 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGM-TCNet: Gated Multi-scale Temporal Convolutional Network using Emotion Causality for Speech Emotion Recognition
Oct 28, 2022



In human-computer interaction, Speech Emotion Recognition (SER) plays an essential role in understanding the user's intent and improving the interactive experience. While similar sentimental speeches own diverse speaker characteristics but share common antecedents and consequences, an essential challenge for SER is how to produce robust and discriminative representations through causality between speech emotions. In this paper, we propose a Gated Multi-scale Temporal Convolutional Network (GM-TCNet) to construct a novel emotional causality representation learning component with a multi-scale receptive field. GM-TCNet deploys a novel emotional causality representation learning component to capture the dynamics of emotion across the time domain, constructed with dilated causal convolution layer and gating mechanism. Besides, it utilizes skip connection fusing high-level features from different gated convolution blocks to capture abundant and subtle emotion changes in human speech. GM-TCNet first uses a single type of feature, mel-frequency cepstral coefficients, as inputs and then passes them through the gated temporal convolutional module to generate the high-level features. Finally, the features are fed to the emotion classifier to accomplish the SER task. The experimental results show that our model maintains the highest performance in most cases compared to state-of-the-art techniques.
* The source code is available at: https://github.com/Jiaxin-Ye/GM-TCNet
CTL-MTNet: A Novel CapsNet and Transfer Learning-Based Mixed Task Net for the Single-Corpus and Cross-Corpus Speech Emotion Recognition
Jul 18, 2022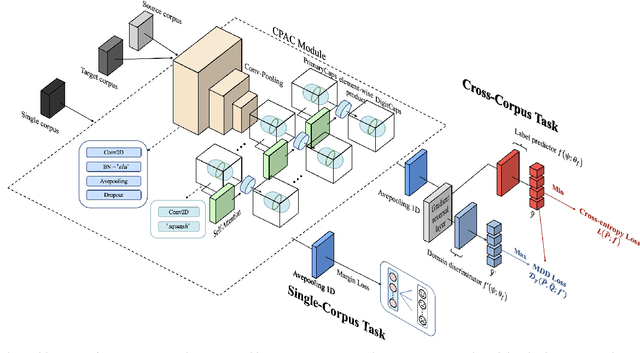
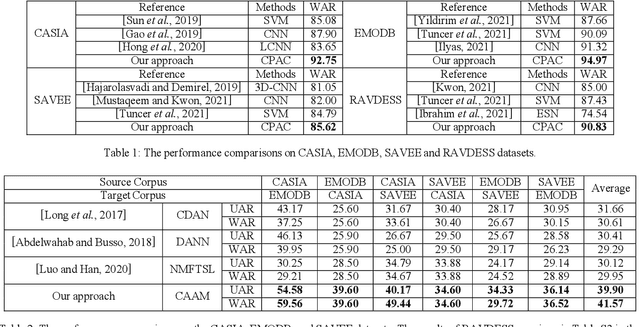
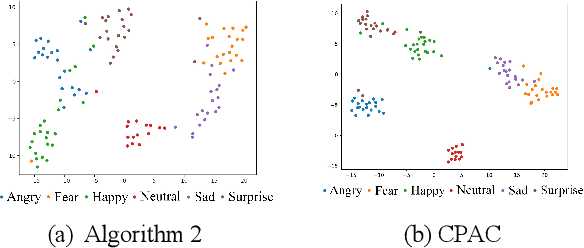

Speech Emotion Recognition (SER) has become a growing focus of research in human-computer interaction. An essential challenge in SER is to extract common attributes from different speakers or languages, especially when a specific source corpus has to be trained to recognize the unknown data coming from another speech corpus. To address this challenge, a Capsule Network (CapsNet) and Transfer Learning based Mixed Task Net (CTLMTNet) are proposed to deal with both the singlecorpus and cross-corpus SER tasks simultaneously in this paper. For the single-corpus task, the combination of Convolution-Pooling and Attention CapsNet module CPAC) is