 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Multi-objective Prompt Optimization via Pure-exploration Bandits
May 14, 2026Prompt engineering has become central to eliciting the capabilities of large language models (LLMs). At its core lies prompt selection -- efficiently identifying the most effective prompts. However, most prior investigations overlook a key challenge: the inherently multi-faceted nature of prompt performance, which cannot be captured by a single metric. To fill this gap, we study the multi-objective prompt selection problem under two practical settings: Pareto prompt set recovery and best feasible prompt identification. Casting the problem into the pure-exploration bandits framework, we adapt provably efficient algorithms from multi-objective bandits and further introduce a novel design for best feasible arm identification in structured bandits, with theoretical guarantees on the identification error in the linear case. Extensive experiments across multiple LLMs show that the bandit-based approaches yield significant improvements over baselines, establishing a principled and efficient framework for multi-objective prompt optimization.
Following the Diagnostic Trace: Visual Cognition-guided Cooperative Network for Chest X-Ray Diagnosis
Feb 25, 2026Computer-aided diagnosis (CAD) has significantly advanced automated chest X-ray diagnosis but remains isolated from clinical workflows and lacks reliable decision support and interpretability. Human-AI collaboration seeks to enhance the reliability of diagnostic models by integrating the behaviors of controllable radiologists. However, the absence of interactive tools seamlessly embedded within diagnostic routines impedes collaboration, while the semantic gap between radiologists' decision-making patterns and model representations further limits clinical adoption. To overcome these limitations, we propose a visual cognition-guided collaborative network (VCC-Net) to achieve the cooperative diagnostic paradigm. VCC-Net centers on visual cognition (VC) and employs clinically compatible interfaces, such as eye-tracking or the mouse, to capture radiologists' visual search traces and attention patterns during diagnosis. VCC-Net employs VC as a spatial cognition guide, learning hierarchical visual search strategies to localize diagnostically key regions. A cognition-graph co-editing module subsequently integrates radiologist VC with model inference to construct a disease-aware graph. The module captures dependencies among anatomical regions and aligns model representations with VC-driven features, mitigating radiologist bias and facilitating complementary, transparent decision-making. Experiments on the public datasets SIIM-ACR, EGD-CXR, and self-constructed TB-Mouse dataset achieved classification accuracies of 88.40%, 85.05%, and 92.41%, respectively. The attention maps produced by VCC-Net exhibit strong concordance with radiologists' gaze distributions, demonstrating a mutual reinforcement of radiologist and model inference. The code is available at https://github.com/IPMI-NWU/VCC-Net.
Lean Clients, Full Accuracy: Hybrid Zeroth- and First-Order Split Federated Learning
Jan 14, 2026Split Federated Learning (SFL) enables collaborative training between resource-constrained edge devices and a compute-rich server. Communication overhead is a central issue in SFL and can be mitigated with auxiliary networks. Yet, the fundamental client-side computation challenge remains, as back-propagation requires substantial memory and computation costs, severely limiting the scale of models that edge devices can support. To enable more resource-efficient client computation and reduce the client-server communication, we propose HERON-SFL, a novel hybrid optimization framework that integrates zeroth-order (ZO) optimization for local client training while retaining first-order (FO) optimization on the server. With the assistance of auxiliary networks, ZO updates enable clients to approximate local gradients using perturbed forward-only evaluations per step, eliminating memory-intensive activation caching and avoiding explicit gradient computation in the traditional training process. Leveraging the low effective rank assumption, we theoretically prove that HERON-SFL's convergence rate is independent of model dimensionality, addressing a key scalability concern common to ZO algorithms. Empirically, on ResNet training and language model (LM) fine-tuning tasks, HERON-SFL matches benchmark accuracy while reducing client peak memory by up to 64% and client-side compute cost by up to 33% per step, substantially expanding the range of models that can be trained or adapted on resource-limited devices.
Tele-LLM-Hub: Building Context-Aware Multi-Agent LLM Systems for Telecom Networks
Nov 18, 2025This paper introduces Tele-LLM-Hub, a user friendly low-code solution for rapid prototyping and deployment of context aware multi-agent (MA) Large Language Model (LLM) systems tailored for 5G and beyond. As telecom wireless networks become increasingly complex, intelligent LLM applications must share a domainspecific understanding of network state. We propose TeleMCP, the Telecom Model Context Protocol, to enable structured and context-rich communication between agents in telecom environments. Tele-LLM-Hub actualizes TeleMCP through a low-code interface that supports agent creation, workflow composition, and interaction with software stacks such as srsRAN. Key components include a direct chat interface, a repository of pre-built systems, an Agent Maker leveraging finetuning with our RANSTRUCT framework, and an MA-Maker for composing MA workflows. The goal of Tele-LLM-Hub is to democratize the design of contextaware MA systems and accelerate innovation in next-generation wireless networks.
