 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeICQuant: Index Coding enables Low-bit LLM Quantization
May 01, 2025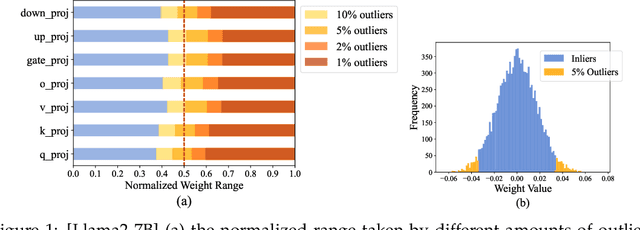

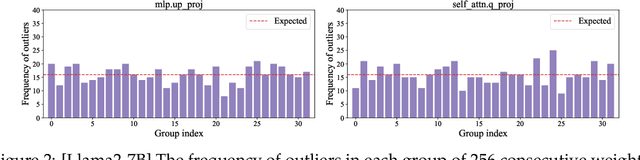
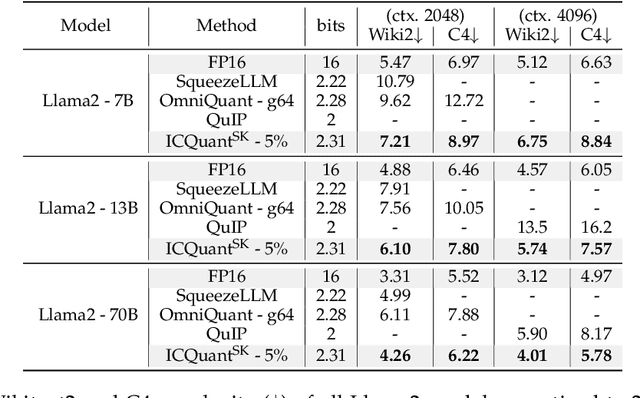
The rapid deployment of Large Language Models (LLMs) highlights the need for efficient low-bit post-training quantization (PTQ), due to their high memory costs. A key challenge in weight quantization is the presence of outliers, which inflate quantization ranges and lead to large errors. While a number of outlier suppression techniques have been proposed, they either: fail to effectively shrink the quantization range, or incur (relatively) high bit overhead. In this paper, we present ICQuant, a novel framework that leverages outlier statistics to design an efficient index coding scheme for outlier-aware weight-only quantization. Compared to existing outlier suppression techniques requiring $\approx 1$ bit overhead to halve the quantization range, ICQuant requires only $\approx 0.3$ bits; a significant saving in extreme compression regimes (e.g., 2-3 bits per weight). ICQuant can be used on top of any existing quantizers to eliminate outliers, improving the quantization quality. Using just 2.3 bits per weight and simple scalar quantizers, ICQuant improves the zero-shot accuracy of the 2-bit Llama3-70B model by up to 130% and 150% relative to QTIP and QuIP#; and it achieves comparable performance to the best-known fine-tuned quantizer (PV-tuning) without fine-tuning.
InfoMAE: Pair-Efficient Cross-Modal Alignment for Multimodal Time-Series Sensing Signals
Apr 13, 2025Standard multimodal self-supervised learning (SSL) algorithms regard cross-modal synchronization as implicit supervisory labels during pretraining, thus posing high requirements on the scale and quality of multimodal samples. These constraints significantly limit the performance of sensing intelligence in IoT applications, as the heterogeneity and the non-interpretability of time-series signals result in abundant unimodal data but scarce high-quality multimodal pairs. This paper proposes InfoMAE, a cross-modal alignment framework that tackles the challenge of multimodal pair efficiency under the SSL setting by facilitating efficient cross-modal alignment of pretrained unimodal representations. InfoMAE achieves \textit{efficient cross-modal alignment} with \textit{limited data pairs} through a novel information theory-inspired formulation that simultaneously addresses distribution-level and instance-level alignment. Extensive experiments on two real-world IoT applications are performed to evaluate InfoMAE's pairing efficiency to bridge pretrained unimodal models into a cohesive joint multimodal model. InfoMAE enhances downstream multimodal tasks by over 60% with significantly improved multimodal pairing efficiency. It also improves unimodal task accuracy by an average of 22%.
