 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeaderboard Incentives: Model Rankings under Strategic Post-Training
Mar 09, 2026Influential benchmarks incentivize competing model developers to strategically allocate post-training resources toward improvements on the leaderboard, a phenomenon dubbed benchmaxxing or training on the test task. In this work, we initiate a principled study of the incentive structure that benchmarks induce. We model benchmarking as a Stackelberg game between a benchmark designer who chooses an evaluation protocol and multiple model developers who compete simultaneously in a subgame given by the designer's choice. Each competitor has a model of unknown latent quality and can inflate its observed score by allocating resources to benchmark-specific improvements. First, we prove that current benchmarks induce games for which no Nash equilibrium between model developers exists. This result suggests one explanation for why current practice leads to misaligned incentives, prompting model developers to strategize in opaque ways. However, we prove that under mild conditions, a recently proposed evaluation protocol, called tune-before-test, induces a benchmark with a unique Nash equilibrium that ranks models by latent quality. This positive result demonstrates that benchmarks need not set bad incentives, even if current evaluations do.
ROC-n-reroll: How verifier imperfection affects test-time scaling
Jul 16, 2025Test-time scaling aims to improve language model performance by leveraging additional compute during inference. While many works have empirically studied techniques like Best-of-N (BoN) and rejection sampling that make use of a verifier to enable test-time scaling, there is little theoretical understanding of how verifier imperfection affects performance. In this work, we address this gap. Specifically, we prove how instance-level accuracy of these methods is precisely characterized by the geometry of the verifier's ROC curve. Interestingly, while scaling is determined by the local geometry of the ROC curve for rejection sampling, it depends on global properties of the ROC curve for BoN. As a consequence when the ROC curve is unknown, it is impossible to extrapolate the performance of rejection sampling based on the low-compute regime. Furthermore, while rejection sampling outperforms BoN for fixed compute, in the infinite-compute limit both methods converge to the same level of accuracy, determined by the slope of the ROC curve near the origin. Our theoretical results are confirmed by experiments on GSM8K using different versions of Llama and Qwen to generate and verify solutions.
InfoMAE: Pair-Efficient Cross-Modal Alignment for Multimodal Time-Series Sensing Signals
Apr 13, 2025Standard multimodal self-supervised learning (SSL) algorithms regard cross-modal synchronization as implicit supervisory labels during pretraining, thus posing high requirements on the scale and quality of multimodal samples. These constraints significantly limit the performance of sensing intelligence in IoT applications, as the heterogeneity and the non-interpretability of time-series signals result in abundant unimodal data but scarce high-quality multimodal pairs. This paper proposes InfoMAE, a cross-modal alignment framework that tackles the challenge of multimodal pair efficiency under the SSL setting by facilitating efficient cross-modal alignment of pretrained unimodal representations. InfoMAE achieves \textit{efficient cross-modal alignment} with \textit{limited data pairs} through a novel information theory-inspired formulation that simultaneously addresses distribution-level and instance-level alignment. Extensive experiments on two real-world IoT applications are performed to evaluate InfoMAE's pairing efficiency to bridge pretrained unimodal models into a cohesive joint multimodal model. InfoMAE enhances downstream multimodal tasks by over 60% with significantly improved multimodal pairing efficiency. It also improves unimodal task accuracy by an average of 22%.
To Give or Not to Give? The Impacts of Strategically Withheld Recourse
Apr 08, 2025Individuals often aim to reverse undesired outcomes in interactions with automated systems, like loan denials, by either implementing system-recommended actions (recourse), or manipulating their features. While providing recourse benefits users and enhances system utility, it also provides information about the decision process that can be used for more effective strategic manipulation, especially when the individuals collectively share such information with each other. We show that this tension leads rational utility-maximizing systems to frequently withhold recourse, resulting in decreased population utility, particularly impacting sensitive groups. To mitigate these effects, we explore the role of recourse subsidies, finding them effective in increasing the provision of recourse actions by rational systems, as well as lowering the potential social cost and mitigating unfairness caused by recourse withholding.
Performative Prediction with Bandit Feedback: Learning through Reparameterization
May 08, 2023

Performative prediction, as introduced by Perdomo et al. (2020), is a framework for studying social prediction in which the data distribution itself changes in response to the deployment of a model. Existing work on optimizing accuracy in this setting hinges on two assumptions that are easily violated in practice: that the performative risk is convex over the deployed model, and that the mapping from the model to the data distribution is known to the model designer in advance. In this paper, we initiate the study of tractable performative prediction problems that do not require these assumptions. To tackle this more challenging setting, we develop a two-level zeroth-order optimization algorithm, where one level aims to compute the distribution map, and the other level reparameterizes the performative prediction objective as a function of the induced data distribution. Under mild conditions, this reparameterization allows us to transform the non-convex objective into a convex one and achieve provable regret guarantees. In particular, we provide a regret bound that is sublinear in the total number of performative samples taken and only polynomial in the dimension of the model parameter.