designed by embedding the self-attention mechanism to the CapsNet, guiding the module to focus on the important features that can be fed into different capsules. The extracted high-level features by CPAC provide sufficient discriminative ability. Furthermore, to handle the cross-corpus task, CTL-MTNet employs a Corpus Adaptation Adversarial Module (CAAM) by combining CPAC with Margin Disparity Discrepancy (MDD), which can learn the domain-invariant emotion representations through extracting the strong emotion commonness. Experiments including ablation studies and visualizations on both singleand cross-corpus tasks using four well-known SER datasets in different languages are conducted for performance evaluation and comparison. The results indicate that in both tasks the CTL-MTNet showed better performance in all cases compared to a number of state-of-the-art methods. The source code and the supplementary materials are available at: https://github.com/MLDMXM2017/CTLMTNet
Efficient Neural Network Approaches for Leather Defect Classification
Jun 15, 2019
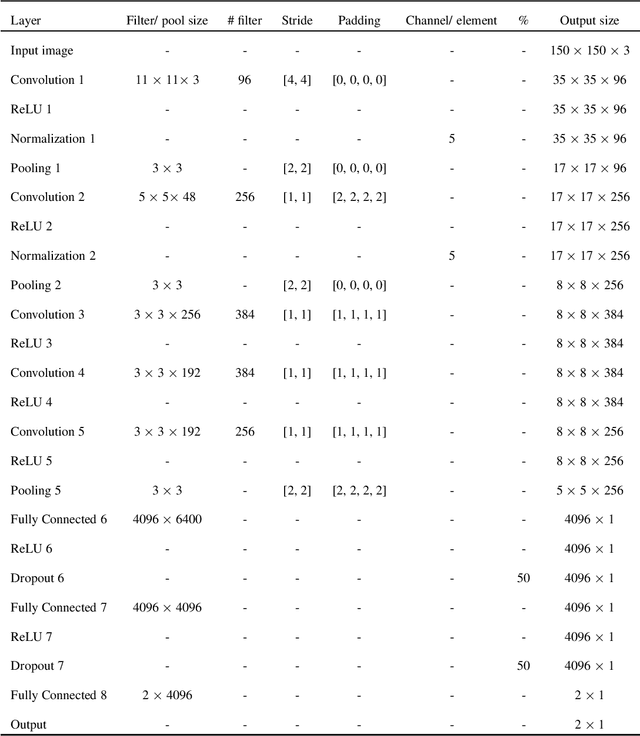

Genuine leather, such as the hides of cows, crocodiles, lizards and goats usually contain natural and artificial defects, like holes, fly bites, tick marks, veining, cuts, wrinkles and others. A traditional solution to identify the defects is by manual defect inspection, which involves skilled experts. It is time consuming and may incur a high error rate and results in low productivity. This paper presents a series of automatic image processing processes to perform the classification of leather defects by adopting deep learning approaches. Particularly, the leather images are first partitioned into small patches,then it undergoes a pre-processing technique, namely the Canny edge detection to enhance defect visualization. Next, artificial neural network (ANN) and convolutional neural network (CNN) are employed to extract the rich image features. The best classification result achieved is 80.3 %, evaluated on a data set that consists of 2000 samples. In addition, the performance metrics such as confusion matrix and Receiver Operating Characteristic (ROC) are reported to demonstrate the efficiency of the method proposed.
Integrated Neural Network and Machine Vision Approach For Leather Defect Classification
May 28, 2019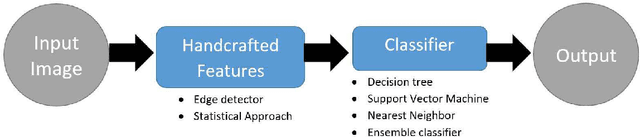
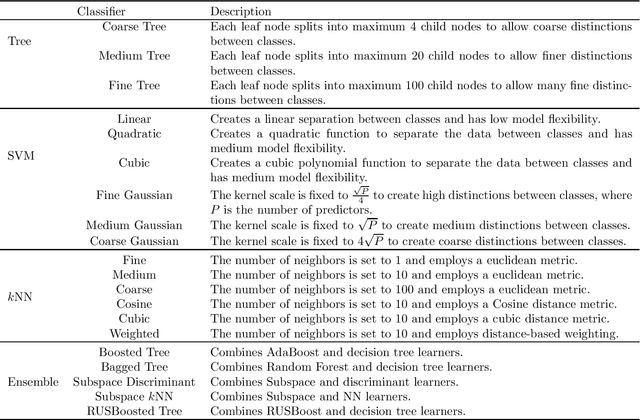

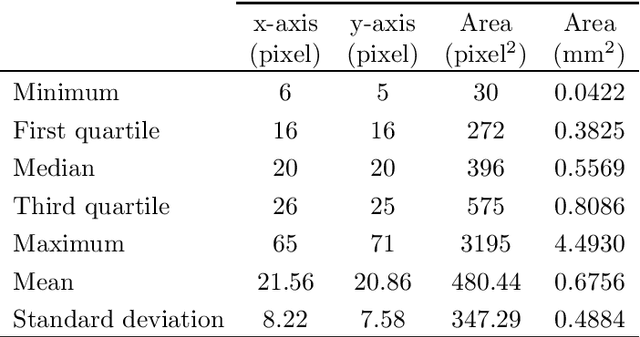
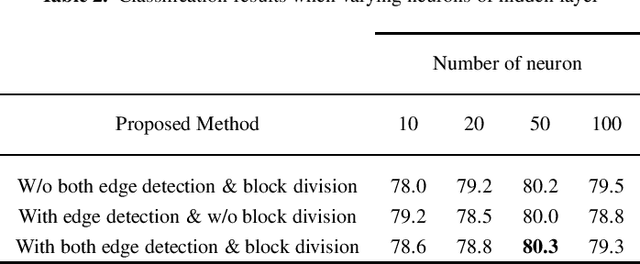
