 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAC^2-VLA: Action-Context-Aware Adaptive Computation in Vision-Language-Action Models for Efficient Robotic Manipulation
Jan 27, 2026Vision-Language-Action (VLA) models have demonstrated strong performance in robotic manipulation, yet their closed-loop deployment is hindered by the high latency and compute cost of repeatedly running large vision-language backbones at every timestep. We observe that VLA inference exhibits structured redundancies across temporal, spatial, and depth dimensions, and that most existing efficiency methods ignore action context, despite its central role in embodied tasks. To address this gap, we propose Action-Context-aware Adaptive Computation for VLA models (AC^2-VLA), a unified framework that conditions computation on current visual observations, language instructions, and previous action states. Based on this action-centric context, AC^2-VLA adaptively performs cognition reuse across timesteps, token pruning, and selective execution of model components within a unified mechanism. To train the adaptive policy, we introduce an action-guided self-distillation scheme that preserves the behavior of the dense VLA policy while enabling structured sparsification that transfers across tasks and settings. Extensive experiments on robotic manipulation benchmarks show that AC^2-VLA achieves up to a 1.79\times speedup while reducing FLOPs to 29.4% of the dense baseline, with comparable task success.
SCRAG: Social Computing-Based Retrieval Augmented Generation for Community Response Forecasting in Social Media Environments
Apr 18, 2025This paper introduces SCRAG, a prediction framework inspired by social computing, designed to forecast community responses to real or hypothetical social media posts. SCRAG can be used by public relations specialists (e.g., to craft messaging in ways that avoid unintended misinterpretations) or public figures and influencers (e.g., to anticipate social responses), among other applications related to public sentiment prediction, crisis management, and social what-if analysis. While large language models (LLMs) have achieved remarkable success in generating coherent and contextually rich text, their reliance on static training data and susceptibility to hallucinations limit their effectiveness at response forecasting in dynamic social media environments. SCRAG overcomes these challenges by integrating LLMs with a Retrieval-Augmented Generation (RAG) technique rooted in social computing. Specifically, our framework retrieves (i) historical responses from the target community to capture their ideological, semantic, and emotional makeup, and (ii) external knowledge from sources such as news articles to inject time-sensitive context. This information is then jointly used to forecast the responses of the target community to new posts or narratives. Extensive experiments across six scenarios on the X platform (formerly Twitter), tested with various embedding models and LLMs, demonstrate over 10% improvements on average in key evaluation metrics. A concrete example further shows its effectiveness in capturing diverse ideologies and nuances. Our work provides a social computing tool for applications where accurate and concrete insights into community responses are crucial.
InfoMAE: Pair-Efficient Cross-Modal Alignment for Multimodal Time-Series Sensing Signals
Apr 13, 2025Standard multimodal self-supervised learning (SSL) algorithms regard cross-modal synchronization as implicit supervisory labels during pretraining, thus posing high requirements on the scale and quality of multimodal samples. These constraints significantly limit the performance of sensing intelligence in IoT applications, as the heterogeneity and the non-interpretability of time-series signals result in abundant unimodal data but scarce high-quality multimodal pairs. This paper proposes InfoMAE, a cross-modal alignment framework that tackles the challenge of multimodal pair efficiency under the SSL setting by facilitating efficient cross-modal alignment of pretrained unimodal representations. InfoMAE achieves \textit{efficient cross-modal alignment} with \textit{limited data pairs} through a novel information theory-inspired formulation that simultaneously addresses distribution-level and instance-level alignment. Extensive experiments on two real-world IoT applications are performed to evaluate InfoMAE's pairing efficiency to bridge pretrained unimodal models into a cohesive joint multimodal model. InfoMAE enhances downstream multimodal tasks by over 60% with significantly improved multimodal pairing efficiency. It also improves unimodal task accuracy by an average of 22%.
