 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQumus: Realization of An Embodied AI Quantum Material Experimentalist
May 18, 2026While modern Large Language Models (LLMs) and agentic artificial intelligence (AI) have demonstrated transformative capabilities in digital domains, the realization of embodied AI capable of real-world scientific discovery remains a difficult frontier. The advancements are hindered by the inherent complexity of integrating high-level reasoning, multimodal information processing and real-time physical execution. Here we introduce Qumus, the first AI quantum materials experimentalist. Physically embodied within a robotic mini-laboratory, Qumus is an intelligent, multimodal, and multi-agent system designed for the creation and nano-processing of atomically thin two-dimensional (2D) materials and stacked van der Waals (vdW) structures. Qumus autonomously navigates the full scientific cycle, from hypothesis generation and protocol planning to multi-step experimental execution, result analysis and reporting, acting as an experimentalist. Markedly, the system has achieved, for the first time, the AI-creation of graphene, as well as the first AI-fabrication of complex nanodevices including atomically thin field-effect transistors via vdW stacking. Qumus excels at these tasks by demonstrating autonomous error correction and closed-loop experimentation. Our results establish a generalizable framework for self-improving embodied AI systems that learn directly from the quantum world, opening a pathway toward accelerated discovery in quantum materials, electronics and beyond.
From Fallback to Frontline: When Can LLMs be Superior Annotators of Human Perspectives?
Apr 20, 2026Although large language models (LLMs) are increasingly used as annotators at scale, they are typically treated as a pragmatic fallback rather than a faithful estimator of human perspectives. This work challenges that presumption. By framing perspective-taking as the estimation of a latent group-level judgment, we characterize the conditions under which modern LLMs can outperform human annotators, including in-group humans, when predicting aggregate subgroup opinions on subjective tasks, and show that these conditions are common in practice. This advantage arises from structural properties of LLMs as estimators, including low variance and reduced coupling between representation and processing biases, rather than any claim of lived experience. Our analysis identifies clear regimes where LLMs act as statistically superior frontline estimators, as well as principled limits where human judgment remains essential. These findings reposition LLMs from a cost-saving compromise to a principled tool for estimating collective human perspectives.
OilSAM2: Memory-Augmented SAM2 for Scalable SAR Oil Spill Detection
Mar 10, 2026Segmenting oil spills from Synthetic Aperture Radar (SAR) imagery remains challenging due to severe appearance variability, scale heterogeneity, and the absence of temporal continuity in real world monitoring scenarios. While foundation models such as Segment Anything (SAM) enable prompt driven segmentation, existing SAM based approaches operate on single images and cannot effectively reuse information across scenes. Memory augmented variants (e.g., SAM2) further assume temporal coherence, making them prone to semantic drift when applied to unordered SAR image collections. We propose OilSAM2, a memory augmented segmentation framework tailored for unordered SAR oil spill monitoring. OilSAM2 introduces a hierarchical feature aware multi scale memory bank that explicitly models texture, structure, and semantic level representations, enabling robust cross image information reuse. To mitigate memory drift, we further propose a structure semantic consistent memory update strategy that selectively refreshes memory based on semantic discrepancy and structural variation.Experiments on two public SAR oil spill datasets demonstrate that OilSAM2 achieves state of the art segmentation performance, delivering stable and accurate results under noisy SAR monitoring scenarios. The source code is available at https://github.com/Chenshuaiyu1120/OILSAM2.
Align When They Want, Complement When They Need! Human-Centered Ensembles for Adaptive Human-AI Collaboration
Feb 23, 2026In human-AI decision making, designing AI that complements human expertise has been a natural strategy to enhance human-AI collaboration, yet it often comes at the cost of decreased AI performance in areas of human strengths. This can inadvertently erode human trust and cause them to ignore AI advice precisely when it is most needed. Conversely, an aligned AI fosters trust yet risks reinforcing suboptimal human behavior and lowering human-AI team performance. In this paper, we start by identifying this fundamental tension between performance-boosting (i.e., complementarity) and trust-building (i.e., alignment) as an inherent limitation of the traditional approach for training a single AI model to assist human decision making. To overcome this, we introduce a novel human-centered adaptive AI ensemble that strategically toggles between two specialist AI models - the aligned model and the complementary model - based on contextual cues, using an elegantly simple yet provably near-optimal Rational Routing Shortcut mechanism. Comprehensive theoretical analyses elucidate why the adaptive AI ensemble is effective and when it yields maximum benefits. Moreover, experiments on both simulated and real-world data show that when humans are assisted by the adaptive AI ensemble in decision making, they can achieve significantly higher performance than when they are assisted by single AI models that are trained to either optimize for their independent performance or even the human-AI team performance.
