 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong-Form Information Alignment Evaluation Beyond Atomic Facts
May 21, 2025Information alignment evaluators are vital for various NLG evaluation tasks and trustworthy LLM deployment, reducing hallucinations and enhancing user trust. Current fine-grained methods, like FactScore, verify facts individually but neglect inter-fact dependencies, enabling subtle vulnerabilities. In this work, we introduce MontageLie, a challenging benchmark that constructs deceptive narratives by "montaging" truthful statements without introducing explicit hallucinations. We demonstrate that both coarse-grained LLM-based evaluators and current fine-grained frameworks are susceptible to this attack, with AUC-ROC scores falling below 65%. To enable more robust fine-grained evaluation, we propose DoveScore, a novel framework that jointly verifies factual accuracy and event-order consistency. By modeling inter-fact relationships, DoveScore outperforms existing fine-grained methods by over 8%, providing a more robust solution for long-form text alignment evaluation. Our code and datasets are available at https://github.com/dannalily/DoveScore.
Rethinking Memory in AI: Taxonomy, Operations, Topics, and Future Directions
May 01, 2025Memory is a fundamental component of AI systems, underpinning large language models (LLMs) based agents. While prior surveys have focused on memory applications with LLMs, they often overlook the atomic operations that underlie memory dynamics. In this survey, we first categorize memory representations into parametric, contextual structured, and contextual unstructured and then introduce six fundamental memory operations: Consolidation, Updating, Indexing, Forgetting, Retrieval, and Compression. We systematically map these operations to the most relevant research topics across long-term, long-context, parametric modification, and multi-source memory. By reframing memory systems through the lens of atomic operations and representation types, this survey provides a structured and dynamic perspective on research, benchmark datasets, and tools related to memory in AI, clarifying the functional interplay in LLMs based agents while outlining promising directions for future research\footnote{The paper list, datasets, methods and tools are available at \href{https://github.com/Elvin-Yiming-Du/Survey_Memory_in_AI}{https://github.com/Elvin-Yiming-Du/Survey\_Memory\_in\_AI}.}.
Large Language Models as Reliable Knowledge Bases?
Jul 18, 2024



The NLP community has recently shown a growing interest in leveraging Large Language Models (LLMs) for knowledge-intensive tasks, viewing LLMs as potential knowledge bases (KBs). However, the reliability and extent to which LLMs can function as KBs remain underexplored. While previous studies suggest LLMs can encode knowledge within their parameters, the amount of parametric knowledge alone is not sufficient to evaluate their effectiveness as KBs. This study defines criteria that a reliable LLM-as-KB should meet, focusing on factuality and consistency, and covering both seen and unseen knowledge. We develop several metrics based on these criteria and use them to evaluate 26 popular LLMs, while providing a comprehensive analysis of the effects of model size, instruction tuning, and in-context learning (ICL). Our results paint a worrying picture. Even a high-performant model like GPT-3.5-turbo is not factual or consistent, and strategies like ICL and fine-tuning are unsuccessful at making LLMs better KBs.
Archer: A Human-Labeled Text-to-SQL Dataset with Arithmetic, Commonsense and Hypothetical Reasoning
Feb 25, 2024



We present Archer, a challenging bilingual text-to-SQL dataset specific to complex reasoning, including arithmetic, commonsense and hypothetical reasoning. It contains 1,042 English questions and 1,042 Chinese questions, along with 521 unique SQL queries, covering 20 English databases across 20 domains. Notably, this dataset demonstrates a significantly higher level of complexity compared to existing publicly available datasets. Our evaluation shows that Archer challenges the capabilities of current state-of-the-art models, with a high-ranked model on the Spider leaderboard achieving only 6.73% execution accuracy on Archer test set. Thus, Archer presents a significant challenge for future research in this field.
TrustScore: Reference-Free Evaluation of LLM Response Trustworthiness
Feb 19, 2024

Large Language Models (LLMs) have demonstrated impressive capabilities across various domains, prompting a surge in their practical applications. However, concerns have arisen regarding the trustworthiness of LLMs outputs, particularly in closed-book question-answering tasks, where non-experts may struggle to identify inaccuracies due to the absence of contextual or ground truth information. This paper introduces TrustScore, a framework based on the concept of Behavioral Consistency, which evaluates whether an LLMs response aligns with its intrinsic knowledge. Additionally, TrustScore can seamlessly integrate with fact-checking methods, which assesses alignment with external knowledge sources. The experimental results show that TrustScore achieves strong correlations with human judgments, surpassing existing reference-free metrics, and achieving results on par with reference-based metrics.
Evaluation of the Spatio-Temporal features and GAN for Micro-expression Recognition System
Apr 03, 2019
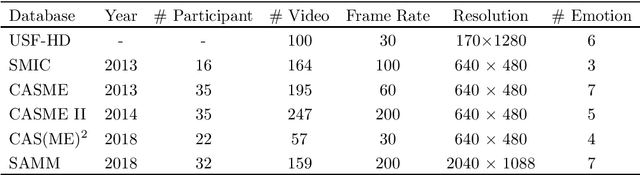
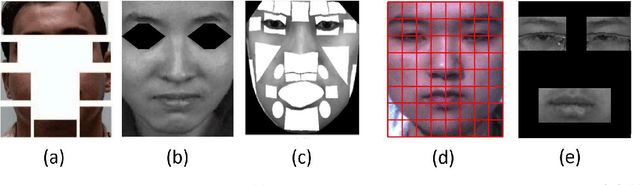
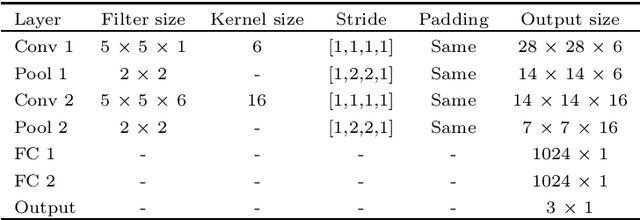
Owing to the development and advancement of artificial intelligence, numerous works were established in the human facial expression recognition system. Meanwhile, the detection and classification of micro-expressions are attracting attentions from various research communities in the recent few years. In this paper, we first review the processes of a conventional optical-flow-based recognition system, which comprised of facial landmarks annotations, optical flow guided images computation, features extraction and emotion class categorization. Secondly, a few approaches have been proposed to improve the feature extraction part, such as exploiting GAN to generate more image samples. Particularly, several variations of optical flow are computed in order to generate optimal images to lead to high recognition accuracy. Next, GAN, a combination of Generator and Discriminator, is utilized to generate new "fake" images to increase the sample size. Thirdly, a modified state-of-the-art Convolutional neural networks is proposed. To verify the effectiveness of the the proposed method, the results are evaluated on spontaneous micro-expression databases, namely SMIC, CASME II and SAMM. Both the F1-score and accuracy performance metrics are reported in this paper.