous validation, many samples are noisy-e.g., reviews on outdated or irrelevant code-reducing evaluation reliability. (3) Coarse granularity: most benchmarks operate at the file or commit level, overlooking the fine-grained, line-level reasoning essential for precise review. We introduce ContextCRBench, a high-quality, context-rich benchmark for fine-grained LLM evaluation in code review. Our construction pipeline comprises: (1) Raw Data Crawling, collecting 153.7K issues and pull requests from top-tier repositories; (2) Comprehensive Context Extraction, linking issue-PR pairs for textual context and extracting the full surrounding function or class for code context; and (3) Multi-stage Data Filtering, combining rule-based and LLM-based validation to remove outdated, malformed, or low-value samples, resulting in 67,910 context-enriched entries. ContextCRBench supports three evaluation scenarios aligned with the review workflow: (1) hunk-level quality assessment, (2) line-level defect localization, and (3) line-level comment generation. Evaluating eight leading LLMs (four closed-source and four open-source) reveals that textual context yields greater performance gains than code context alone, while current LLMs remain far from human-level review ability. Deployed at ByteDance, ContextCRBench drives a self-evolving code review system, improving performance by 61.98% and demonstrating its robustness and industrial utility.
Boosting Vulnerability Detection of LLMs via Curriculum Preference Optimization with Synthetic Reasoning Data
Jun 09, 2025



Large language models (LLMs) demonstrate considerable proficiency in numerous coding-related tasks; however, their capabilities in detecting software vulnerabilities remain limited. This limitation primarily stems from two factors: (1) the absence of reasoning data related to vulnerabilities, which hinders the models' ability to capture underlying vulnerability patterns; and (2) their focus on learning semantic representations rather than the reason behind them, thus failing to recognize semantically similar vulnerability samples. Furthermore, the development of LLMs specialized in vulnerability detection is challenging, particularly in environments characterized by the scarcity of high-quality datasets. In this paper, we propose a novel framework ReVD that excels at mining vulnerability patterns through reasoning data synthesizing and vulnerability-specific preference optimization. Specifically, we construct forward and backward reasoning processes for vulnerability and corresponding fixed code, ensuring the synthesis of high-quality reasoning data. Moreover, we design the triplet supervised fine-tuning followed by curriculum online preference optimization for enabling ReVD to better understand vulnerability patterns. The extensive experiments conducted on PrimeVul and SVEN datasets demonstrate that ReVD sets new state-of-the-art for LLM-based software vulnerability detection, e.g., 12.24\%-22.77\% improvement in the accuracy. The source code and data are available at https://github.com/Xin-Cheng-Wen/PO4Vul.
Repository-Level Graph Representation Learning for Enhanced Security Patch Detection
Dec 11, 2024



