 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKimi K2.5: Visual Agentic Intelligence
Feb 02, 2026We introduce Kimi K2.5, an open-source multimodal agentic model designed to advance general agentic intelligence. K2.5 emphasizes the joint optimization of text and vision so that two modalities enhance each other. This includes a series of techniques such as joint text-vision pre-training, zero-vision SFT, and joint text-vision reinforcement learning. Building on this multimodal foundation, K2.5 introduces Agent Swarm, a self-directed parallel agent orchestration framework that dynamically decomposes complex tasks into heterogeneous sub-problems and executes them concurrently. Extensive evaluations show that Kimi K2.5 achieves state-of-the-art results across various domains including coding, vision, reasoning, and agentic tasks. Agent Swarm also reduces latency by up to $4.5\times$ over single-agent baselines. We release the post-trained Kimi K2.5 model checkpoint to facilitate future research and real-world applications of agentic intelligence.
Memory-T1: Reinforcement Learning for Temporal Reasoning in Multi-session Agents
Dec 23, 2025Temporal reasoning over long, multi-session dialogues is a critical capability for conversational agents. However, existing works and our pilot study have shown that as dialogue histories grow in length and accumulate noise, current long-context models struggle to accurately identify temporally pertinent information, significantly impairing reasoning performance. To address this, we introduce Memory-T1, a framework that learns a time-aware memory selection policy using reinforcement learning (RL). It employs a coarse-to-fine strategy, first pruning the dialogue history into a candidate set using temporal and relevance filters, followed by an RL agent that selects the precise evidence sessions. The RL training is guided by a multi-level reward function optimizing (i) answer accuracy, (ii) evidence grounding, and (iii) temporal consistency. In particular, the temporal consistency reward provides a dense signal by evaluating alignment with the query time scope at both the session-level (chronological proximity) and the utterance-level (chronological fidelity), enabling the agent to resolve subtle chronological ambiguities. On the Time-Dialog benchmark, Memory-T1 boosts a 7B model to an overall score of 67.0\%, establishing a new state-of-the-art performance for open-source models and outperforming a 14B baseline by 10.2\%. Ablation studies show temporal consistency and evidence grounding rewards jointly contribute to a 15.0\% performance gain. Moreover, Memory-T1 maintains robustness up to 128k tokens, where baseline models collapse, proving effectiveness against noise in extensive dialogue histories. The code and datasets are publicly available at https://github.com/Elvin-Yiming-Du/Memory-T1/
NewtonBench: Benchmarking Generalizable Scientific Law Discovery in LLM Agents
Oct 08, 2025Large language models are emerging as powerful tools for scientific law discovery, a foundational challenge in AI-driven science. However, existing benchmarks for this task suffer from a fundamental methodological trilemma, forcing a trade-off between scientific relevance, scalability, and resistance to memorization. Furthermore, they oversimplify discovery as static function fitting, failing to capture the authentic scientific process of uncovering embedded laws through the interactive exploration of complex model systems. To address these critical gaps, we introduce NewtonBench, a benchmark comprising 324 scientific law discovery tasks across 12 physics domains. Our design mitigates the evaluation trilemma by using metaphysical shifts - systematic alterations of canonical laws - to generate a vast suite of problems that are scalable, scientifically relevant, and memorization-resistant. Moreover, we elevate the evaluation from static function fitting to interactive model discovery, requiring agents to experimentally probe simulated complex systems to uncover hidden principles. Our extensive experiment reveals a clear but fragile capability for discovery in frontier LLMs: this ability degrades precipitously with increasing system complexity and exhibits extreme sensitivity to observational noise. Notably, we uncover a paradoxical effect of tool assistance: providing a code interpreter can hinder more capable models by inducing a premature shift from exploration to exploitation, causing them to satisfice on suboptimal solutions. These results demonstrate that robust, generalizable discovery in complex, interactive environments remains the core challenge. By providing a scalable, robust, and scientifically authentic testbed, NewtonBench offers a crucial tool for measuring true progress and guiding the development of next-generation AI agents capable of genuine scientific discovery.
