 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecocted Experience Improves Test-Time Inference in LLM Agents
Apr 06, 2026There is growing interest in improving LLMs without updating model parameters. One well-established direction is test-time scaling, where increased inference-time computation (e.g., longer reasoning, sampling, or search) is used to improve performance. However, for complex reasoning and agentic tasks, naively scaling test-time compute can substantially increase cost and still lead to wasted budget on suboptimal exploration. In this paper, we explore \emph{context} as a complementary scaling axis for improving LLM performance, and systematically study how to construct better inputs that guide reasoning through \emph{experience}. We show that effective context construction critically depends on \emph{decocted experience}. We present a detailed analysis of experience-augmented agents, studying how to derive context from experience, how performance scales with accumulated experience, what characterizes good context, and which data structures best support context construction. We identify \emph{decocted experience} as a key mechanism for effective context construction: extracting essence from experience, organizing it coherently, and retrieving salient information to build effective context. We validate our findings across reasoning and agentic tasks, including math reasoning, web browsing, and software engineering.
Tracking without Seeing: Geospatial Inference using Encrypted Traffic from Distributed Nodes
Mar 29, 2026Accurate observation of dynamic environments traditionally relies on synthesizing raw, signal-level information from multiple distributed sensors. This work investigates an alternative approach: performing geospatial inference using only encrypted packet-level information, without access to the raw sensory data. We further explore how this indirect information can be fused with directly available sensory data to extend overall inference capabilities. We introduce GraySense, a learning-based framework that performs geospatial object tracking by analyzing encrypted wireless video transmission traffic, such as packet sizes, from cameras with inaccessible streams. GraySense leverages the inherent relationship between scene dynamics and transmitted packet sizes to infer object motion. The framework consists of two stages: (1) a Packet Grouping module that identifies frame boundaries and estimates frame sizes from encrypted network traffic, and (2) a Tracker module, based on a Transformer encoder with a recurrent state, which fuses indirect packet-based inputs with optional direct camera-based inputs to estimate the object's position. Extensive experiments with realistic videos from the CARLA simulator and emulated networks under varying conditions show that GraySense achieves 2.33 meters tracking error (Euclidean distance) without raw signal access, within the dimensions of tracked objects (4.61m x 1.93m). To our knowledge, this capability has not been previously demonstrated, expanding the use of latent signals for sensing.
SPIRE: Conditional Personalization for Federated Diffusion Generative Models
Jun 14, 2025Recent advances in diffusion models have revolutionized generative AI, but their sheer size makes on device personalization, and thus effective federated learning (FL), infeasible. We propose Shared Backbone Personal Identity Representation Embeddings (SPIRE), a framework that casts per client diffusion based generation as conditional generation in FL. SPIRE factorizes the network into (i) a high capacity global backbone that learns a population level score function and (ii) lightweight, learnable client embeddings that encode local data statistics. This separation enables parameter efficient finetuning that touches $\leq 0.01\%$ of weights. We provide the first theoretical bridge between conditional diffusion training and maximum likelihood estimation in Gaussian mixture models. For a two component mixture we prove that gradient descent on the DDPM with respect to mixing weights loss recovers the optimal mixing weights and enjoys dimension free error bounds. Our analysis also hints at how client embeddings act as biases that steer a shared score network toward personalized distributions. Empirically, SPIRE matches or surpasses strong baselines during collaborative pretraining, and vastly outperforms them when adapting to unseen clients, reducing Kernel Inception Distance while updating only hundreds of parameters. SPIRE further mitigates catastrophic forgetting and remains robust across finetuning learning rate and epoch choices.