Graph Prompting for Graph Learning Models: Recent Advances and Future Directions
Jun 10, 2025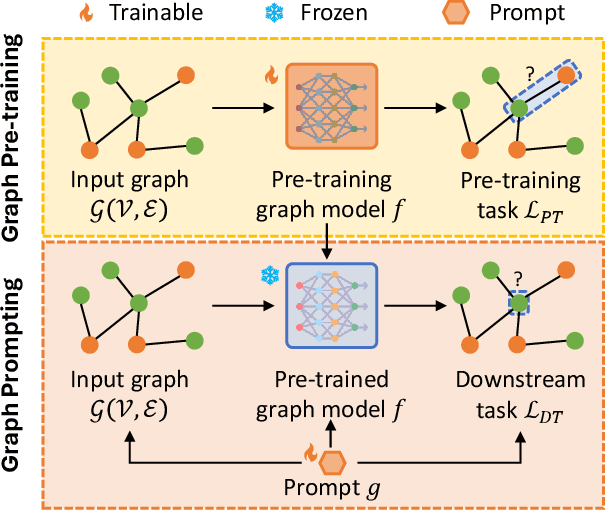
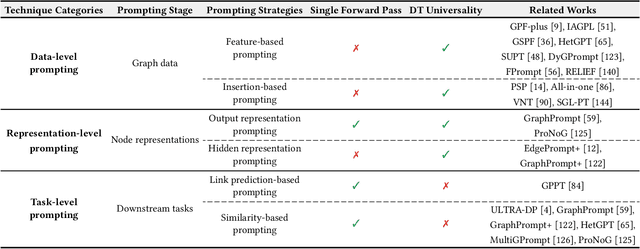
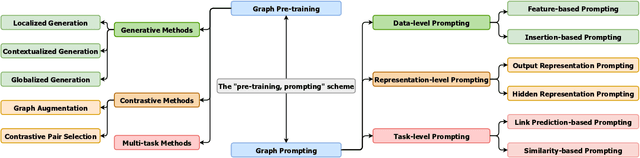
Graph learning models have demonstrated great prowess in learning expressive representations from large-scale graph data in a wide variety of real-world scenarios. As a prevalent strategy for training powerful graph learning models, the "pre-training, adaptation" scheme first pre-trains graph learning models on unlabeled graph data in a self-supervised manner and then adapts them to specific downstream tasks. During the adaptation phase, graph prompting emerges as a promising approach that learns trainable prompts while keeping the pre-trained graph learning models unchanged. In this paper, we present a systematic review of recent advancements in graph prompting. First, we introduce representative graph pre-training methods that serve as the foundation step of graph prompting. Next, we review mainstream techniques in graph prompting and elaborate on how they design learnable prompts for graph prompting. Furthermore, we summarize the real-world applications of graph prompting from different domains. Finally, we discuss several open challenges in existing studies with promising future directions in this field.
On the Convergence Analysis of Muon
May 29, 2025The majority of parameters in neural networks are naturally represented as matrices. However, most commonly used optimizers treat these matrix parameters as flattened vectors during optimization, potentially overlooking their inherent structural properties. Recently, an optimizer called Muon has been proposed, specifically designed to optimize matrix-structured parameters. Extensive empirical evidence shows that Muon can significantly outperform traditional optimizers when training neural networks. Nonetheless, the theoretical understanding of Muon's convergence behavior and the reasons behind its superior performance remain limited. In this work, we present a comprehensive convergence rate analysis of Muon and its comparison with Gradient Descent (GD). We further characterize the conditions under which Muon can outperform GD. Our theoretical results reveal that Muon can benefit from the low-rank and approximate blockwise diagonal structure of Hessian matrices -- phenomena widely observed in practical neural network training. Our experimental results support and corroborate the theoretical findings.
MAPLE: Many-Shot Adaptive Pseudo-Labeling for In-Context Learning
May 22, 2025In-Context Learning (ICL) empowers Large Language Models (LLMs) to tackle diverse tasks by incorporating multiple input-output examples, known as demonstrations, into the input of LLMs. More recently, advancements in the expanded context windows of LLMs have led to many-shot ICL, which uses hundreds of demonstrations and outperforms few-shot ICL, which relies on fewer examples. However, this approach is often hindered by the high cost of obtaining large amounts of labeled data. To address this challenge, we propose Many-Shot Adaptive Pseudo-LabEling, namely MAPLE, a novel influence-based many-shot ICL framework that utilizes pseudo-labeled samples to compensate for the lack of label information. We first identify a subset of impactful unlabeled samples and perform pseudo-labeling on them by querying LLMs. These pseudo-labeled samples are then adaptively selected and tailored to each test query as input to improve the performance of many-shot ICL, without significant labeling costs. Extensive experiments on real-world datasets demonstrate the effectiveness of our framework, showcasing its ability to enhance LLM adaptability and performance with limited labeled data.
