 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHiPER: Hierarchical Reinforcement Learning with Explicit Credit Assignment for Large Language Model Agents
Feb 18, 2026Training LLMs as interactive agents for multi-turn decision-making remains challenging, particularly in long-horizon tasks with sparse and delayed rewards, where agents must execute extended sequences of actions before receiving meaningful feedback. Most existing reinforcement learning (RL) approaches model LLM agents as flat policies operating at a single time scale, selecting one action at each turn. In sparse-reward settings, such flat policies must propagate credit across the entire trajectory without explicit temporal abstraction, which often leads to unstable optimization and inefficient credit assignment. We propose HiPER, a novel Hierarchical Plan-Execute RL framework that explicitly separates high-level planning from low-level execution. HiPER factorizes the policy into a high-level planner that proposes subgoals and a low-level executor that carries them out over multiple action steps. To align optimization with this structure, we introduce a key technique called hierarchical advantage estimation (HAE), which carefully assigns credit at both the planning and execution levels. By aggregating returns over the execution of each subgoal and coordinating updates across the two levels, HAE provides an unbiased gradient estimator and provably reduces variance compared to flat generalized advantage estimation. Empirically, HiPER achieves state-of-the-art performance on challenging interactive benchmarks, reaching 97.4\% success on ALFWorld and 83.3\% on WebShop with Qwen2.5-7B-Instruct (+6.6\% and +8.3\% over the best prior method), with especially large gains on long-horizon tasks requiring multiple dependent subtasks. These results highlight the importance of explicit hierarchical decomposition for scalable RL training of multi-turn LLM agents.
DISPO: Enhancing Training Efficiency and Stability in Reinforcement Learning for Large Language Model Mathematical Reasoning
Feb 01, 2026Reinforcement learning with verifiable rewards has emerged as a promising paradigm for enhancing the reasoning capabilities of large language models particularly in mathematics. Current approaches in this domain present a clear trade-off: PPO-style methods (e.g., GRPO/DAPO) offer training stability but exhibit slow learning trajectories due to their trust-region constraints on policy updates, while REINFORCE-style approaches (e.g., CISPO) demonstrate improved learning efficiency but suffer from performance instability as they clip importance sampling weights while still permitting non-zero gradients outside the trust-region. To address these limitations, we introduce DISPO, a simple yet effective REINFORCE-style algorithm that decouples the up-clipping and down-clipping of importance sampling weights for correct and incorrect responses, yielding four controllable policy update regimes. Through targeted ablations, we uncover how each regime impacts training: for correct responses, weights >1 increase the average token entropy (i.e., exploration) while weights <1 decrease it (i.e., distillation) -- both beneficial but causing gradual performance degradation when excessive. For incorrect responses, overly restrictive clipping triggers sudden performance collapse through repetitive outputs (when weights >1) or vanishing response lengths (when weights <1). By separately tuning these four clipping parameters, DISPO maintains the exploration-distillation balance while preventing catastrophic failures, achieving 61.04% on AIME'24 (vs. 55.42% CISPO and 50.21% DAPO) with similar gains across various benchmarks and models.
Direct Preference Optimization with Rating Information: Practical Algorithms and Provable Gains
Jan 31, 2026The class of direct preference optimization (DPO) algorithms has emerged as a promising approach for solving the alignment problem in foundation models. These algorithms work with very limited feedback in the form of pairwise preferences and fine-tune models to align with these preferences without explicitly learning a reward model. While the form of feedback used by these algorithms makes the data collection process easy and relatively more accurate, its ambiguity in terms of the quality of responses could have negative implications. For example, it is not clear if a decrease (increase) in the likelihood of preferred (dispreferred) responses during the execution of these algorithms could be interpreted as a positive or negative phenomenon. In this paper, we study how to design algorithms that can leverage additional information in the form of rating gap, which informs the learner how much the chosen response is better than the rejected one. We present new algorithms that can achieve faster statistical rates than DPO in presence of accurate rating gap information. Moreover, we theoretically prove and empirically show that the performance of our algorithms is robust to inaccuracy in rating gaps. Finally, we demonstrate the solid performance of our methods in comparison to a number of DPO-style algorithms across a wide range of LLMs and evaluation benchmarks.