Understanding Neural Network Binarization with Forward and Backward Proximal Quantizers
Feb 27, 2024In neural network binarization, BinaryConnect (BC) and its variants are considered the standard. These methods apply the sign function in their forward pass and their respective gradients are backpropagated to update the weights. However, the derivative of the sign function is zero whenever defined, which consequently freezes training. Therefore, implementations of BC (e.g., BNN) usually replace the derivative of sign in the backward computation with identity or other approximate gradient alternatives. Although such practice works well empirically, it is largely a heuristic or ''training trick.'' We aim at shedding some light on these training tricks from the optimization perspective. Building from existing theory on ProxConnect (PC, a generalization of BC), we (1) equip PC with different forward-backward quantizers and obtain ProxConnect++ (PC++) that includes existing binarization techniques as special cases; (2) derive a principled way to synthesize forward-backward quantizers with automatic theoretical guarantees; (3) illustrate our theory by proposing an enhanced binarization algorithm BNN++; (4) conduct image classification experiments on CNNs and vision transformers, and empirically verify that BNN++ generally achieves competitive results on binarizing these models.
BinaryViT: Pushing Binary Vision Transformers Towards Convolutional Models
Jun 29, 2023With the increasing popularity and the increasing size of vision transformers (ViTs), there has been an increasing interest in making them more efficient and less computationally costly for deployment on edge devices with limited computing resources. Binarization can be used to help reduce the size of ViT models and their computational cost significantly, using popcount operations when the weights and the activations are in binary. However, ViTs suffer a larger performance drop when directly applying convolutional neural network (CNN) binarization methods or existing binarization methods to binarize ViTs compared to CNNs on datasets with a large number of classes such as ImageNet-1k. With extensive analysis, we find that binary vanilla ViTs such as DeiT miss out on a lot of key architectural properties that CNNs have that allow binary CNNs to have much higher representational capability than binary vanilla ViT. Therefore, we propose BinaryViT, in which inspired by the CNN architecture, we include operations from the CNN architecture into a pure ViT architecture to enrich the representational capability of a binary ViT without introducing convolutions. These include an average pooling layer instead of a token pooling layer, a block that contains multiple average pooling branches, an affine transformation right before the addition of each main residual connection, and a pyramid structure. Experimental results on the ImageNet-1k dataset show the effectiveness of these operations that allow a binary pure ViT model to be competitive with previous state-of-the-art (SOTA) binary CNN models.
* Accepted in CVPR 2023 Workshop on Efficient Deep Learning for Computer Vision (ECV)
Mathematical Challenges in Deep Learning
Mar 24, 2023



Deep models are dominating the artificial intelligence (AI) industry since the ImageNet challenge in 2012. The size of deep models is increasing ever since, which brings new challenges to this field with applications in cell phones, personal computers, autonomous cars, and wireless base stations. Here we list a set of problems, ranging from training, inference, generalization bound, and optimization with some formalism to communicate these challenges with mathematicians, statisticians, and theoretical computer scientists. This is a subjective view of the research questions in deep learning that benefits the tech industry in long run.
EuclidNets: An Alternative Operation for Efficient Inference of Deep Learning Models
Dec 22, 2022With the advent of deep learning application on edge devices, researchers actively try to optimize their deployments on low-power and restricted memory devices. There are established compression method such as quantization, pruning, and architecture search that leverage commodity hardware. Apart from conventional compression algorithms, one may redesign the operations of deep learning models that lead to more efficient implementation. To this end, we propose EuclidNet, a compression method, designed to be implemented on hardware which replaces multiplication, $xw$, with Euclidean distance $(x-w)^2$. We show that EuclidNet is aligned with matrix multiplication and it can be used as a measure of similarity in case of convolutional layers. Furthermore, we show that under various transformations and noise scenarios, EuclidNet exhibits the same performance compared to the deep learning models designed with multiplication operations.