On the Efficiency and Robustness of Vibration-based Foundation Models for IoT Sensing: A Case Study
Apr 03, 2024



This paper demonstrates the potential of vibration-based Foundation Models (FMs), pre-trained with unlabeled sensing data, to improve the robustness of run-time inference in (a class of) IoT applications. A case study is presented featuring a vehicle classification application using acoustic and seismic sensing. The work is motivated by the success of foundation models in the areas of natural language processing and computer vision, leading to generalizations of the FM concept to other domains as well, where significant amounts of unlabeled data exist that can be used for self-supervised pre-training. One such domain is IoT applications. Foundation models for selected sensing modalities in the IoT domain can be pre-trained in an environment-agnostic fashion using available unlabeled sensor data and then fine-tuned to the deployment at hand using a small amount of labeled data. The paper shows that the pre-training/fine-tuning approach improves the robustness of downstream inference and facilitates adaptation to different environmental conditions. More specifically, we present a case study in a real-world setting to evaluate a simple (vibration-based) FM-like model, called FOCAL, demonstrating its superior robustness and adaptation, compared to conventional supervised deep neural networks (DNNs). We also demonstrate its superior convergence over supervised solutions. Our findings highlight the advantages of vibration-based FMs (and FM-inspired selfsupervised models in general) in terms of inference robustness, runtime efficiency, and model adaptation (via fine-tuning) in resource-limited IoT settings.
SudokuSens: Enhancing Deep Learning Robustness for IoT Sensing Applications using a Generative Approach
Feb 08, 2024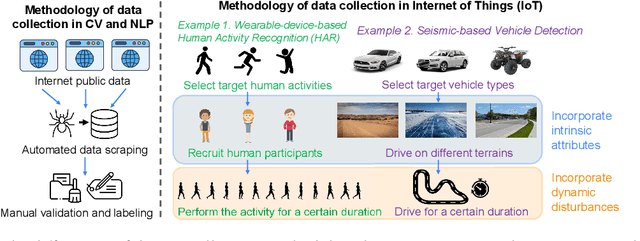
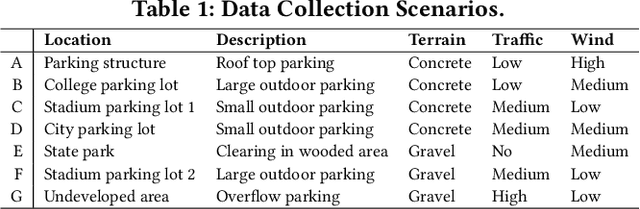
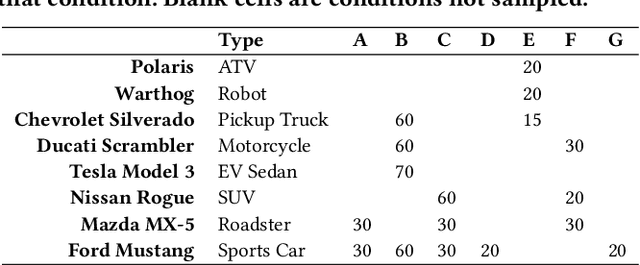
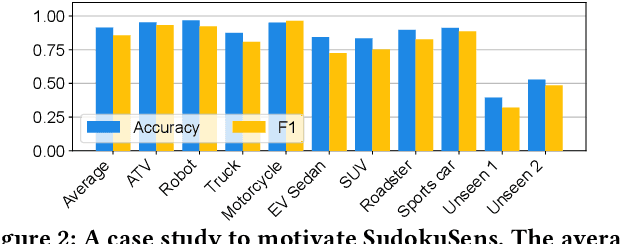
This paper introduces SudokuSens, a generative framework for automated generation of training data in machine-learning-based Internet-of-Things (IoT) applications, such that the generated synthetic data mimic experimental configurations not encountered during actual sensor data collection. The framework improves the robustness of resulting deep learning models, and is intended for IoT applications where data collection is expensive. The work is motivated by the fact that IoT time-series data entangle the signatures of observed objects with the confounding intrinsic properties of the surrounding environment and the dynamic environmental disturbances experienced. To incorporate sufficient diversity into the IoT training data, one therefore needs to consider a combinatorial explosion of training cases that are multiplicative in the number of objects considered and the possible environmental conditions in which such objects may be encountered. Our framework substantially reduces these multiplicative training needs. To decouple object signatures from environmental conditions, we employ a Conditional Variational Autoencoder (CVAE) that allows us to reduce data collection needs from multiplicative to (nearly) linear, while synthetically generating (data for) the missing conditions. To obtain robustness with respect to dynamic disturbances, a session-aware temporal contrastive learning approach is taken. Integrating the aforementioned two approaches, SudokuSens significantly improves the robustness of deep learning for IoT applications. We explore the degree to which SudokuSens benefits downstream inference tasks in different data sets and discuss conditions under which the approach is particularly effective.