Software vendors often silently release security patches without providing sufficient advisories (e.g., Common Vulnerabilities and Exposures) or delayed updates via resources (e.g., National Vulnerability Database). Therefore, it has become crucial to detect these security patches to ensure secure software maintenance. However, existing methods face the following challenges: (1) They primarily focus on the information within the patches themselves, overlooking the complex dependencies in the repository. (2) Security patches typically involve multiple functions and files, increasing the difficulty in well learning the representations. To alleviate the above challenges, this paper proposes a Repository-level Security Patch Detection framework named RepoSPD, which comprises three key components: 1) a repository-level graph construction, RepoCPG, which represents software patches by merging pre-patch and post-patch source code at the repository level; 2) a structure-aware patch representation, which fuses the graph and sequence branch and aims at comprehending the relationship among multiple code changes; 3) progressive learning, which facilitates the model in balancing semantic and structural information. To evaluate RepoSPD, we employ two widely-used datasets in security patch detection: SPI-DB and PatchDB. We further extend these datasets to the repository level, incorporating a total of 20,238 and 28,781 versions of repository in C/C++ programming languages, respectively, denoted as SPI-DB* and PatchDB*. We compare RepoSPD with six existing security patch detection methods and five static tools. Our experimental results demonstrate that RepoSPD outperforms the state-of-the-art baseline, with improvements of 11.90%, and 3.10% in terms of accuracy on the two datasets, respectively.
When Less is Enough: Positive and Unlabeled Learning Model for Vulnerability Detection
Aug 21, 2023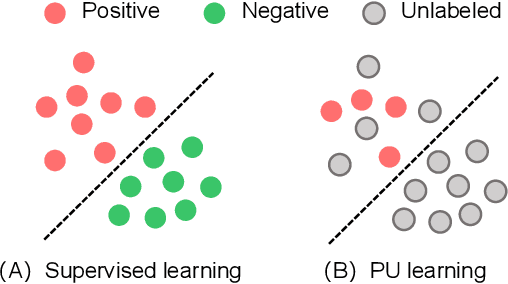
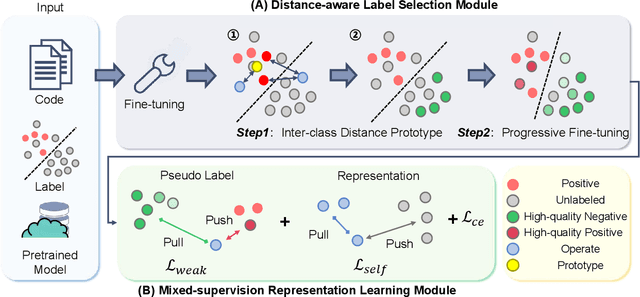

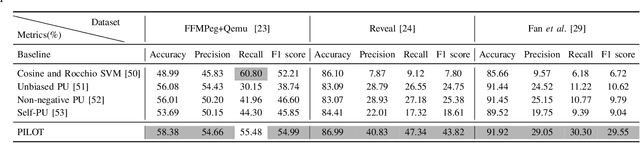
Automated code vulnerability detection has gained increasing attention in recent years. The deep learning (DL)-based methods, which implicitly learn vulnerable code patterns, have proven effective in vulnerability detection. The performance of DL-based methods usually relies on the quantity and quality of labeled data. However, the current labeled data are generally automatically collected, such as crawled from human-generated commits, making it hard to ensure the quality of the labels. Prior studies have demonstrated that the non-vulnerable code (i.e., negative labels) tends to be unreliable in commonly-used datasets, while vulnerable code (i.e., positive labels) is more determined. Considering the large numbers of unlabeled data in practice, it is necessary and worth exploring to leverage the positive data and large numbers of unlabeled data for more accurate vulnerability detection. In this paper, we focus on the Positive and Unlabeled (PU) learning problem for vulnerability detection and propose a novel model named PILOT, i.e., PositIve and unlabeled Learning mOdel for vulnerability deTection. PILOT only learns from positive and unlabeled data for vulnerability detection. It mainly contains two modules: (1) A distance-aware label selection module, aiming at generating pseudo-labels for selected unlabeled data, which involves the inter-class distance prototype and progressive fine-tuning; (2) A mixed-supervision representation learning module to further alleviate the influence of noise and enhance the discrimination of representations.
Emo-DNA: Emotion Decoupling and Alignment Learning for Cross-Corpus Speech Emotion Recognition
Aug 04, 2023