DenseShift: Towards Accurate and Transferable Low-Bit Shift Network
Aug 20, 2022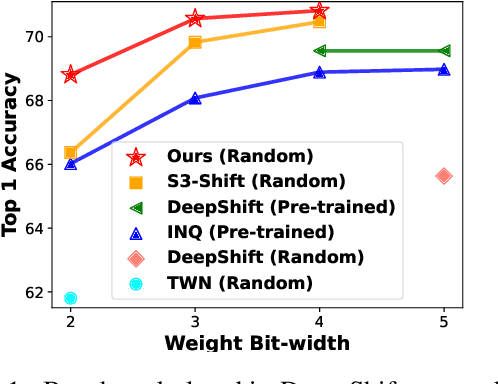
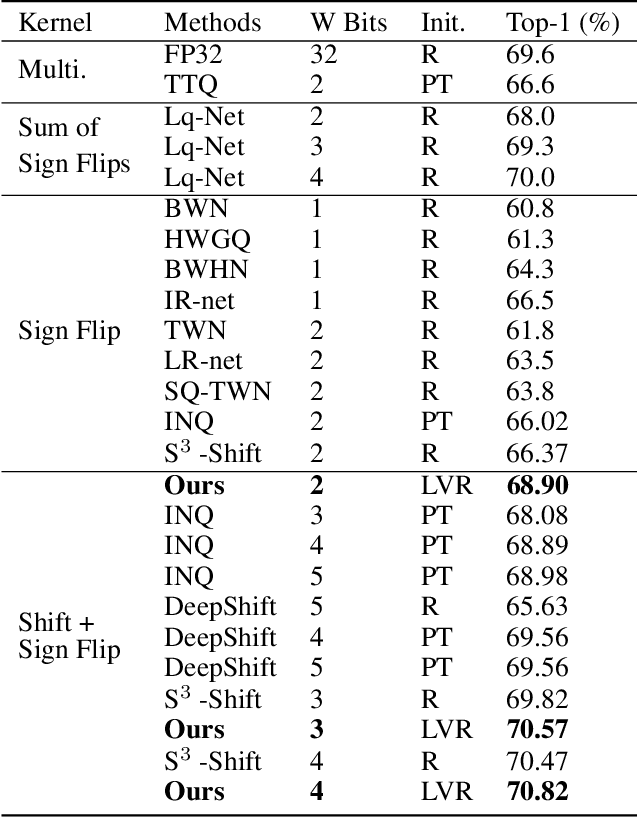
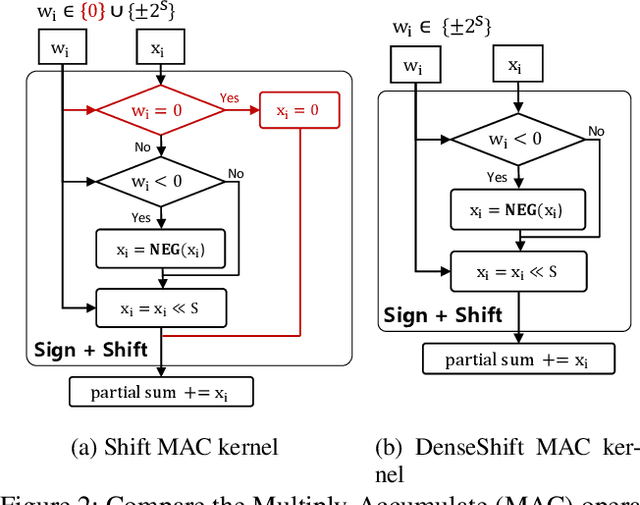
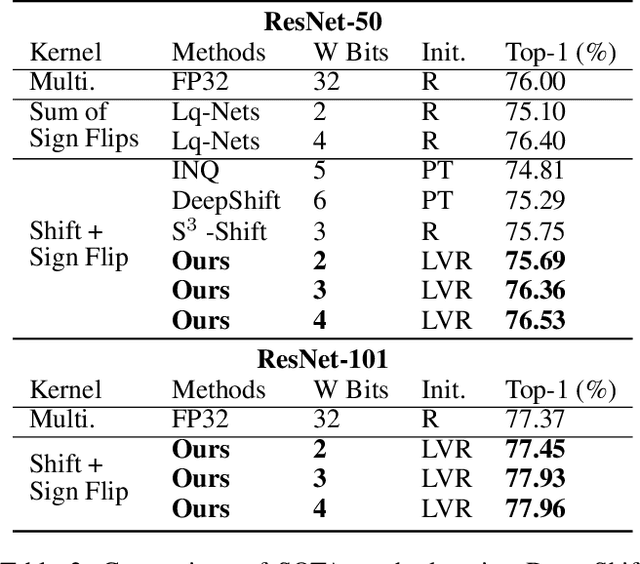
Deploying deep neural networks on low-resource edge devices is challenging due to their ever-increasing resource requirements. Recent investigations propose multiplication-free neural networks to reduce computation and memory consumption. Shift neural network is one of the most effective tools towards these reductions. However, existing low-bit shift networks are not as accurate as their full precision counterparts and cannot efficiently transfer to a wide range of tasks due to their inherent design flaws. We propose DenseShift network that exploits the following novel designs. First, we demonstrate that the zero-weight values in low-bit shift networks are neither useful to the model capacity nor simplify the model inference. Therefore, we propose to use a zero-free shifting mechanism to simplify inference while increasing the model capacity. Second, we design a new metric to measure the weight freezing issue in training low-bit shift networks, and propose a sign-scale decomposition to improve the training efficiency. Third, we propose the low-variance random initialization strategy to improve the model's performance in transfer learning scenarios. We run extensive experiments on various computer vision and speech tasks. The experimental results show that DenseShift network significantly outperforms existing low-bit multiplication-free networks and can achieve competitive performance to the full-precision counterpart. It also exhibits strong transfer learning performance with no drop in accuracy.