ICQuant: Index Coding enables Low-bit LLM Quantization
May 01, 2025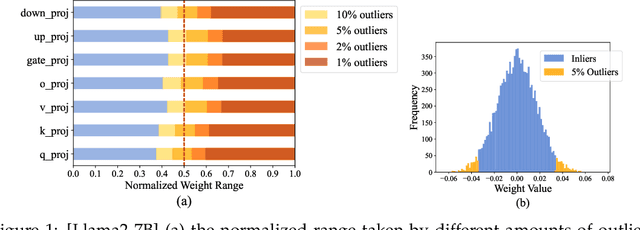

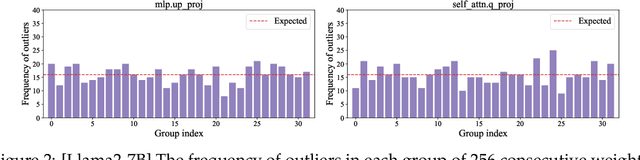
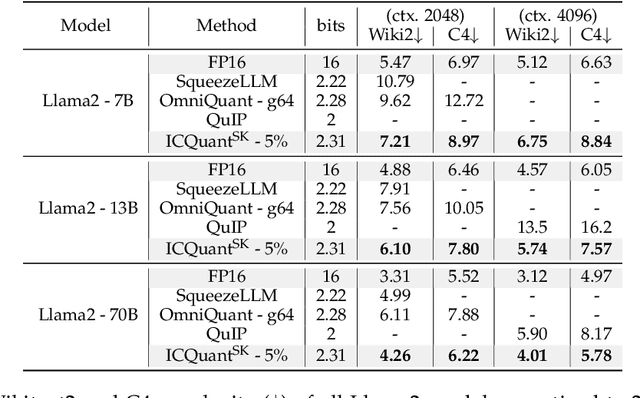
The rapid deployment of Large Language Models (LLMs) highlights the need for efficient low-bit post-training quantization (PTQ), due to their high memory costs. A key challenge in weight quantization is the presence of outliers, which inflate quantization ranges and lead to large errors. While a number of outlier suppression techniques have been proposed, they either: fail to effectively shrink the quantization range, or incur (relatively) high bit overhead. In this paper, we present ICQuant, a novel framework that leverages outlier statistics to design an efficient index coding scheme for outlier-aware weight-only quantization. Compared to existing outlier suppression techniques requiring $\approx 1$ bit overhead to halve the quantization range, ICQuant requires only $\approx 0.3$ bits; a significant saving in extreme compression regimes (e.g., 2-3 bits per weight). ICQuant can be used on top of any existing quantizers to eliminate outliers, improving the quantization quality. Using just 2.3 bits per weight and simple scalar quantizers, ICQuant improves the zero-shot accuracy of the 2-bit Llama3-70B model by up to 130% and 150% relative to QTIP and QuIP#; and it achieves comparable performance to the best-known fine-tuned quantizer (PV-tuning) without fine-tuning.
Robust Federated Personalised Mean Estimation for the Gaussian Mixture Model
Apr 28, 2025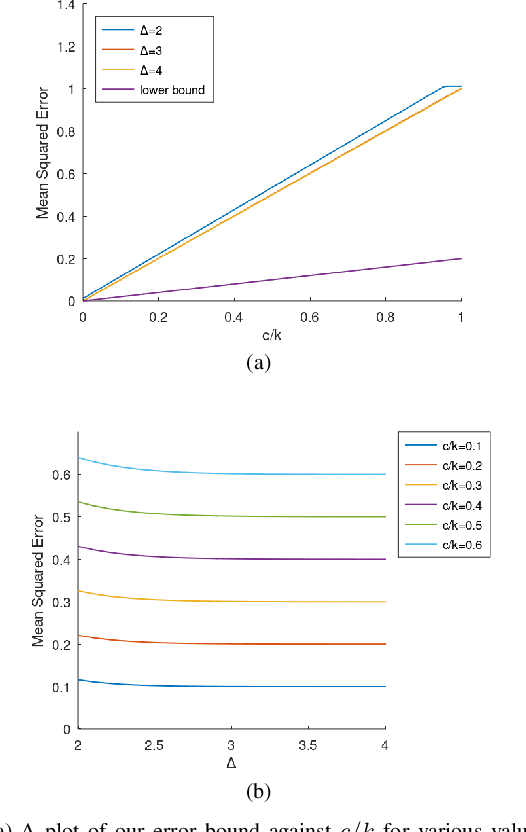
Federated learning with heterogeneous data and personalization has received significant recent attention. Separately, robustness to corrupted data in the context of federated learning has also been studied. In this paper we explore combining personalization for heterogeneous data with robustness, where a constant fraction of the clients are corrupted. Motivated by this broad problem, we formulate a simple instantiation which captures some of its difficulty. We focus on the specific problem of personalized mean estimation where the data is drawn from a Gaussian mixture model. We give an algorithm whose error depends almost linearly on the ratio of corrupted to uncorrupted samples, and show a lower bound with the same behavior, albeit with a gap of a constant factor.
InfoMAE: Pair-Efficient Cross-Modal Alignment for Multimodal Time-Series Sensing Signals
Apr 13, 2025Standard multimodal self-supervised learning (SSL) algorithms regard cross-modal synchronization as implicit supervisory labels during pretraining, thus posing high requirements on the scale and quality of multimodal samples. These constraints significantly limit the performance of sensing intelligence in IoT applications, as the heterogeneity and the non-interpretability of time-series signals result in abundant unimodal data but scarce high-quality multimodal pairs. This paper proposes InfoMAE, a cross-modal alignment framework that tackles the challenge of multimodal pair efficiency under the SSL setting by facilitating efficient cross-modal alignment of pretrained unimodal representations. InfoMAE achieves \textit{efficient cross-modal alignment} with \textit{limited data pairs} through a novel information theory-inspired formulation that simultaneously addresses distribution-level and instance-level alignment. Extensive experiments on two real-world IoT applications are performed to evaluate InfoMAE's pairing efficiency to bridge pretrained unimodal models into a cohesive joint multimodal model. InfoMAE enhances downstream multimodal tasks by over 60% with significantly improved multimodal pairing efficiency. It also improves unimodal task accuracy by an average of 22%.