Cross-corpus speech emotion recognition (SER) seeks to generalize the ability of inferring speech emotion from a well-labeled corpus to an unlabeled one, which is a rather challenging task due to the significant discrepancy between two corpora. Existing methods, typically based on unsupervised domain adaptation (UDA), struggle to learn corpus-invariant features by global distribution alignment, but unfortunately, the resulting features are mixed with corpus-specific features or not class-discriminative. To tackle these challenges, we propose a novel Emotion Decoupling aNd Alignment learning framework (EMO-DNA) for cross-corpus SER, a novel UDA method to learn emotion-relevant corpus-invariant features. The novelties of EMO-DNA are two-fold: contrastive emotion decoupling and dual-level emotion alignment. On one hand, our contrastive emotion decoupling achieves decoupling learning via a contrastive decoupling loss to strengthen the separability of emotion-relevant features from corpus-specific ones. On the other hand, our dual-level emotion alignment introduces an adaptive threshold pseudo-labeling to select confident target samples for class-level alignment, and performs corpus-level alignment to jointly guide model for learning class-discriminative corpus-invariant features across corpora. Extensive experimental results demonstrate the superior performance of EMO-DNA over the state-of-the-art methods in several cross-corpus scenarios. Source code is available at https://github.com/Jiaxin-Ye/Emo-DNA.
LIVABLE: Exploring Long-Tailed Classification of Software Vulnerability Types
Jun 12, 2023
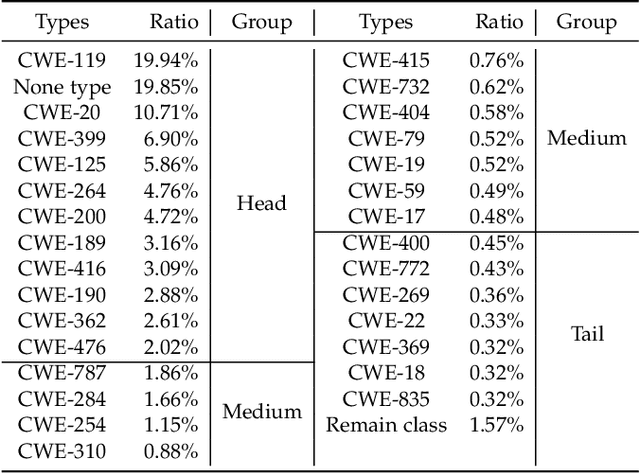

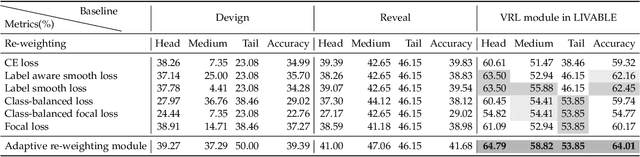
Prior studies generally focus on software vulnerability detection and have demonstrated the effectiveness of Graph Neural Network (GNN)-based approaches for the task. Considering the various types of software vulnerabilities and the associated different degrees of severity, it is also beneficial to determine the type of each vulnerable code for developers. In this paper, we observe that the distribution of vulnerability type is long-tailed in practice, where a small portion of classes have massive samples (i.e., head classes) but the others contain only a few samples (i.e., tail classes). Directly adopting previous vulnerability detection approaches tends to result in poor detection performance, mainly due to two reasons. First, it is difficult to effectively learn the vulnerability representation due to the over-smoothing issue of GNNs. Second, vulnerability types in tails are hard to be predicted due to the extremely few associated samples.To alleviate these issues, we propose a Long-taIled software VulnerABiLity typE classification approach, called LIVABLE. LIVABLE mainly consists of two modules, including (1) vulnerability representation learning module, which improves the propagation steps in GNN to distinguish node representations by a differentiated propagation method. A sequence-to-sequence model is also involved to enhance the vulnerability representations. (2) adaptive re-weighting module, which adjusts the learning weights for different types according to the training epochs and numbers of associated samples by a novel training loss.
GM-TCNet: Gated Multi-scale Temporal Convolutional Network using Emotion Causality for Speech Emotion Recognition
Oct 28, 2022