Low-bit Shift Network for End-to-End Spoken Language Understanding
Jul 15, 2022
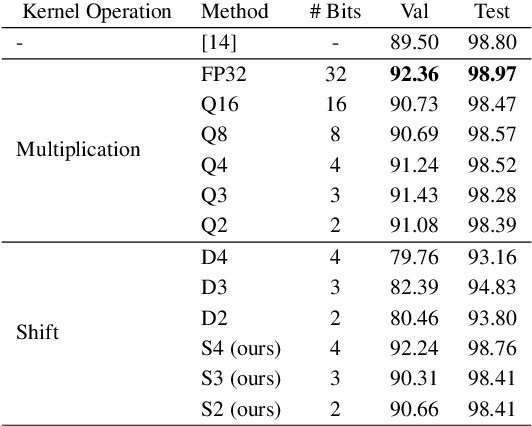
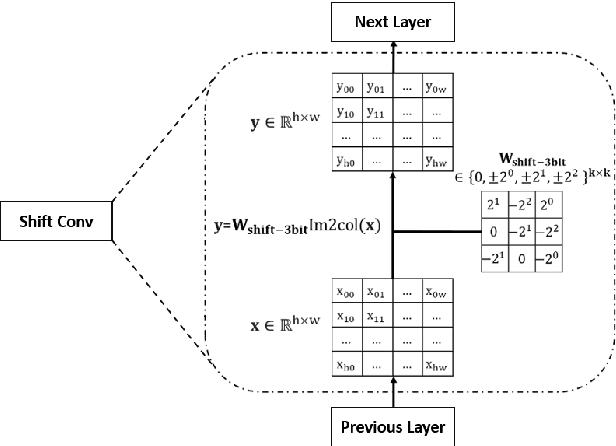
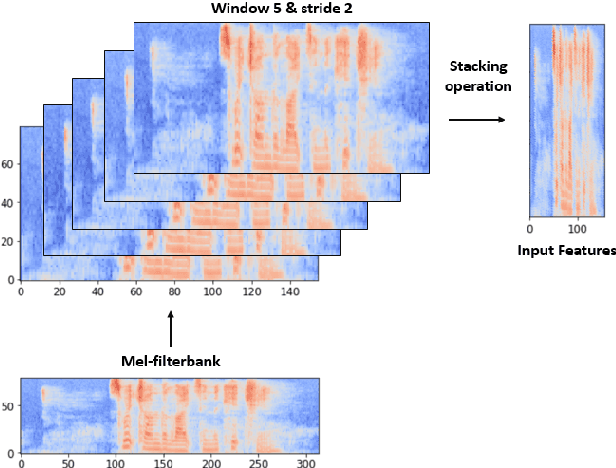
Deep neural networks (DNN) have achieved impressive success in multiple domains. Over the years, the accuracy of these models has increased with the proliferation of deeper and more complex architectures. Thus, state-of-the-art solutions are often computationally expensive, which makes them unfit to be deployed on edge computing platforms. In order to mitigate the high computation, memory, and power requirements of inferring convolutional neural networks (CNNs), we propose the use of power-of-two quantization, which quantizes continuous parameters into low-bit power-of-two values. This reduces computational complexity by removing expensive multiplication operations and with the use of low-bit weights. ResNet is adopted as the building block of our solution and the proposed model is evaluated on a spoken language understanding (SLU) task. Experimental results show improved performance for shift neural network architectures, with our low-bit quantization achieving 98.76 \% on the test set which is comparable performance to its full-precision counterpart and state-of-the-art solutions.