Tier Balancing: Towards Dynamic Fairness over Underlying Causal Factors
Jan 21, 2023



The pursuit of long-term fairness involves the interplay between decision-making and the underlying data generating process. In this paper, through causal modeling with a directed acyclic graph (DAG) on the decision-distribution interplay, we investigate the possibility of achieving long-term fairness from a dynamic perspective. We propose Tier Balancing, a technically more challenging but more natural notion to achieve in the context of long-term, dynamic fairness analysis. Different from previous fairness notions that are defined purely on observed variables, our notion goes one step further, capturing behind-the-scenes situation changes on the unobserved latent causal factors that directly carry out the influence from the current decision to the future data distribution. Under the specified dynamics, we prove that in general one cannot achieve the long-term fairness goal only through one-step interventions. Furthermore, in the effort of approaching long-term fairness, we consider the mission of "getting closer to" the long-term fairness goal and present possibility and impossibility results accordingly.
Metric-Fair Classifier Derandomization
Jun 17, 2022We study the problem of classifier derandomization in machine learning: given a stochastic binary classifier $f: X \to [0,1]$, sample a deterministic classifier $\hat{f}: X \to \{0,1\}$ that approximates the output of $f$ in aggregate over any data distribution. Recent work revealed how to efficiently derandomize a stochastic classifier with strong output approximation guarantees, but at the cost of individual fairness -- that is, if $f$ treated similar inputs similarly, $\hat{f}$ did not. In this paper, we initiate a systematic study of classifier derandomization with metric fairness guarantees. We show that the prior derandomization approach is almost maximally metric-unfair, and that a simple ``random threshold'' derandomization achieves optimal fairness preservation but with weaker output approximation. We then devise a derandomization procedure that provides an appealing tradeoff between these two: if $f$ is $\alpha$-metric fair according to a metric $d$ with a locality-sensitive hash (LSH) family, then our derandomized $\hat{f}$ is, with high probability, $O(\alpha)$-metric fair and a close approximation of $f$. We also prove generic results applicable to all (fair and unfair) classifier derandomization procedures, including a bias-variance decomposition and reductions between various notions of metric fairness.
Fairness Transferability Subject to Bounded Distribution Shift
May 31, 2022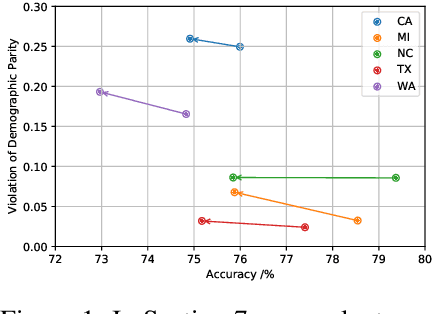

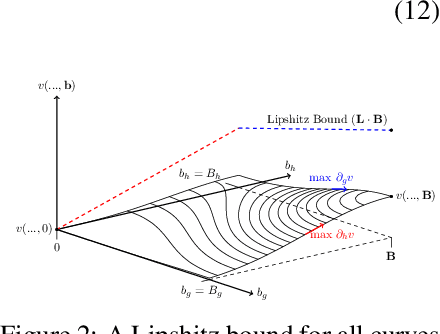
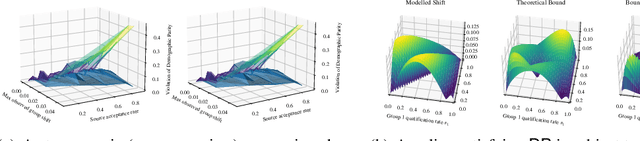
Given an algorithmic predictor that is "fair" on some source distribution, will it still be fair on an unknown target distribution that differs from the source within some bound? In this paper, we study the transferability of statistical group fairness for machine learning predictors (i.e., classifiers or regressors) subject to bounded distribution shift, a phenomenon frequently caused by user adaptation to a deployed model or a dynamic environment. Herein, we develop a bound characterizing such transferability, flagging potentially inappropriate deployments of machine learning for socially consequential tasks. We first develop a framework for bounding violations of statistical fairness subject to distribution shift, formulating a generic upper bound for transferred fairness violation as our primary result. We then develop bounds for specific worked examples, adopting two commonly used fairness definitions (i.e., demographic parity and equalized odds) for two classes of distribution shift (i.e., covariate shift and label shift). Finally, we compare our theoretical bounds to deterministic models of distribution shift as well as real-world data.
Induced Domain Adaptation
Jul 13, 2021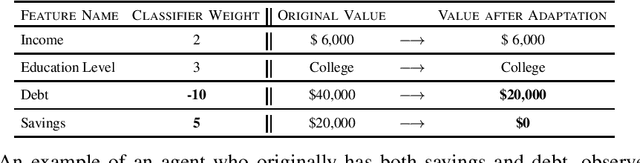
We formulate the problem of induced domain adaptation (IDA) when the underlying distribution/domain shift is introduced by the model being deployed. Our formulation is motivated by applications where the deployed machine learning models interact with human agents, and will ultimately face responsive and interactive data distributions. We formalize the discussions of the transferability of learning in our IDA setting by studying how the model trained on the available source distribution (data) would translate to the performance on the induced domain. We provide both upper bounds for the performance gap due to the induced domain shift, as well as lower bound for the trade-offs a classifier has to suffer on either the source training distribution or the induced target distribution. We provide further instantiated analysis for two popular domain adaptation settings with covariate shift and label shift. We highlight some key properties of IDA, as well as computational and learning challenges.