Cross-Modal Retrieval: A Systematic Review of Methods and Future Directions
Aug 28, 2023



With the exponential surge in diverse multi-modal data, traditional uni-modal retrieval methods struggle to meet the needs of users demanding access to data from various modalities. To address this, cross-modal retrieval has emerged, enabling interaction across modalities, facilitating semantic matching, and leveraging complementarity and consistency between different modal data. Although prior literature undertook a review of the cross-modal retrieval field, it exhibits numerous deficiencies pertaining to timeliness, taxonomy, and comprehensiveness. This paper conducts a comprehensive review of cross-modal retrieval's evolution, spanning from shallow statistical analysis techniques to vision-language pre-training models. Commencing with a comprehensive taxonomy grounded in machine learning paradigms, mechanisms, and models, the paper then delves deeply into the principles and architectures underpinning existing cross-modal retrieval methods. Furthermore, it offers an overview of widely used benchmarks, metrics, and performances. Lastly, the paper probes the prospects and challenges that confront contemporary cross-modal retrieval, while engaging in a discourse on potential directions for further progress in the field. To facilitate the research on cross-modal retrieval, we develop an open-source code repository at https://github.com/BMC-SDNU/Cross-Modal-Retrieval.
Self-Contrastive Learning based Semi-Supervised Radio Modulation Classification
Mar 29, 2022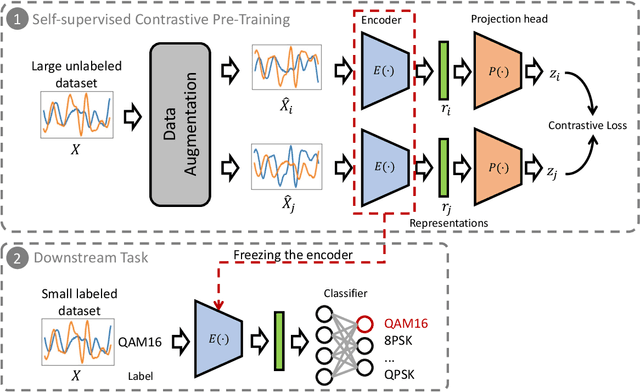
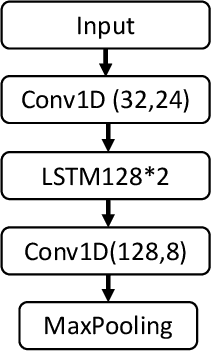
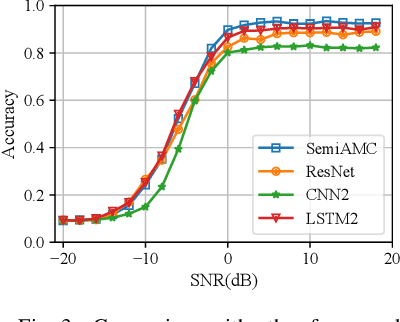
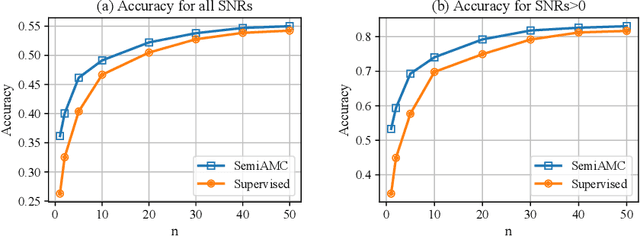
This paper presents a semi-supervised learning framework that is new in being designed for automatic modulation classification (AMC). By carefully utilizing unlabeled signal data with a self-supervised contrastive-learning pre-training step, our framework achieves higher performance given smaller amounts of labeled data, thereby largely reducing the labeling burden of deep learning. We evaluate the performance of our semi-supervised framework on a public dataset. The evaluation results demonstrate that our semi-supervised approach significantly outperforms supervised frameworks thereby substantially enhancing our ability to train deep neural networks for automatic modulation classification in a manner that leverages unlabeled data.