The Cognitive Bandwidth Bottleneck: Shifting Long-Horizon Agent from Planning with Actions to Planning with Schemas
Oct 08, 2025Enabling LLMs to effectively operate long-horizon task which requires long-term planning and multiple interactions is essential for open-world autonomy. Conventional methods adopt planning with actions where a executable action list would be provided as reference. However, this action representation choice would be impractical when the environment action space is combinatorial exploded (e.g., open-ended real world). This naturally leads to a question: As environmental action space scales, what is the optimal action representation for long-horizon agents? In this paper, we systematically study the effectiveness of two different action representations. The first one is conventional planning with actions (PwA) which is predominantly adopted for its effectiveness on existing benchmarks. The other one is planning with schemas (PwS) which instantiate an action schema into action lists (e.g., "move [OBJ] to [OBJ]" -> "move apple to desk") to ensure concise action space and reliable scalability. This alternative is motivated by its alignment with human cognition and its compliance with environment-imposed action format restriction. We propose cognitive bandwidth perspective as a conceptual framework to qualitatively understand the differences between these two action representations and empirically observe a representation-choice inflection point between ALFWorld (~35 actions) and SciWorld (~500 actions), which serve as evidence of the need for scalable representations. We further conduct controlled experiments to study how the location of this inflection point interacts with different model capacities: stronger planning proficiency shifts the inflection rightward, whereas better schema instantiation shifts it leftward. Finally, noting the suboptimal performance of PwS agents, we provide an actionable guide for building more capable PwS agents for better scalable autonomy.
Anti-Jamming Sensing with Distributed Reconfigurable Intelligent Metasurface Antennas
Aug 07, 2025The utilization of radio frequency (RF) signals for wireless sensing has garnered increasing attention. However, the radio environment is unpredictable and often unfavorable, the sensing accuracy of traditional RF sensing methods is often affected by adverse propagation channels from the transmitter to the receiver, such as fading and noise. In this paper, we propose employing distributed Reconfigurable Intelligent Metasurface Antennas (RIMSA) to detect the presence and location of objects where multiple RIMSA receivers (RIMSA Rxs) are deployed on different places. By programming their beamforming patterns, RIMSA Rxs can enhance the quality of received signals. The RF sensing problem is modeled as a joint optimization problem of beamforming pattern and mapping of received signals to sensing outcomes. To address this challenge, we introduce a deep reinforcement learning (DRL) algorithm aimed at calculating the optimal beamforming patterns and a neural network aimed at converting received signals into sensing outcomes. In addition, the malicious attacker may potentially launch jamming attack to disrupt sensing process. To enable effective sensing in interferenceprone environment, we devise a combined loss function that takes into account the Signal to Interference plus Noise Ratio (SINR) of the received signals. The simulation results show that the proposed distributed RIMSA system can achieve more efficient sensing performance and better overcome environmental influences than centralized implementation. Furthermore, the introduced method ensures high-accuracy sensing performance even under jamming attack.
LLMs are Frequency Pattern Learners in Natural Language Inference
May 27, 2025



While fine-tuning LLMs on NLI corpora improves their inferential performance, the underlying mechanisms driving this improvement remain largely opaque. In this work, we conduct a series of experiments to investigate what LLMs actually learn during fine-tuning. We begin by analyzing predicate frequencies in premises and hypotheses across NLI datasets and identify a consistent frequency bias, where predicates in hypotheses occur more frequently than those in premises for positive instances. To assess the impact of this bias, we evaluate both standard and NLI fine-tuned LLMs on bias-consistent and bias-adversarial cases. We find that LLMs exploit frequency bias for inference and perform poorly on adversarial instances. Furthermore, fine-tuned LLMs exhibit significantly increased reliance on this bias, suggesting that they are learning these frequency patterns from datasets. Finally, we compute the frequencies of hyponyms and their corresponding hypernyms from WordNet, revealing a correlation between frequency bias and textual entailment. These findings help explain why learning frequency patterns can enhance model performance on inference tasks.
S2LPP: Small-to-Large Prompt Prediction across LLMs
May 26, 2025



The performance of pre-trained Large Language Models (LLMs) is often sensitive to nuances in prompt templates, requiring careful prompt engineering, adding costs in terms of computing and human effort. In this study, we present experiments encompassing multiple LLMs variants of varying sizes aimed at probing their preference with different prompts. Through experiments on Question Answering, we show prompt preference consistency across LLMs of different sizes. We also show that this consistency extends to other tasks, such as Natural Language Inference. Utilizing this consistency, we propose a method to use a smaller model to select effective prompt templates for a larger model. We show that our method substantially reduces the cost of prompt engineering while consistently matching performance with optimal prompts among candidates. More importantly, our experiment shows the efficacy of our strategy across fourteen LLMs and its applicability to a broad range of NLP tasks, highlighting its robustness
MMLongBench: Benchmarking Long-Context Vision-Language Models Effectively and Thoroughly
May 15, 2025The rapid extension of context windows in large vision-language models has given rise to long-context vision-language models (LCVLMs), which are capable of handling hundreds of images with interleaved text tokens in a single forward pass. In this work, we introduce MMLongBench, the first benchmark covering a diverse set of long-context vision-language tasks, to evaluate LCVLMs effectively and thoroughly. MMLongBench is composed of 13,331 examples spanning five different categories of downstream tasks, such as Visual RAG and Many-Shot ICL. It also provides broad coverage of image types, including various natural and synthetic images. To assess the robustness of the models to different input lengths, all examples are delivered at five standardized input lengths (8K-128K tokens) via a cross-modal tokenization scheme that combines vision patches and text tokens. Through a thorough benchmarking of 46 closed-source and open-source LCVLMs, we provide a comprehensive analysis of the current models' vision-language long-context ability. Our results show that: i) performance on a single task is a weak proxy for overall long-context capability; ii) both closed-source and open-source models face challenges in long-context vision-language tasks, indicating substantial room for future improvement; iii) models with stronger reasoning ability tend to exhibit better long-context performance. By offering wide task coverage, various image types, and rigorous length control, MMLongBench provides the missing foundation for diagnosing and advancing the next generation of LCVLMs.