Strategic Recourse in Linear Classification
Oct 31, 2020
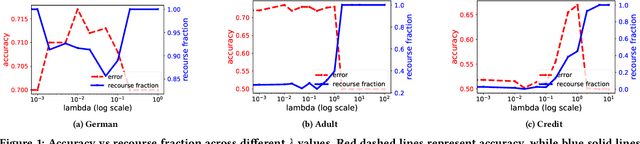
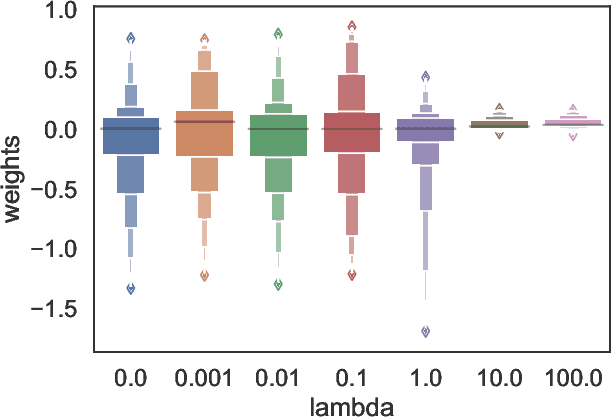
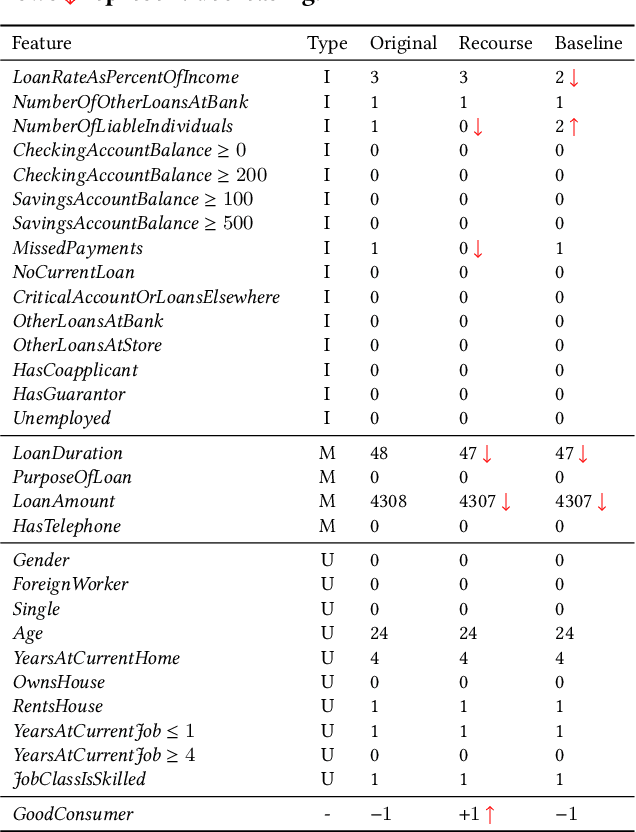
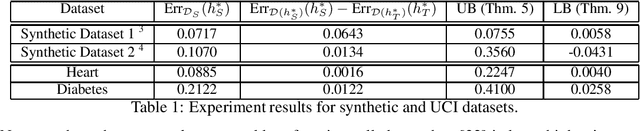
In algorithmic decision making, recourse refers to individuals' ability to systematically reverse an unfavorable decision made by an algorithm. Meanwhile, individuals subjected to a classification mechanism are incentivized to behave strategically in order to gain a system's approval. However, not all strategic behavior necessarily leads to adverse results: through appropriate mechanism design, strategic behavior can induce genuine improvement in an individual's qualifications. In this paper, we explore how to design a classifier that achieves high accuracy while providing recourse to strategic individuals so as to incentivize them to improve their features in non-manipulative ways. We capture these dynamics using a two-stage game: first, the mechanism designer publishes a classifier, with the goal of optimizing classification accuracy and providing recourse to incentivize individuals' improvement. Then, agents respond by potentially modifying their input features in order to obtain a favorable decision from the classifier, while trying to minimize the cost of making such modifications. Under this model, we provide analytical results characterizing the equilibrium strategies for both the mechanism designer and the agents. Our empirical results show the effectiveness of our mechanism in three real-world datasets: compared to a baseline classifier that only considers individuals' strategic behavior without explicitly incentivizing improvement, our algorithm can provide recourse to a much higher fraction of individuals in the direction of improvement while maintaining relatively high prediction accuracy. We also show that our algorithm can effectively mitigate disparities caused by differences in manipulation costs. Our results provide insights for designing a machine learning model that focuses not only on the static distribution as of now, but also tries to encourage future improvement.