Scheduling Real-time Deep Learning Services as Imprecise Computations
Nov 02, 2020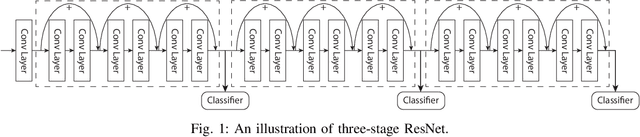
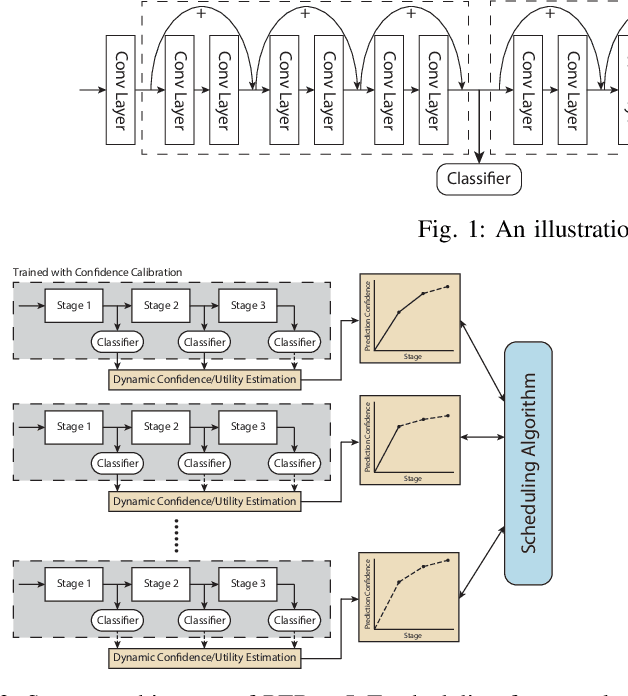
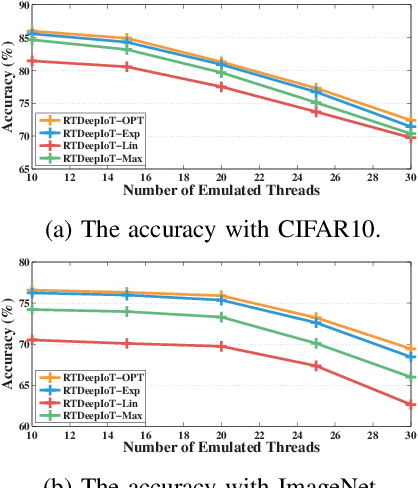
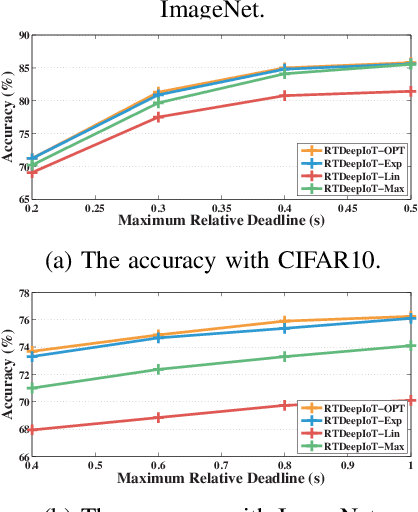
The paper presents an efficient real-time scheduling algorithm for intelligent real-time edge services, defined as those that perform machine intelligence tasks, such as voice recognition, LIDAR processing, or machine vision, on behalf of local embedded devices that are themselves unable to support extensive computations. The work contributes to a recent direction in real-time computing that develops scheduling algorithms for machine intelligence tasks with anytime prediction. We show that deep neural network workflows can be cast as imprecise computations, each with a mandatory part and (several) optional parts whose execution utility depends on input data. The goal of the real-time scheduler is to maximize the average accuracy of deep neural network outputs while meeting task deadlines, thanks to opportunistic shedding of the least necessary optional parts. The work is motivated by the proliferation of increasingly ubiquitous but resource-constrained embedded devices (for applications ranging from autonomous cars to the Internet of Things) and the desire to develop services that endow them with intelligence. Experiments on recent GPU hardware and a state of the art deep neural network for machine vision illustrate that our scheme can increase the overall accuracy by 10%-20% while incurring (nearly) no deadline misses.