In human-computer interaction, Speech Emotion Recognition (SER) plays an essential role in understanding the user's intent and improving the interactive experience. While similar sentimental speeches own diverse speaker characteristics but share common antecedents and consequences, an essential challenge for SER is how to produce robust and discriminative representations through causality between speech emotions. In this paper, we propose a Gated Multi-scale Temporal Convolutional Network (GM-TCNet) to construct a novel emotional causality representation learning component with a multi-scale receptive field. GM-TCNet deploys a novel emotional causality representation learning component to capture the dynamics of emotion across the time domain, constructed with dilated causal convolution layer and gating mechanism. Besides, it utilizes skip connection fusing high-level features from different gated convolution blocks to capture abundant and subtle emotion changes in human speech. GM-TCNet first uses a single type of feature, mel-frequency cepstral coefficients, as inputs and then passes them through the gated temporal convolutional module to generate the high-level features. Finally, the features are fed to the emotion classifier to accomplish the SER task. The experimental results show that our model maintains the highest performance in most cases compared to state-of-the-art techniques.
* The source code is available at: https://github.com/Jiaxin-Ye/GM-TCNet
CTL-MTNet: A Novel CapsNet and Transfer Learning-Based Mixed Task Net for the Single-Corpus and Cross-Corpus Speech Emotion Recognition
Jul 18, 2022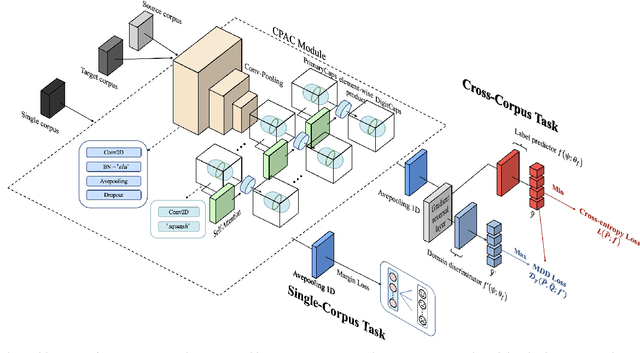
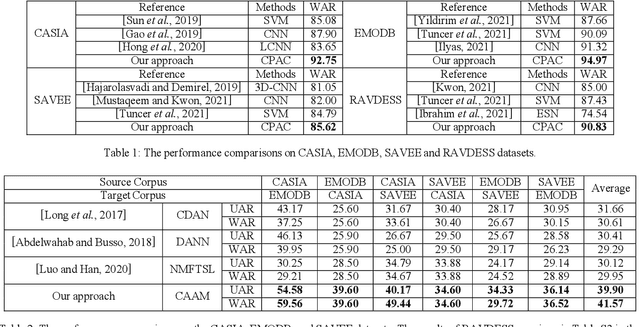
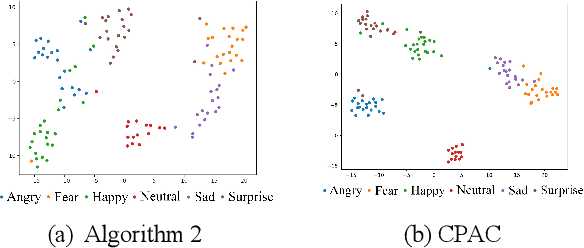

Speech Emotion Recognition (SER) has become a growing focus of research in human-computer interaction. An essential challenge in SER is to extract common attributes from different speakers or languages, especially when a specific source corpus has to be trained to recognize the unknown data coming from another speech corpus. To address this challenge, a Capsule Network (CapsNet) and Transfer Learning based Mixed Task Net (CTLMTNet) are proposed to deal with both the singlecorpus and cross-corpus SER tasks simultaneously in this paper. For the single-corpus task, the combination of Convolution-Pooling and Attention CapsNet module CPAC) is designed by embedding the self-attention mechanism to the CapsNet, guiding the module to focus on the important features that can be fed into different capsules. The extracted high-level features by CPAC provide sufficient discriminative ability. Furthermore, to handle the cross-corpus task, CTL-MTNet employs a Corpus Adaptation Adversarial Module (CAAM) by combining CPAC with Margin Disparity Discrepancy (MDD), which can learn the domain-invariant emotion representations through extracting the strong emotion commonness. Experiments including ablation studies and visualizations on both singleand cross-corpus tasks using four well-known SER datasets in different languages are conducted for performance evaluation and comparison. The results indicate that in both tasks the CTL-MTNet showed better performance in all cases compared to a number of state-of-the-art methods. The source code and the supplementary materials are available at: https://github.com/MLDMXM2017/CTLMTNet