Human-LLM Collaborative Feature Engineering for Tabular Data
Jan 28, 2026Large language models (LLMs) are increasingly used to automate feature engineering in tabular learning. Given task-specific information, LLMs can propose diverse feature transformation operations to enhance downstream model performance. However, current approaches typically assign the LLM as a black-box optimizer, responsible for both proposing and selecting operations based solely on its internal heuristics, which often lack calibrated estimations of operation utility and consequently lead to repeated exploration of low-yield operations without a principled strategy for prioritizing promising directions. In this paper, we propose a human-LLM collaborative feature engineering framework for tabular learning. We begin by decoupling the transformation operation proposal and selection processes, where LLMs are used solely to generate operation candidates, while the selection is guided by explicitly modeling the utility and uncertainty of each proposed operation. Since accurate utility estimation can be difficult especially in the early rounds of feature engineering, we design a mechanism within the framework that selectively elicits and incorporates human expert preference feedback, comparing which operations are more promising, into the selection process to help identify more effective operations. Our evaluations on both the synthetic study and the real user study demonstrate that the proposed framework improves feature engineering performance across a variety of tabular datasets and reduces users' cognitive load during the feature engineering process.
Assessing Automated Fact-Checking for Medical LLM Responses with Knowledge Graphs
Nov 16, 2025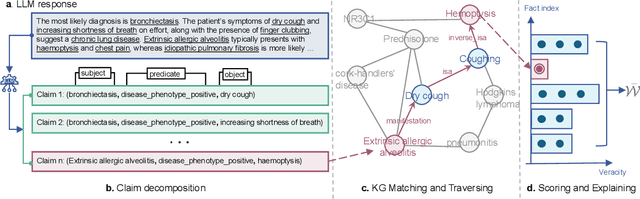
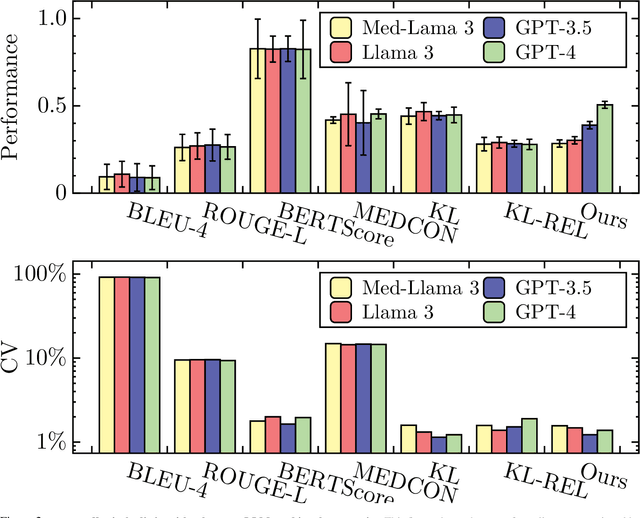
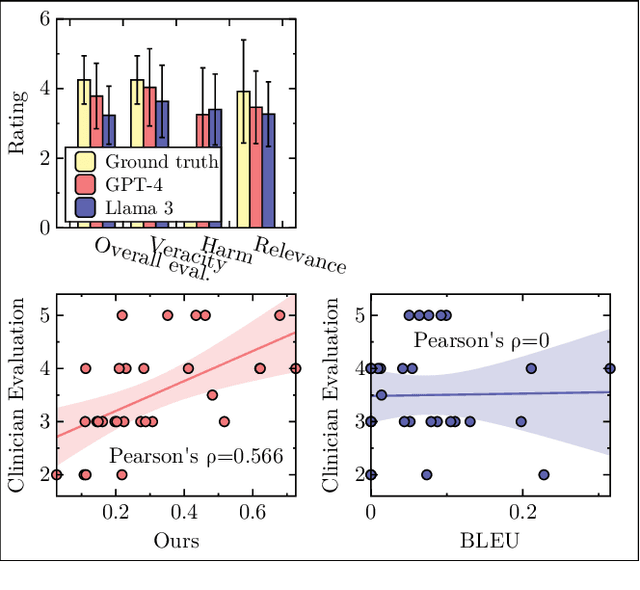
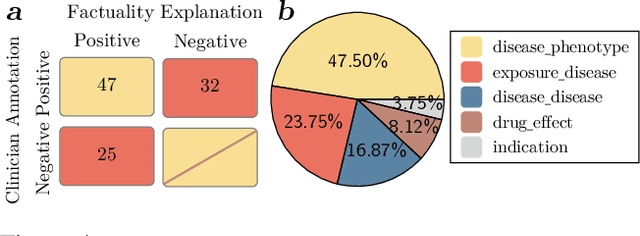
The recent proliferation of large language models (LLMs) holds the potential to revolutionize healthcare, with strong capabilities in diverse medical tasks. Yet, deploying LLMs in high-stakes healthcare settings requires rigorous verification and validation to understand any potential harm. This paper investigates the reliability and viability of using medical knowledge graphs (KGs) for the automated factuality evaluation of LLM-generated responses. To ground this investigation, we introduce FAITH, a framework designed to systematically probe the strengths and limitations