 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Really is Commonsense Knowledge?
Nov 06, 2024



Commonsense datasets have been well developed in Natural Language Processing, mainly through crowdsource human annotation. However, there are debates on the genuineness of commonsense reasoning benchmarks. In specific, a significant portion of instances in some commonsense benchmarks do not concern commonsense knowledge. That problem would undermine the measurement of the true commonsense reasoning ability of evaluated models. It is also suggested that the problem originated from a blurry concept of commonsense knowledge, as distinguished from other types of knowledge. To demystify all of the above claims, in this study, we survey existing definitions of commonsense knowledge, ground into the three frameworks for defining concepts, and consolidate them into a multi-framework unified definition of commonsense knowledge (so-called consolidated definition). We then use the consolidated definition for annotations and experiments on the CommonsenseQA and CommonsenseQA 2.0 datasets to examine the above claims. Our study shows that there exists a large portion of non-commonsense-knowledge instances in the two datasets, and a large performance gap on these two subsets where Large Language Models (LLMs) perform worse on commonsense-knowledge instances.
DiscipLink: Unfolding Interdisciplinary Information Seeking Process via Human-AI Co-Exploration
Aug 01, 2024



Interdisciplinary studies often require researchers to explore literature in diverse branches of knowledge. Yet, navigating through the highly scattered knowledge from unfamiliar disciplines poses a significant challenge. In this paper, we introduce DiscipLink, a novel interactive system that facilitates collaboration between researchers and large language models (LLMs) in interdisciplinary information seeking (IIS). Based on users' topics of interest, DiscipLink initiates exploratory questions from the perspectives of possible relevant fields of study, and users can further tailor these questions. DiscipLink then supports users in searching and screening papers under selected questions by automatically expanding queries with disciplinary-specific terminologies, extracting themes from retrieved papers, and highlighting the connections between papers and questions. Our evaluation, comprising a within-subject comparative experiment and an open-ended exploratory study, reveals that DiscipLink can effectively support researchers in breaking down disciplinary boundaries and integrating scattered knowledge in diverse fields. The findings underscore the potential of LLM-powered tools in fostering information-seeking practices and bolstering interdisciplinary research.
Towards Human-AI Deliberation: Design and Evaluation of LLM-Empowered Deliberative AI for AI-Assisted Decision-Making
Mar 25, 2024



In AI-assisted decision-making, humans often passively review AI's suggestion and decide whether to accept or reject it as a whole. In such a paradigm, humans are found to rarely trigger analytical thinking and face difficulties in communicating the nuances of conflicting opinions to the AI when disagreements occur. To tackle this challenge, we propose Human-AI Deliberation, a novel framework to promote human reflection and discussion on conflicting human-AI opinions in decision-making. Based on theories in human deliberation, this framework engages humans and AI in dimension-level opinion elicitation, deliberative discussion, and decision updates. To empower AI with deliberative capabilities, we designed Deliberative AI, which leverages large language models (LLMs) as a bridge between humans and domain-specific models to enable flexible conversational interactions and faithful information provision. An exploratory evaluation on a graduate admissions task shows that Deliberative AI outperforms conventional explainable AI (XAI) assistants in improving humans' appropriate reliance and task performance. Based on a mixed-methods analysis of participant behavior, perception, user experience, and open-ended feedback, we draw implications for future AI-assisted decision tool design.
FARPLS: A Feature-Augmented Robot Trajectory Preference Labeling System to Assist Human Labelers' Preference Elicitation
Mar 10, 2024Preference-based learning aims to align robot task objectives with human values. One of the most common methods to infer human preferences is by pairwise comparisons of robot task trajectories. Traditional comparison-based preference labeling systems seldom support labelers to digest and identify critical differences between complex trajectories recorded in videos. Our formative study (N = 12) suggests that individuals may overlook non-salient task features and establish biased preference criteria during their preference elicitation process because of partial observations. In addition, they may experience mental fatigue when given many pairs to compare, causing their label quality to deteriorate. To mitigate these issues, we propose FARPLS, a Feature-Augmented Robot trajectory Preference Labeling System. FARPLS highlights potential outliers in a wide variety of task features that matter to humans and extracts the corresponding video keyframes for easy review and comparison. It also dynamically adjusts the labeling order according to users' familiarities, difficulties of the trajectory pair, and level of disagreements. At the same time, the system monitors labelers' consistency and provides feedback on labeling progress to keep labelers engaged. A between-subjects study (N = 42, 105 pairs of robot pick-and-place trajectories per person) shows that FARPLS can help users establish preference criteria more easily and notice more relevant details in the presented trajectories than the conventional interface. FARPLS also improves labeling consistency and engagement, mitigating challenges in preference elicitation without raising cognitive loads significantly
Beyond Recommender: An Exploratory Study of the Effects of Different AI Roles in AI-Assisted Decision Making
Mar 04, 2024



