 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLIPO: Contrastive Learning in Policy Optimization Generalizes RLVR
Mar 10, 2026Reinforcement Learning with Verifiable Rewards (RLVR) has significantly advanced the reasoning capacity of Large Language Models (LLMs). However, RLVR solely relies on final answers as outcome rewards, neglecting the correctness of intermediate reasoning steps. Training on these process-wrong but outcome-correct rollouts can lead to hallucination and answer-copying, severely undermining the model's generalization and robustness. To address this, we incorporate a Contrastive Learning mechanism into the Policy Optimization (CLIPO) to generalize the RLVR process. By optimizing a contrastive loss over successful rollouts, CLIPO steers the LLM to capture the invariant structure shared across correct reasoning paths. This provides a more robust cross-trajectory regularization than the original single-path supervision in RLVR, effectively mitigating step-level reasoning inconsistencies and suppressing hallucinatory artifacts. In experiments, CLIPO consistently improves multiple RLVR baselines across diverse reasoning benchmarks, demonstrating uniform improvements in generalization and robustness for policy optimization of LLMs. Our code and training recipes are available at https://github.com/Qwen-Applications/CLIPO.
Moment Alignment: Unifying Gradient and Hessian Matching for Domain Generalization
Jun 09, 2025Domain generalization (DG) seeks to develop models that generalize well to unseen target domains, addressing the prevalent issue of distribution shifts in real-world applications. One line of research in DG focuses on aligning domain-level gradients and Hessians to enhance generalization. However, existing methods are computationally inefficient and the underlying principles of these approaches are not well understood. In this paper, we develop the theory of moment alignment for DG. Grounded in \textit{transfer measure}, a principled framework for quantifying generalizability between two domains, we first extend the definition of transfer measure to domain generalization that includes multiple source domains and establish a target error bound. Then, we prove that aligning derivatives across domains improves transfer measure both when the feature extractor induces an invariant optimal predictor across domains and when it does not. Notably, moment alignment provides a unifying understanding of Invariant Risk Minimization, gradient matching, and Hessian matching, three previously disconnected approaches to DG. We further connect feature moments and derivatives of the classifier head, and establish the duality between feature learning and classifier fitting. Building upon our theory, we introduce \textbf{C}losed-Form \textbf{M}oment \textbf{A}lignment (CMA), a novel DG algorithm that aligns domain-level gradients and Hessians in closed-form. Our method overcomes the computational inefficiencies of existing gradient and Hessian-based techniques by eliminating the need for repeated backpropagation or sampling-based Hessian estimation. We validate the efficacy of our approach through two sets of experiments: linear probing and full fine-tuning. CMA demonstrates superior performance in both settings compared to Empirical Risk Minimization and state-of-the-art algorithms.
MiniMax-01: Scaling Foundation Models with Lightning Attention
Jan 14, 2025We introduce MiniMax-01 series, including MiniMax-Text-01 and MiniMax-VL-01, which are comparable to top-tier models while offering superior capabilities in processing longer contexts. The core lies in lightning attention and its efficient scaling. To maximize computational capacity, we integrate it with Mixture of Experts (MoE), creating a model with 32 experts and 456 billion total parameters, of which 45.9 billion are activated for each token. We develop an optimized parallel strategy and highly efficient computation-communication overlap techniques for MoE and lightning attention. This approach enables us to conduct efficient training and inference on models with hundreds of billions of parameters across contexts spanning millions of tokens. The context window of MiniMax-Text-01 can reach up to 1 million tokens during training and extrapolate to 4 million tokens during inference at an affordable cost. Our vision-language model, MiniMax-VL-01 is built through continued training with 512 billion vision-language tokens. Experiments on both standard and in-house benchmarks show that our models match the performance of state-of-the-art models like GPT-4o and Claude-3.5-Sonnet while offering 20-32 times longer context window. We publicly release MiniMax-01 at https://github.com/MiniMax-AI.
FedLog: Personalized Federated Classification with Less Communication and More Flexibility
Jul 11, 2024



In federated learning (FL), the common paradigm that FedAvg proposes and most algorithms follow is that clients train local models with their private data, and the model parameters are shared for central aggregation, mostly averaging. In this paradigm, the communication cost is often a challenge, as modern massive neural networks can contain millions to billions parameters. We suggest that clients do not share model parameters but local data summaries, to decrease the cost of sharing. We develop a new algorithm FedLog with Bayesian inference, which shares only sufficient statistics of local data. FedLog transmits messages as small as the last layer of the original model. We conducted comprehensive experiments to show we outperform other FL algorithms that aim at decreasing the communication cost. To provide formal privacy guarantees, we further extend FedLog with differential privacy and show the trade-off between privacy budget and accuracy.
Alignment Calibration: Machine Unlearning for Contrastive Learning under Auditing
Jun 05, 2024