of this KG-based approach. FAITH operates without reference answers by decomposing responses into atomic claims, linking them to a medical KG, and scoring them based on evidence paths. Experiments on diverse medical tasks with human subjective evaluations demonstrate that KG-grounded evaluation achieves considerably higher correlations with clinician judgments and can effectively distinguish LLMs with varying capabilities. It is also robust to textual variances. The inherent explainability of its scoring can further help users understand and mitigate the limitations of current LLMs. We conclude that while limitations exist, leveraging KGs is a prominent direction for automated factuality assessment in healthcare.
MMTok: Multimodal Coverage Maximization for Efficient Inference of VLMs
Aug 25, 2025Vision-Language Models (VLMs) demonstrate impressive performance in understanding visual content with language instruction by converting visual input to vision tokens. However, redundancy in vision tokens results in the degenerated inference efficiency of VLMs. While many algorithms have been proposed to reduce the number of vision tokens, most of them apply only unimodal information (i.e., vision/text) for pruning and ignore the inherent multimodal property of vision-language tasks. Moreover, it lacks a generic criterion that can be applied to different modalities. To mitigate this limitation, in this work, we propose to leverage both vision and text tokens to select informative vision tokens by the criterion of coverage. We first formulate the subset selection problem as a maximum coverage problem. Afterward, a subset of vision tokens is optimized to cover the text tokens and the original set of vision tokens, simultaneously. Finally, a VLM agent can be adopted to further improve the quality of text tokens for guiding vision pruning. The proposed method MMTok is extensively evaluated on benchmark datasets with different VLMs. The comparison illustrates that vision and text information are complementary, and combining multimodal information can surpass the unimodal baseline with a clear margin. Moreover, under the maximum coverage criterion on the POPE dataset, our method achieves a 1.87x speedup while maintaining 98.7% of the original performance on LLaVA-NeXT-13B. Furthermore, with only four vision tokens, it still preserves 87.7% of the original performance on LLaVA-1.5-7B. These results highlight the effectiveness of coverage in token selection.
