 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNetworkGym: Reinforcement Learning Environments for Multi-Access Traffic Management in Network Simulation
Oct 30, 2024



Mobile devices such as smartphones, laptops, and tablets can often connect to multiple access networks (e.g., Wi-Fi, LTE, and 5G) simultaneously. Recent advancements facilitate seamless integration of these connections below the transport layer, enhancing the experience for apps that lack inherent multi-path support. This optimization hinges on dynamically determining the traffic distribution across networks for each device, a process referred to as \textit{multi-access traffic splitting}. This paper introduces \textit{NetworkGym}, a high-fidelity network environment simulator that facilitates generating multiple network traffic flows and multi-access traffic splitting. This simulator facilitates training and evaluating different RL-based solutions for the multi-access traffic splitting problem. Our initial explorations demonstrate that the majority of existing state-of-the-art offline RL algorithms (e.g. CQL) fail to outperform certain hand-crafted heuristic policies on average. This illustrates the urgent need to evaluate offline RL algorithms against a broader range of benchmarks, rather than relying solely on popular ones such as D4RL. We also propose an extension to the TD3+BC algorithm, named Pessimistic TD3 (PTD3), and demonstrate that it outperforms many state-of-the-art offline RL algorithms. PTD3's behavioral constraint mechanism, which relies on value-function pessimism, is theoretically motivated and relatively simple to implement.
Advancing RAN Slicing with Offline Reinforcement Learning
Dec 16, 2023Dynamic radio resource management (RRM) in wireless networks presents significant challenges, particularly in the context of Radio Access Network (RAN) slicing. This technology, crucial for catering to varying user requirements, often grapples with complex optimization scenarios. Existing Reinforcement Learning (RL) approaches, while achieving good performance in RAN slicing, typically rely on online algorithms or behavior cloning. These methods necessitate either continuous environmental interactions or access to high-quality datasets, hindering their practical deployment. Towards addressing these limitations, this paper introduces offline RL to solving the RAN slicing problem, marking a significant shift towards more feasible and adaptive RRM methods. We demonstrate how offline RL can effectively learn near-optimal policies from sub-optimal datasets, a notable advancement over existing practices. Our research highlights the inherent flexibility of offline RL, showcasing its ability to adjust policy criteria without the need for additional environmental interactions. Furthermore, we present empirical evidence of the efficacy of offline RL in adapting to various service-level requirements, illustrating its potential in diverse RAN slicing scenarios.
CRNet: Image Super-Resolution Using A Convolutional Sparse Coding Inspired Network
Aug 03, 2019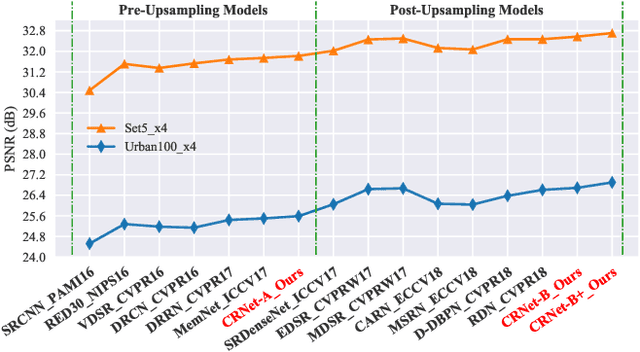
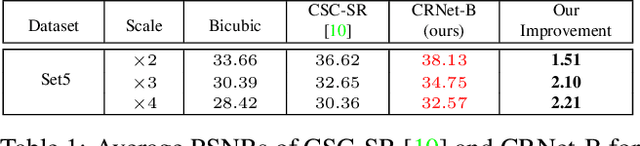