Disentangling Overlapping Beliefs by Structured Matrix Factorization
Feb 13, 2020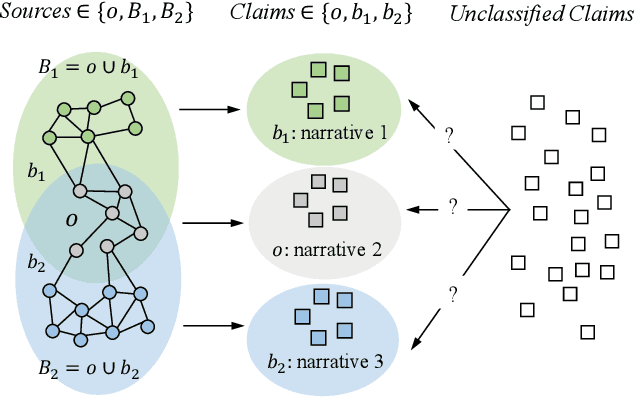


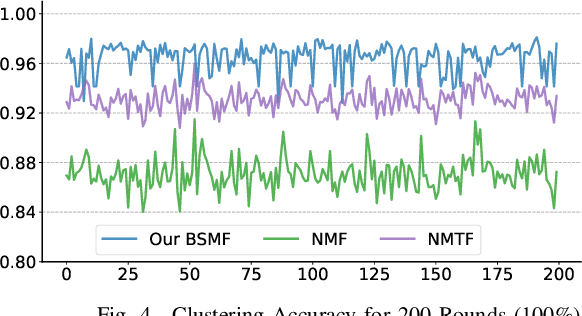
Much work on social media opinion polarization focuses on identifying separate or orthogonal beliefs from media traces, thereby missing points of agreement among different communities. This paper develops a new class of Non-negative Matrix Factorization (NMF) algorithms that allow identification of both agreement and disagreement points when beliefs of different communities partially overlap. Specifically, we propose a novel Belief Structured Matrix Factorization algorithm (BSMF) to identify partially overlapping beliefs in polarized public social media. BSMF is totally unsupervised and considers three types of information: (i) who posted which opinion, (ii) keyword-level message similarity, and (iii) empirically observed social dependency graphs (e.g., retweet graphs), to improve belief separation. In the space of unsupervised belief separation algorithms, the emphasis was mostly given to the problem of identifying disjoint (e.g., conflicting) beliefs. The case when individuals with different beliefs agree on some subset of points was less explored. We observe that social beliefs overlap even in polarized scenarios. Our proposed unsupervised algorithm captures both the latent belief intersections and dissimilarities. We discuss the properties of the algorithm and conduct extensive experiments on both synthetic data and real-world datasets. The results show that our model outperforms all compared baselines by a great margin.