Complex Logical Instruction Generation
Aug 12, 2025Instruction following has catalyzed the recent era of Large Language Models (LLMs) and is the foundational skill underpinning more advanced capabilities such as reasoning and agentic behaviors. As tasks grow more challenging, the logic structures embedded in natural language instructions becomes increasingly intricate. However, how well LLMs perform on such logic-rich instructions remains under-explored. We propose LogicIFGen and LogicIFEval. LogicIFGen is a scalable, automated framework for generating verifiable instructions from code functions, which can naturally express rich logic such as conditionals, nesting, recursion, and function calls. We further curate a collection of complex code functions and use LogicIFGen to construct LogicIFEval, a benchmark comprising 426 verifiable logic-rich instructions. Our experiments demonstrate that current state-of-the-art LLMs still struggle to correctly follow the instructions in LogicIFEval. Most LLMs can only follow fewer than 60% of the instructions, revealing significant deficiencies in the instruction-following ability. Code and Benchmark: https://github.com/mianzhang/LogicIF
Genome-Bench: A Scientific Reasoning Benchmark from Real-World Expert Discussions
May 26, 2025In this short report, we present an automated pipeline tailored for the genomics domain and introduce \textit{Genome-Bench}, a new benchmark constructed from over a decade of scientific forum discussions on genome engineering. Our pipeline transforms raw interactions into a reinforcement learning friendly multiple-choice questions format, supported by 3000+ high quality question answer pairs spanning foundational biology, experimental troubleshooting, tool usage, and beyond. To our knowledge, this is the first end-to-end pipeline for teaching LLMs to reason from scientific discussions, with promising potential for generalization across scientific domains beyond biology.
Which Agent Causes Task Failures and When? On Automated Failure Attribution of LLM Multi-Agent Systems
Apr 30, 2025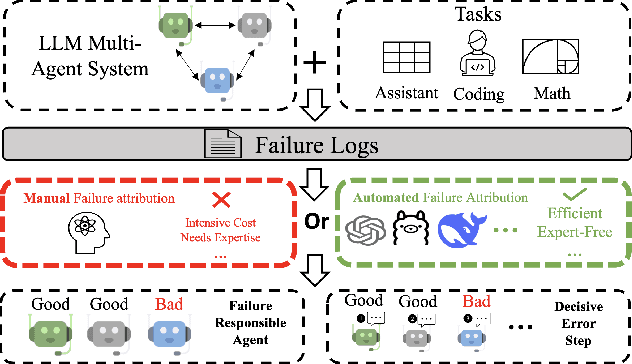
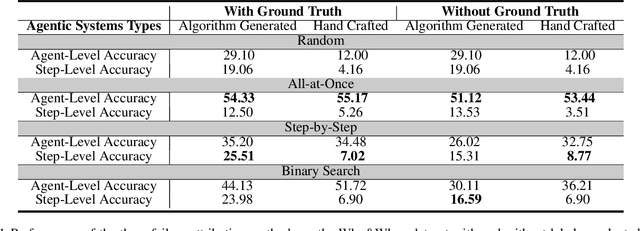
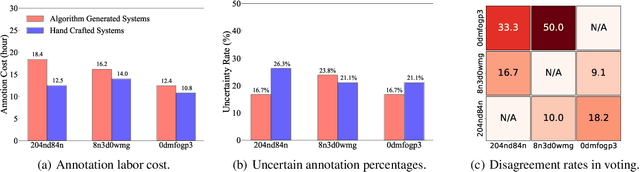

Failure attribution in LLM multi-agent systems-identifying the agent and step responsible for task failures-provides crucial clues for systems debugging but remains underexplored and labor-intensive. In this paper, we propose and formulate a new research area: automated failure attribution for LLM multi-agent systems. To support this initiative, we introduce the Who&When dataset, comprising extensive failure logs from 127 LLM multi-agent systems with fine-grained annotations linking failures to specific agents and decisive error steps. Using the Who&When, we develop and evaluate three automated failure attribution methods, summarizing their corresponding pros and cons. The best method achieves 53.5% accuracy in identifying failure-responsible agents but only 14.2% in pinpointing failure steps, with some methods performing below random. Even SOTA reasoning models, such as OpenAI o1 and DeepSeek R1, fail to achieve practical usability. These results highlight the task's complexity and the need for further research in this area. Code and dataset are available at https://github.com/mingyin1/Agents_Failure_Attribution