Leather is a type of natural, durable, flexible, soft, supple and pliable material with smooth texture. It is commonly used as a raw material to manufacture luxury consumer goods for high-end customers. To ensure good quality control on the leather products, one of the critical processes is the visual inspection step to spot the random defects on the leather surfaces and it is usually conducted by experienced experts. This paper presents an automatic mechanism to perform the leather defect classification. In particular, we focus on detecting tick-bite defects on a specific type of calf leather. Both the handcrafted feature extractors (i.e., edge detectors and statistical approach) and data-driven (i.e., artificial neural network) methods are utilized to represent the leather patches. Then, multiple classifiers (i.e., decision trees, Support Vector Machines, nearest neighbour and ensemble classifiers) are exploited to determine whether the test sample patches contain defective segments. Using the proposed method, we managed to get a classification accuracy rate of 84% from a sample of approximately 2500 pieces of 400 * 400 leather patches.
Evaluation of the Spatio-Temporal features and GAN for Micro-expression Recognition System
Apr 03, 2019
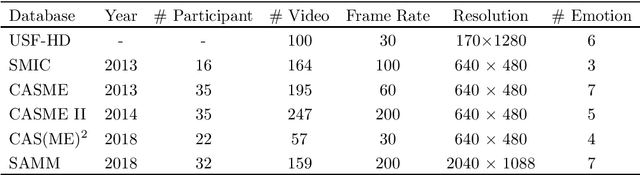
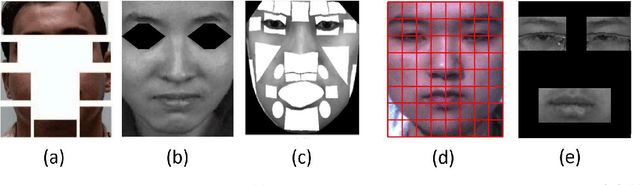
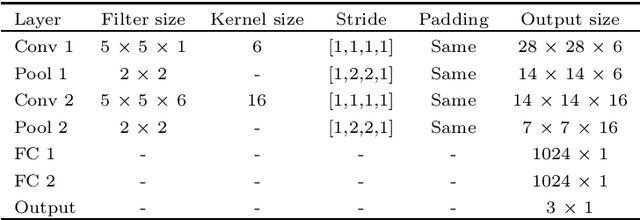
Owing to the development and advancement of artificial intelligence, numerous works were established in the human facial expression recognition system. Meanwhile, the detection and classification of micro-expressions are attracting attentions from various research communities in the recent few years. In this paper, we first review the processes of a conventional optical-flow-based recognition system, which comprised of facial landmarks annotations, optical flow guided images computation, features extraction and emotion class categorization. Secondly, a few approaches have been proposed to improve the feature extraction part, such as exploiting GAN to generate more image samples. Particularly, several variations of optical flow are computed in order to generate optimal images to lead to high recognition accuracy. Next, GAN, a combination of Generator and Discriminator, is utilized to generate new "fake" images to increase the sample size. Thirdly, a modified state-of-the-art Convolutional neural networks is proposed. To verify the effectiveness of the the proposed method, the results are evaluated on spontaneous micro-expression databases, namely SMIC, CASME II and SAMM. Both the F1-score and accuracy performance metrics are reported in this paper.