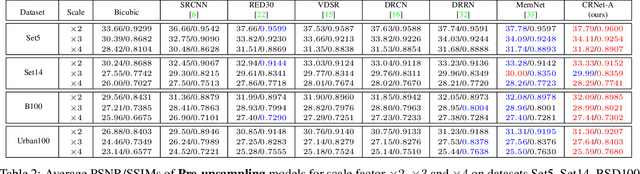
Convolutional Sparse Coding (CSC) has been attracting more and more attention in recent years, for making full use of image global correlation to improve performance on various computer vision applications. However, very few studies focus on solving CSC based image Super-Resolution (SR) problem. As a consequence, there is no significant progress in this area over a period of time. In this paper, we exploit the natural connection between CSC and Convolutional Neural Networks (CNN) to address CSC based image SR. Specifically, Convolutional Iterative Soft Thresholding Algorithm (CISTA) is introduced to solve CSC problem and it can be implemented using CNN architectures. Then we develop a novel CSC based SR framework analogy to the traditional SC based SR methods. Two models inspired by this framework are proposed for pre-/post-upsampling SR, respectively. Compared with recent state-of-the-art SR methods, both of our proposed models show superior performance in terms of both quantitative and qualitative measurements.
Image Super-Resolution via RL-CSC: When Residual Learning Meets Convolutional Sparse Coding
Dec 31, 2018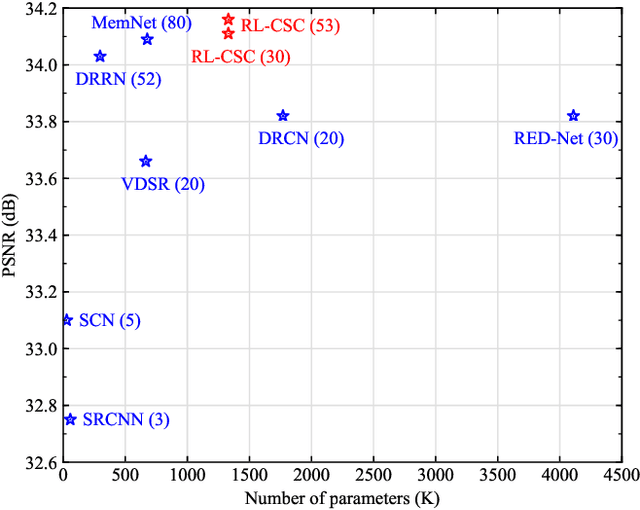

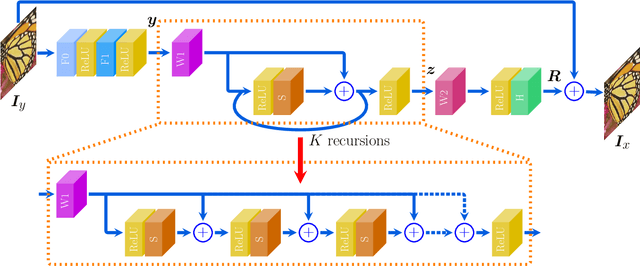
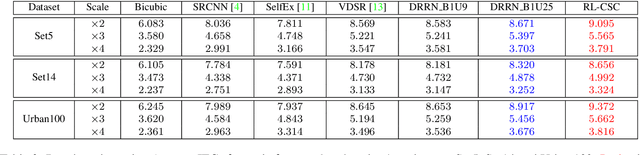
We propose a simple yet effective model for Single Image Super-Resolution (SISR), by combining the merits of Residual Learning and Convolutional Sparse Coding (RL-CSC). Our model is inspired by the Learned Iterative Shrinkage-Threshold Algorithm (LISTA). We extend LISTA to its convolutional version and build the main part of our model by strictly following the convolutional form, which improves the network's interpretability. Specifically, the convolutional sparse codings of input feature maps are learned in a recursive manner, and high-frequency information can be recovered from these CSCs. More importantly, residual learning is applied to alleviate the training difficulty when the network goes deeper. Extensive experiments on benchmark datasets demonstrate the effectiveness of our method. RL-CSC (30 layers) outperforms several recent state-of-the-arts, e.g., DRRN (52 layers) and MemNet (80 layers) in both accuracy and visual qualities. Codes and more results are available at https://github.com/axzml/RL-CSC.