Deep Neural Networks pruning via the Structured Perspective Regularization
Jun 28, 2022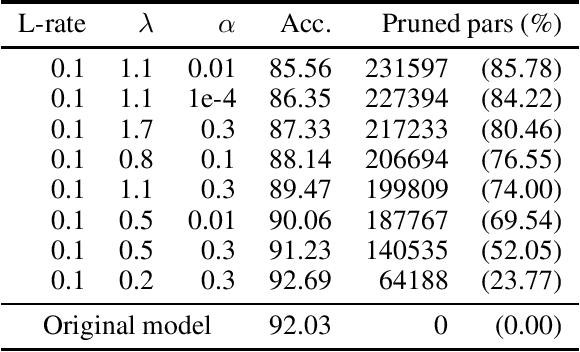
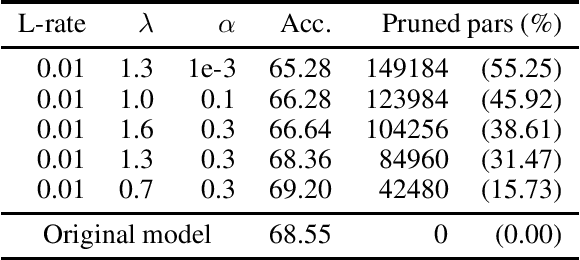
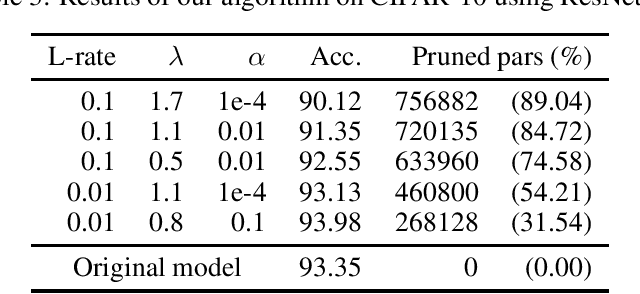
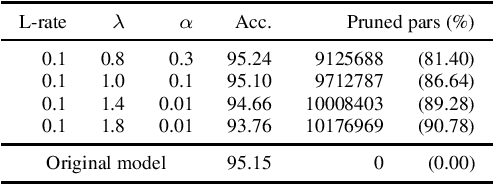
In Machine Learning, Artificial Neural Networks (ANNs) are a very powerful tool, broadly used in many applications. Often, the selected (deep) architectures include many layers, and therefore a large amount of parameters, which makes training, storage and inference expensive. This motivated a stream of research about compressing the original networks into smaller ones without excessively sacrificing performances. Among the many proposed compression approaches, one of the most popular is \emph{pruning}, whereby entire elements of the ANN (links, nodes, channels, \ldots) and the corresponding weights are deleted. Since the nature of the problem is inherently combinatorial (what elements to prune and what not), we propose a new pruning method based on Operational Research tools. We start from a natural Mixed-Integer-Programming model for the problem, and we use the Perspective Reformulation technique to strengthen its continuous relaxation. Projecting away the indicator variables from this reformulation yields a new regularization term, which we call the Structured Perspective Regularization, that leads to structured pruning of the initial architecture. We test our method on some ResNet architectures applied to CIFAR-10, CIFAR-100 and ImageNet datasets, obtaining competitive performances w.r.t.~the state of the art for structured pruning.
$S^3$: Sign-Sparse-Shift Reparametrization for Effective Training of Low-bit Shift Networks
Jul 07, 2021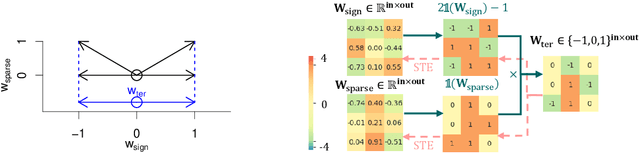



Shift neural networks reduce computation complexity by removing expensive multiplication operations and quantizing continuous weights into low-bit discrete values, which are fast and energy efficient compared to conventional neural networks. However, existing shift networks are sensitive to the weight initialization, and also yield a degraded performance caused by vanishing gradient and weight sign freezing problem. To address these issues, we propose S low-bit re-parameterization, a novel technique for training low-bit shift networks. Our method decomposes a discrete parameter in a sign-sparse-shift 3-fold manner. In this way, it efficiently learns a low-bit network with a weight dynamics similar to full-precision networks and insensitive to weight initialization. Our proposed training method pushes the boundaries of shift neural networks and shows 3-bit shift networks out-performs their full-precision counterparts in terms of top-1 accuracy on ImageNet.