Rethinking Memory in AI: Taxonomy, Operations, Topics, and Future Directions
May 01, 2025Memory is a fundamental component of AI systems, underpinning large language models (LLMs) based agents. While prior surveys have focused on memory applications with LLMs, they often overlook the atomic operations that underlie memory dynamics. In this survey, we first categorize memory representations into parametric, contextual structured, and contextual unstructured and then introduce six fundamental memory operations: Consolidation, Updating, Indexing, Forgetting, Retrieval, and Compression. We systematically map these operations to the most relevant research topics across long-term, long-context, parametric modification, and multi-source memory. By reframing memory systems through the lens of atomic operations and representation types, this survey provides a structured and dynamic perspective on research, benchmark datasets, and tools related to memory in AI, clarifying the functional interplay in LLMs based agents while outlining promising directions for future research\footnote{The paper list, datasets, methods and tools are available at \href{https://github.com/Elvin-Yiming-Du/Survey_Memory_in_AI}{https://github.com/Elvin-Yiming-Du/Survey\_Memory\_in\_AI}.}.
Neutralizing Bias in LLM Reasoning using Entailment Graphs
Mar 14, 2025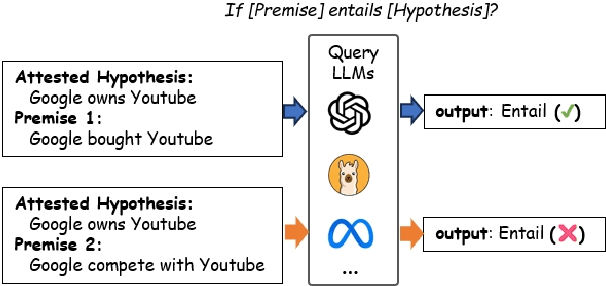


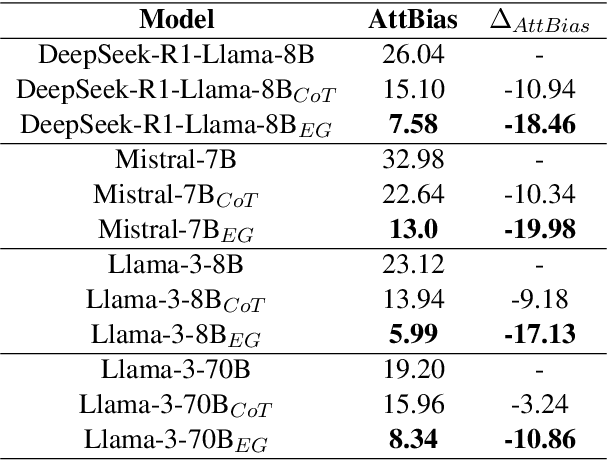
LLMs are often claimed to be capable of Natural Language Inference (NLI), which is widely regarded as a cornerstone of more complex forms of reasoning. However, recent works show that LLMs still suffer from hallucinations in NLI due to attestation bias, where LLMs overly rely on propositional memory to build shortcuts. To solve the issue, we design an unsupervised framework to construct counterfactual reasoning data and fine-tune LLMs to reduce attestation bias. To measure bias reduction, we build bias-adversarial variants of NLI datasets with randomly replaced predicates in premises while keeping hypotheses unchanged. Extensive evaluations show that our framework can significantly reduce hallucinations from attestation bias. Then, we further evaluate LLMs fine-tuned with our framework on original NLI datasets and their bias-neutralized versions, where original entities are replaced with randomly sampled ones. Extensive results show that our framework consistently improves inferential performance on both original and bias-neutralized NLI datasets.