STFNets: Learning Sensing Signals from the Time-Frequency Perspective with Short-Time Fourier Neural Networks
Feb 21, 2019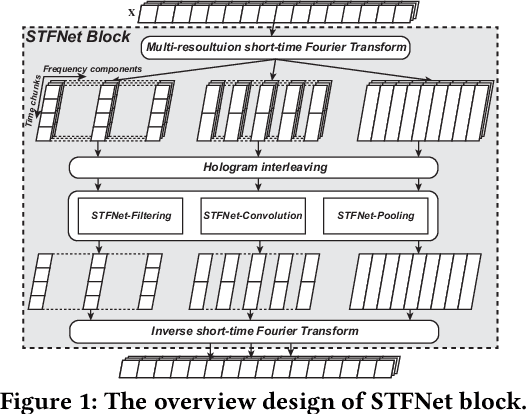
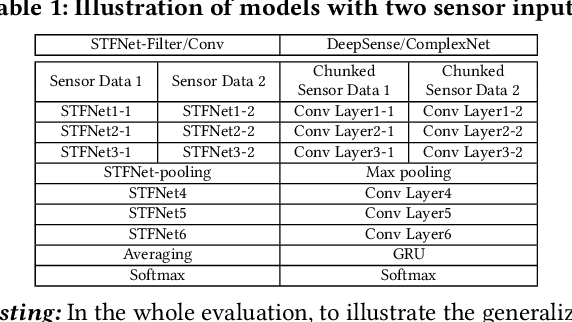
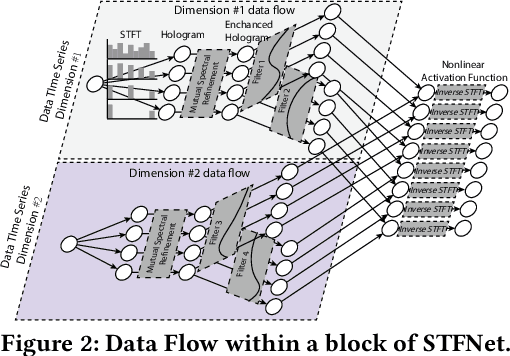
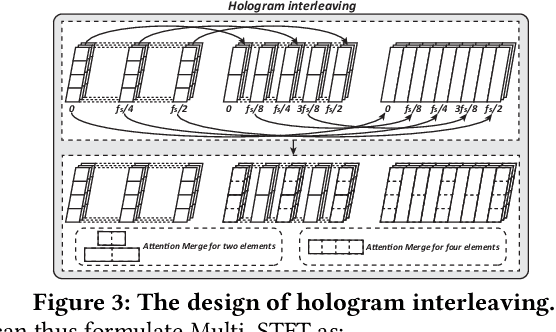
Recent advances in deep learning motivate the use of deep neural networks in Internet-of-Things (IoT) applications. These networks are modelled after signal processing in the human brain, thereby leading to significant advantages at perceptual tasks such as vision and speech recognition. IoT applications, however, often measure physical phenomena, where the underlying physics (such as inertia, wireless signal propagation, or the natural frequency of oscillation) are fundamentally a function of signal frequencies, offering better features in the frequency domain. This observation leads to a fundamental question: For IoT applications, can one develop a new brand of neural network structures that synthesize features inspired not only by the biology of human perception but also by the fundamental nature of physics? Hence, in this paper, instead of using conventional building blocks (e.g., convolutional and recurrent layers), we propose a new foundational neural network building block, the Short-Time Fourier Neural Network (STFNet). It integrates a widely-used time-frequency analysis method, the Short-Time Fourier Transform, into data processing to learn features directly in the frequency domain, where the physics of underlying phenomena leave better foot-prints. STFNets bring additional flexibility to time-frequency analysis by offering novel nonlinear learnable operations that are spectral-compatible. Moreover, STFNets show that transforming signals to a domain that is more connected to the underlying physics greatly simplifies the learning process. We demonstrate the effectiveness of STFNets with extensive experiments. STFNets significantly outperform the state-of-the-art deep learning models in all experiments. A STFNet, therefore, demonstrates superior capability as the fundamental building block of deep neural networks for IoT applications for various sensor inputs.