Augmenting Online RL with Offline Data is All You Need: A Unified Hybrid RL Algorithm Design and Analysis
May 19, 2025This paper investigates a hybrid learning framework for reinforcement learning (RL) in which the agent can leverage both an offline dataset and online interactions to learn the optimal policy. We present a unified algorithm and analysis and show that augmenting confidence-based online RL algorithms with the offline dataset outperforms any pure online or offline algorithm alone and achieves state-of-the-art results under two learning metrics, i.e., sub-optimality gap and online learning regret. Specifically, we show that our algorithm achieves a sub-optimality gap $\tilde{O}(\sqrt{1/(N_0/\mathtt{C}(\pi^*|\rho)+N_1}) )$, where $\mathtt{C}(\pi^*|\rho)$ is a new concentrability coefficient, $N_0$ and $N_1$ are the numbers of offline and online samples, respectively. For regret minimization, we show that it achieves a constant $\tilde{O}( \sqrt{N_1/(N_0/\mathtt{C}(\pi^{-}|\rho)+N_1)} )$ speed-up compared to pure online learning, where $\mathtt{C}(\pi^-|\rho)$ is the concentrability coefficient over all sub-optimal policies. Our results also reveal an interesting separation on the desired coverage properties of the offline dataset for sub-optimality gap minimization and regret minimization. We further validate our theoretical findings in several experiments in special RL models such as linear contextual bandits and Markov decision processes (MDPs).
FedHERO: A Federated Learning Approach for Node Classification Task on Heterophilic Graphs
Apr 29, 2025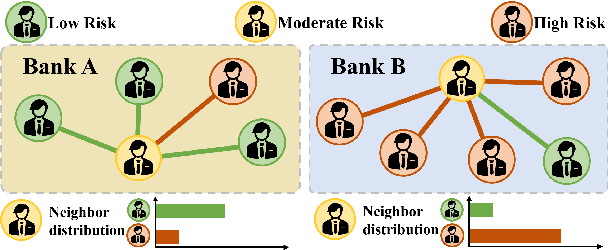

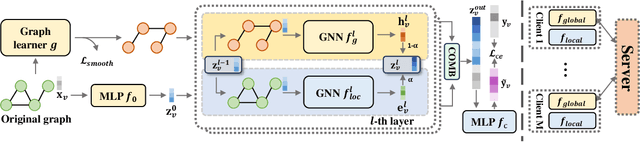
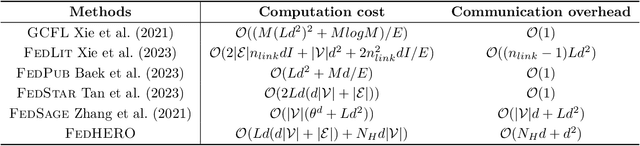
Federated Graph Learning (FGL) empowers clients to collaboratively train Graph neural networks (GNNs) in a distributed manner while preserving data privacy. However, FGL methods usually require that the graph data owned by all clients is homophilic to ensure similar neighbor distribution patterns of nodes. Such an assumption ensures that the learned knowledge is consistent across the local models from all clients. Therefore, these local models can be properly aggregated as a global model without undermining the overall performance. Nevertheless, when the neighbor distribution patterns of nodes vary across different clients (e.g., when clients hold graphs with different levels of heterophily), their local models may gain different and even conflict knowledge from their node-level predictive tasks. Consequently, aggregating these local models usually leads to catastrophic performance deterioration on the global model. To address this challenge, we propose FedHERO, an FGL framework designed to harness and share insights from heterophilic graphs effectively. At the heart of FedHERO is a dual-channel GNN equipped with a structure learner, engineered to discern the structural knowledge encoded in the local graphs. With this specialized component, FedHERO enables the local model for each client to identify and learn patterns that are universally applicable across graphs with different patterns of node neighbor distributions. FedHERO not only enhances the performance of individual client models by leveraging both local and shared structural insights but also sets a new precedent in this field to effectively handle graph data with various node neighbor distribution patterns. We conduct extensive experiments to validate the superior performance of FedHERO against existing alternatives.
A Survey of Scaling in Large Language Model Reasoning
Apr 02, 2025The rapid advancements in large Language models (LLMs) have significantly enhanced their reasoning capabilities, driven by various strategies such as multi-agent collaboration. However, unlike the well-established performance improvements achieved through scaling data and model size, the scaling of reasoning in LLMs is more complex and can even negatively impact reasoning performance, introducing new challenges in model alignment and robustness. In this survey, we provide a comprehensive examination of scaling in LLM reasoning, categorizing it into multiple dimensions and analyzing how and to what extent different scaling strategies contribute to improving reasoning capabilities. We begin by exploring scaling in input size, which enables LLMs to process and utilize more extensive context for improved reasoning. Next, we analyze scaling in reasoning steps that improves multi-step inference and logical consistency. We then examine scaling in reasoning rounds, where iterative interactions refine reasoning outcomes. Furthermore, we discuss scaling in training-enabled reasoning, focusing on optimization through iterative model improvement. Finally, we review applications of scaling across domains and outline future directions for further advancing LLM reasoning. By synthesizing these diverse perspectives, this survey aims to provide insights into how scaling strategies fundamentally enhance the reasoning capabilities of LLMs and further guide the development of next-generation AI systems.