SPIRE: Conditional Personalization for Federated Diffusion Generative Models
Jun 14, 2025Recent advances in diffusion models have revolutionized generative AI, but their sheer size makes on device personalization, and thus effective federated learning (FL), infeasible. We propose Shared Backbone Personal Identity Representation Embeddings (SPIRE), a framework that casts per client diffusion based generation as conditional generation in FL. SPIRE factorizes the network into (i) a high capacity global backbone that learns a population level score function and (ii) lightweight, learnable client embeddings that encode local data statistics. This separation enables parameter efficient finetuning that touches $\leq 0.01\%$ of weights. We provide the first theoretical bridge between conditional diffusion training and maximum likelihood estimation in Gaussian mixture models. For a two component mixture we prove that gradient descent on the DDPM with respect to mixing weights loss recovers the optimal mixing weights and enjoys dimension free error bounds. Our analysis also hints at how client embeddings act as biases that steer a shared score network toward personalized distributions. Empirically, SPIRE matches or surpasses strong baselines during collaborative pretraining, and vastly outperforms them when adapting to unseen clients, reducing Kernel Inception Distance while updating only hundreds of parameters. SPIRE further mitigates catastrophic forgetting and remains robust across finetuning learning rate and epoch choices.
Cost-Aware Optimal Pairwise Pure Exploration
Mar 10, 2025Pure exploration is one of the fundamental problems in multi-armed bandits (MAB). However, existing works mostly focus on specific pure exploration tasks, without a holistic view of the general pure exploration problem. This work fills this gap by introducing a versatile framework to study pure exploration, with a focus on identifying the pairwise relationships between targeted arm pairs. Moreover, unlike existing works that only optimize the stopping time (i.e., sample complexity), this work considers that arms are associated with potentially different costs and targets at optimizing the cumulative cost that occurred during learning. Under the general framework of pairwise pure exploration with arm-specific costs, a performance lower bound is derived. Then, a novel algorithm, termed CAET (Cost-Aware Pairwise Exploration Task), is proposed. CAET builds on the track-and-stop principle with a novel design to handle the arm-specific costs, which can potentially be zero and thus represent a very challenging case. Theoretical analyses prove that the performance of CAET approaches the lower bound asymptotically. Special cases are further discussed, including an extension to regret minimization, which is another major focus of MAB. The effectiveness and efficiency of CAET are also verified through experimental results under various settings.
Path-Guided Particle-based Sampling
Dec 04, 2024

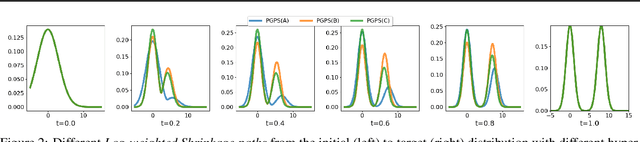

Particle-based Bayesian inference methods by sampling from a partition-free target (posterior) distribution, e.g., Stein variational gradient descent (SVGD), have attracted significant attention. We propose a path-guided particle-based sampling~(PGPS) method based on a novel Log-weighted Shrinkage (LwS) density path linking an initial distribution to the target distribution. We propose to utilize a Neural network to learn a vector field motivated by the Fokker-Planck equation of the designed density path. Particles, initiated from the initial distribution, evolve according to the ordinary differential equation defined by the vector field. The distribution of these particles is guided along a density path from the initial distribution to the target distribution. The proposed LwS density path allows for an efficient search of modes of the target distribution while canonical methods fail. We theoretically analyze the Wasserstein distance of the distribution of the PGPS-generated samples and the target distribution due to approximation and discretization errors. Practically, the proposed PGPS-LwS method demonstrates higher Bayesian inference accuracy and better calibration ability in experiments conducted on both synthetic and real-world Bayesian learning tasks, compared to baselines, such as SVGD and Langevin dynamics, etc.