Artificial Intelligence (AI) is increasingly employed in various decision-making tasks, typically as a Recommender, providing recommendations that the AI deems correct. However, recent studies suggest this may diminish human analytical thinking and lead to humans' inappropriate reliance on AI, impairing the synergy in human-AI teams. In contrast, human advisors in group decision-making perform various roles, such as analyzing alternative options or criticizing decision-makers to encourage their critical thinking. This diversity of roles has not yet been empirically explored in AI assistance. In this paper, we examine three AI roles: Recommender, Analyzer, and Devil's Advocate, and evaluate their effects across two AI performance levels. Our results show each role's distinct strengths and limitations in task performance, reliance appropriateness, and user experience. Notably, the Recommender role is not always the most effective, especially if the AI performance level is low, the Analyzer role may be preferable. These insights offer valuable implications for designing AI assistants with adaptive functional roles according to different situations.
Charting the Future of AI in Project-Based Learning: A Co-Design Exploration with Students
Jan 29, 2024



The increasing use of Artificial Intelligence (AI) by students in learning presents new challenges for assessing their learning outcomes in project-based learning (PBL). This paper introduces a co-design study to explore the potential of students' AI usage data as a novel material for PBL assessment. We conducted workshops with 18 college students, encouraging them to speculate an alternative world where they could freely employ AI in PBL while needing to report this process to assess their skills and contributions. Our workshops yielded various scenarios of students' use of AI in PBL and ways of analyzing these uses grounded by students' vision of education goal transformation. We also found students with different attitudes toward AI exhibited distinct preferences in how to analyze and understand the use of AI. Based on these findings, we discuss future research opportunities on student-AI interactions and understanding AI-enhanced learning.
TypeDance: Creating Semantic Typographic Logos from Image through Personalized Generation
Jan 20, 2024



Semantic typographic logos harmoniously blend typeface and imagery to represent semantic concepts while maintaining legibility. Conventional methods using spatial composition and shape substitution are hindered by the conflicting requirement for achieving seamless spatial fusion between geometrically dissimilar typefaces and semantics. While recent advances made AI generation of semantic typography possible, the end-to-end approaches exclude designer involvement and disregard personalized design. This paper presents TypeDance, an AI-assisted tool incorporating design rationales with the generative model for personalized semantic typographic logo design. It leverages combinable design priors extracted from uploaded image exemplars and supports type-imagery mapping at various structural granularity, achieving diverse aesthetic designs with flexible control. Additionally, we instantiate a comprehensive design workflow in TypeDance, including ideation, selection, generation, evaluation, and iteration. A two-task user evaluation, including imitation and creation, confirmed the usability of TypeDance in design across different usage scenarios
ChoiceMates: Supporting Unfamiliar Online Decision-Making with Multi-Agent Conversational Interactions
Oct 02, 2023
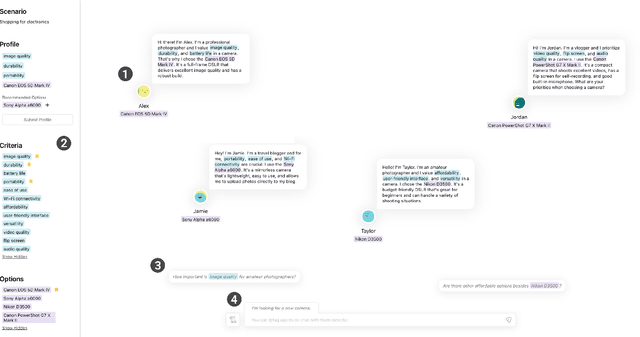
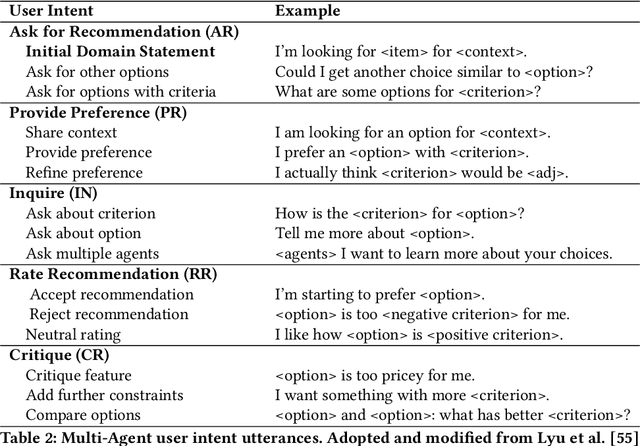