Transformers learn variable-order Markov chains in-context
Oct 07, 2024Large language models have demonstrated impressive in-context learning (ICL) capability. However, it is still unclear how the underlying transformers accomplish it, especially in more complex scenarios. Toward this goal, several recent works studied how transformers learn fixed-order Markov chains (FOMC) in context, yet natural languages are more suitably modeled by variable-order Markov chains (VOMC), i.e., context trees (CTs). In this work, we study the ICL of VOMC by viewing language modeling as a form of data compression and focus on small alphabets and low-order VOMCs. This perspective allows us to leverage mature compression algorithms, such as context-tree weighting (CTW) and prediction by partial matching (PPM) algorithms as baselines, the former of which is Bayesian optimal for a class of CTW priors. We empirically observe a few phenomena: 1) Transformers can indeed learn to compress VOMC in-context, while PPM suffers significantly; 2) The performance of transformers is not very sensitive to the number of layers, and even a two-layer transformer can learn in-context quite well; and 3) Transformers trained and tested on non-CTW priors can significantly outperform the CTW algorithm. To explain these phenomena, we analyze the attention map of the transformers and extract two mechanisms, on which we provide two transformer constructions: 1) A construction with $D+2$ layers that can mimic the CTW algorithm accurately for CTs of maximum order $D$, 2) A 2-layer transformer that utilizes the feed-forward network for probability blending. One distinction from the FOMC setting is that a counting mechanism appears to play an important role. We implement these synthetic transformer layers and show that such hybrid transformers can match the ICL performance of transformers, and more interestingly, some of them can perform even better despite the much-reduced parameter sets.
Reframing Data Value for Large Language Models Through the Lens of Plausability
Aug 30, 2024



Data valuation seeks to answer the important question, "How much is this data worth?" Existing data valuation methods have largely focused on discriminative models, primarily examining data value through the lens of its utility in training. However, with the push for ever-larger language models, relying on valuation methods that require training becomes increasingly expensive and dependent on specific techniques. We propose an alternative perspective on the data value problem for language models, centering around the plausibility of the data. We posit that data holds lesser value if it can be plausibly generated by the model itself. Starting from some intuitive criteria that align with our notions of valuable data, we develop a novel value function that is computationally tractable and derived from first principles with provable properties. We conduct a theoretical analysis of our value function and evaluate it across multiple scenarios and datasets.
On the Efficiency and Robustness of Vibration-based Foundation Models for IoT Sensing: A Case Study
Apr 03, 2024



This paper demonstrates the potential of vibration-based Foundation Models (FMs), pre-trained with unlabeled sensing data, to improve the robustness of run-time inference in (a class of) IoT applications. A case study is presented featuring a vehicle classification application using acoustic and seismic sensing. The work is motivated by the success of foundation models in the areas of natural language processing and computer vision, leading to generalizations of the FM concept to other domains as well, where significant amounts of unlabeled data exist that can be used for self-supervised pre-training. One such domain is IoT applications. Foundation models for selected sensing modalities in the IoT domain can be pre-trained in an environment-agnostic fashion using available unlabeled sensor data and then fine-tuned to the deployment at hand using a small amount of labeled data. The paper shows that the pre-training/fine-tuning approach improves the robustness of downstream inference and facilitates adaptation to different environmental conditions. More specifically, we present a case study in a real-world setting to evaluate a simple (vibration-based) FM-like model, called FOCAL, demonstrating its superior robustness and adaptation, compared to conventional supervised deep neural networks (DNNs). We also demonstrate its superior convergence over supervised solutions. Our findings highlight the advantages of vibration-based FMs (and FM-inspired selfsupervised models in general) in terms of inference robustness, runtime efficiency, and model adaptation (via fine-tuning) in resource-limited IoT settings.
Hierarchical Bayes Approach to Personalized Federated Unsupervised Learning
Feb 25, 2024Statistical heterogeneity of clients' local data is an important characteristic in federated learning, motivating personalized algorithms tailored to the local data statistics. Though there has been a plethora of algorithms proposed for personalized supervised learning, discovering the structure of local data through personalized unsupervised learning is less explored. We initiate a systematic study of such personalized unsupervised learning by developing algorithms based on optimization criteria inspired by a hierarchical Bayesian statistical framework. We develop adaptive algorithms that discover the balance between using limited local data and collaborative information. We do this in the context of two unsupervised learning tasks: personalized dimensionality reduction and personalized diffusion models. We develop convergence analyses for our adaptive algorithms which illustrate the dependence on problem parameters (e.g., heterogeneity, local sample size). We also develop a theoretical framework for personalized diffusion models, which shows the benefits of collaboration even under heterogeneity. We finally evaluate our proposed algorithms using synthetic and real data, demonstrating the effective sample amplification for personalized tasks, induced through collaboration, despite data heterogeneity.