On the Learn-to-Optimize Capabilities of Transformers in In-Context Sparse Recovery
Oct 17, 2024An intriguing property of the Transformer is its ability to perform in-context learning (ICL), where the Transformer can solve different inference tasks without parameter updating based on the contextual information provided by the corresponding input-output demonstration pairs. It has been theoretically proved that ICL is enabled by the capability of Transformers to perform gradient-descent algorithms (Von Oswald et al., 2023a; Bai et al., 2024). This work takes a step further and shows that Transformers can perform learning-to-optimize (L2O) algorithms. Specifically, for the ICL sparse recovery (formulated as LASSO) tasks, we show that a K-layer Transformer can perform an L2O algorithm with a provable convergence rate linear in K. This provides a new perspective explaining the superior ICL capability of Transformers, even with only a few layers, which cannot be achieved by the standard gradient-descent algorithms. Moreover, unlike the conventional L2O algorithms that require the measurement matrix involved in training to match that in testing, the trained Transformer is able to solve sparse recovery problems generated with different measurement matrices. Besides, Transformers as an L2O algorithm can leverage structural information embedded in the training tasks to accelerate its convergence during ICL, and generalize across different lengths of demonstration pairs, where conventional L2O algorithms typically struggle or fail. Such theoretical findings are supported by our experimental results.
Data-adaptive Differentially Private Prompt Synthesis for In-Context Learning
Oct 15, 2024Large Language Models (LLMs) rely on the contextual information embedded in examples/demonstrations to perform in-context learning (ICL). To mitigate the risk of LLMs potentially leaking private information contained in examples in the prompt, we introduce a novel data-adaptive differentially private algorithm called AdaDPSyn to generate synthetic examples from the private dataset and then use these synthetic examples to perform ICL. The objective of AdaDPSyn is to adaptively adjust the noise level in the data synthesis mechanism according to the inherent statistical properties of the data, thereby preserving high ICL accuracy while maintaining formal differential privacy guarantees. A key innovation in AdaDPSyn is the Precision-Focused Iterative Radius Reduction technique, which dynamically refines the aggregation radius - the scope of data grouping for noise addition - based on patterns observed in data clustering, thereby minimizing the amount of additive noise. We conduct extensive experiments on standard benchmarks and compare AdaDPSyn with DP few-shot generation algorithm (Tang et al., 2023). The experiments demonstrate that AdaDPSyn not only outperforms DP few-shot generation, but also maintains high accuracy levels close to those of non-private baselines, providing an effective solution for ICL with privacy protection.
On the Training Convergence of Transformers for In-Context Classification
Oct 15, 2024While transformers have demonstrated impressive capacities for in-context learning (ICL) in practice, theoretical understanding of the underlying mechanism enabling transformers to perform ICL is still in its infant stage. This work aims to theoretically study the training dynamics of transformers for in-context classification tasks. We demonstrate that, for in-context classification of Gaussian mixtures under certain assumptions, a single-layer transformer trained via gradient descent converges to a globally optimal model at a linear rate. We further quantify the impact of the training and testing prompt lengths on the ICL inference error of the trained transformer. We show that when the lengths of training and testing prompts are sufficiently large, the prediction of the trained transformer approaches the Bayes-optimal classifier. Experimental results corroborate the theoretical findings.
Transformers learn variable-order Markov chains in-context
Oct 07, 2024Large language models have demonstrated impressive in-context learning (ICL) capability. However, it is still unclear how the underlying transformers accomplish it, especially in more complex scenarios. Toward this goal, several recent works studied how transformers learn fixed-order Markov chains (FOMC) in context, yet natural languages are more suitably modeled by variable-order Markov chains (VOMC), i.e., context trees (CTs). In this work, we study the ICL of VOMC by viewing language modeling as a form of data compression and focus on small alphabets and low-order VOMCs. This perspective allows us to leverage mature compression algorithms, such as context-tree weighting (CTW) and prediction by partial matching (PPM) algorithms as baselines, the former of which is Bayesian optimal for a class of CTW priors. We empirically observe a few phenomena: 1) Transformers can indeed learn to compress VOMC in-context, while PPM suffers significantly; 2) The performance of transformers is not very sensitive to the number of layers, and even a two-layer transformer can learn in-context quite well; and 3) Transformers trained and tested on non-CTW priors can significantly outperform the CTW algorithm. To explain these phenomena, we analyze the attention map of the transformers and extract two mechanisms, on which we provide two transformer constructions: 1) A construction with $D+2$ layers that can mimic the CTW algorithm accurately for CTs of maximum order $D$, 2) A 2-layer transformer that utilizes the feed-forward network for probability blending. One distinction from the FOMC setting is that a counting mechanism appears to play an important role. We implement these synthetic transformer layers and show that such hybrid transformers can match the ICL performance of transformers, and more interestingly, some of them can perform even better despite the much-reduced parameter sets.