Unfamiliar decisions -- decisions where people lack adequate domain knowledge or expertise -- specifically increase the complexity and uncertainty of the process of searching for, understanding, and making decisions with online information. Through our formative study (n=14), we observed users' challenges in accessing diverse perspectives, identifying relevant information, and deciding the right moment to make the final decision. We present ChoiceMates, a system that enables conversations with a dynamic set of LLM-powered agents for a holistic domain understanding and efficient discovery and management of information to make decisions. Agents, as opinionated personas, flexibly join the conversation, not only providing responses but also conversing among themselves to elicit each agent's preferences. Our between-subjects study (n=36) comparing ChoiceMates to conventional web search and single-agent showed that ChoiceMates was more helpful in discovering, diving deeper, and managing information compared to Web with higher confidence. We also describe how participants utilized multi-agent conversations in their decision-making process.
Storyfier: Exploring Vocabulary Learning Support with Text Generation Models
Aug 07, 2023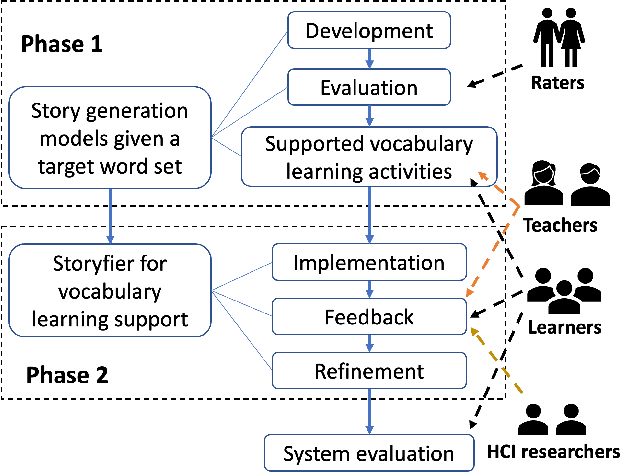
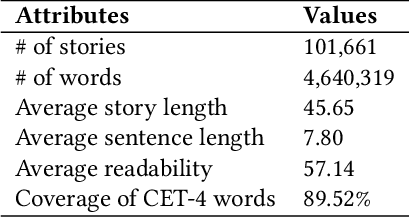
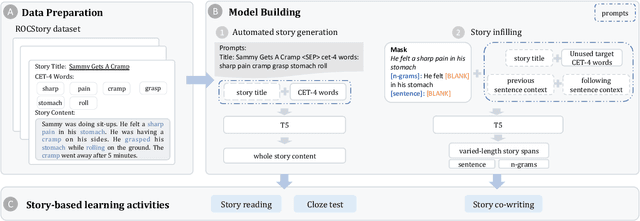

Vocabulary learning support tools have widely exploited existing materials, e.g., stories or video clips, as contexts to help users memorize each target word. However, these tools could not provide a coherent context for any target words of learners' interests, and they seldom help practice word usage. In this paper, we work with teachers and students to iteratively develop Storyfier, which leverages text generation models to enable learners to read a generated story that covers any target words, conduct a story cloze test, and use these words to write a new story with adaptive AI assistance. Our within-subjects study (N=28) shows that learners generally favor the generated stories for connecting target words and writing assistance for easing their learning workload. However, in the read-cloze-write learning sessions, participants using Storyfier perform worse in recalling and using target words than learning with a baseline tool without our AI features. We discuss insights into supporting learning tasks with generative models.
Competent but Rigid: Identifying the Gap in Empowering AI to Participate Equally in Group Decision-Making
Feb 17, 2023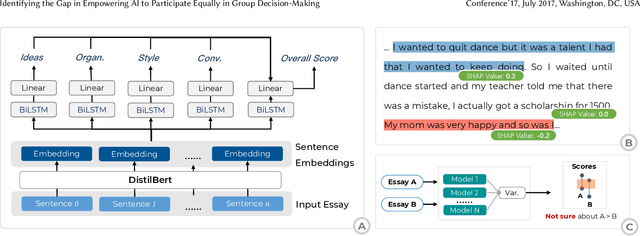

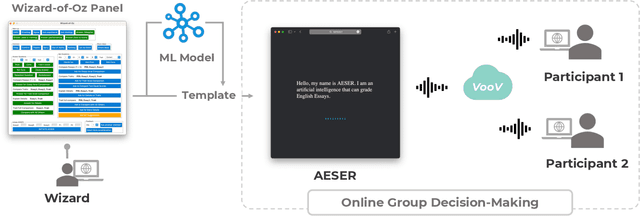

Existing research on human-AI collaborative decision-making focuses mainly on the interaction between AI and individual decision-makers. There is a limited understanding of how AI may perform in group decision-making. This paper presents a wizard-of-oz study in which two participants and an AI form a committee to rank three English essays. One novelty of our study is that we adopt a speculative design by endowing AI equal power to humans in group decision-making.We enable the AI to discuss and vote equally with other human members. We find that although the voice of AI is considered valuable, AI still plays a secondary role in the group because it cannot fully follow the dynamics of the discussion and make progressive contributions. Moreover, the divergent opinions of our participants regarding an "equal AI" shed light on the possible future of human-AI relations.