Machine unlearning provides viable solutions to revoke the effect of certain training data on pre-trained model parameters. Existing approaches provide unlearning recipes for classification and generative models. However, a category of important machine learning models, i.e., contrastive learning (CL) methods, is overlooked. In this paper, we fill this gap by first proposing the framework of Machine Unlearning for Contrastive learning (MUC) and adapting existing methods. Furthermore, we observe that several methods are mediocre unlearners and existing auditing tools may not be sufficient for data owners to validate the unlearning effects in contrastive learning. We thus propose a novel method called Alignment Calibration (AC) by explicitly considering the properties of contrastive learning and optimizing towards novel auditing metrics to easily verify unlearning. We empirically compare AC with baseline methods on SimCLR, MoCo and CLIP. We observe that AC addresses drawbacks of existing methods: (1) achieving state-of-the-art performance and approximating exact unlearning (retraining); (2) allowing data owners to clearly visualize the effect caused by unlearning through black-box auditing.
Does Combining Parameter-efficient Modules Improve Few-shot Transfer Accuracy?
Feb 23, 2024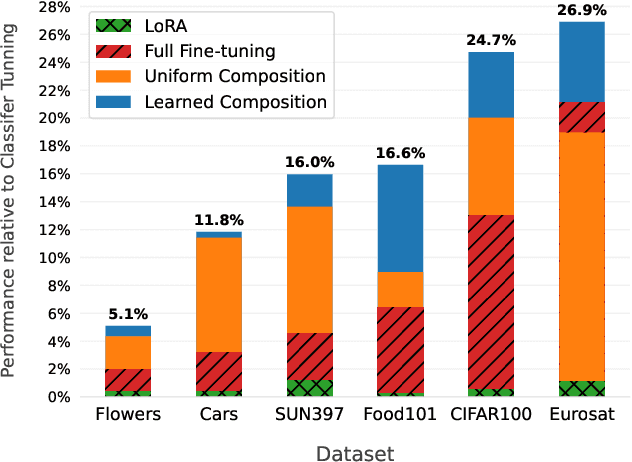
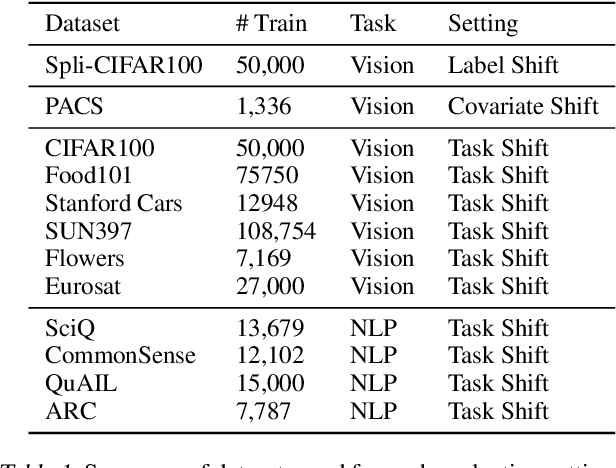
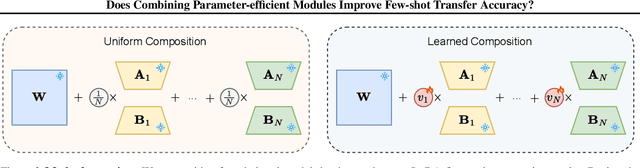
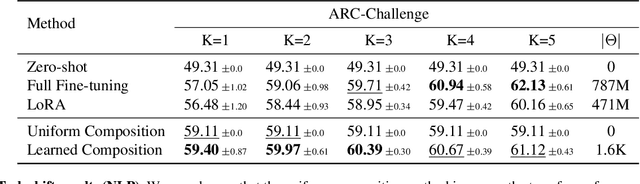
Parameter-efficient fine-tuning stands as the standard for efficiently fine-tuning large language and vision models on downstream tasks. Specifically, the efficiency of low-rank adaptation has facilitated the creation and sharing of hundreds of custom LoRA modules, each trained on distinct data from various downstream tasks. In this paper, we explore the composability of LoRA modules, examining if combining these pre-trained modules enhances generalization to unseen downstream tasks. Our investigation involves evaluating two approaches: (a) uniform composition, involving averaging upstream LoRA modules with equal weights, and (b) learned composition, where we learn the weights for each upstream module and perform weighted averaging. Our experimental results on both vision and language models reveal that in few-shot settings, where only a limited number of samples are available for the downstream task, both uniform and learned composition methods result in better transfer accuracy; outperforming full fine-tuning and training a LoRA from scratch. Moreover, in full-shot settings, learned composition performs comparably to regular LoRA training with significantly fewer number of trainable parameters. Our research unveils the potential of uniform composition for enhancing transferability in low-shot settings, without introducing additional learnable parameters.
$f$-MICL: Understanding and Generalizing InfoNCE-based Contrastive Learning
Feb 15, 2024



In self-supervised contrastive learning, a widely-adopted objective function is InfoNCE, which uses the heuristic cosine similarity for the representation comparison, and is closely related to maximizing the Kullback-Leibler (KL)-based mutual information. In this paper, we aim at answering two intriguing questions: (1) Can we go beyond the KL-based objective? (2) Besides the popular cosine similarity, can we design a better similarity function? We provide answers to both questions by generalizing the KL-based mutual information to the $f$-Mutual Information in Contrastive Learning ($f$-MICL) using the $f$-divergences. To answer the first question, we provide a wide range of $f$-MICL objectives which share the nice properties of InfoNCE (e.g., alignment and uniformity), and meanwhile result in similar or even superior performance. For the second question, assuming that the joint feature distribution is proportional to the Gaussian kernel, we derive an $f$-Gaussian similarity with better interpretability and empirical performance. Finally, we identify close relationships between the $f$-MICL objective and several popular InfoNCE-based objectives. Using benchmark tasks from both vision and natural language, we empirically evaluate $f$-MICL with different $f$-divergences on various architectures (SimCLR, MoCo, and MoCo v3) and datasets. We observe that $f$-MICL generally outperforms the benchmarks and the best-performing $f$-divergence is task and dataset dependent.
Robust Multi-Task Learning with Excess Risks
Feb 14, 2024



Multi-task learning (MTL) considers learning a joint model for multiple tasks by optimizing a convex combination of all task losses. To solve the optimization problem, existing methods use an adaptive weight updating scheme, where task weights are dynamically adjusted based on their respective losses to prioritize difficult tasks. However, these algorithms face a great challenge whenever label noise is present, in which case excessive weights tend to be assigned to noisy tasks that have relatively large Bayes optimal errors, thereby overshadowing other tasks and causing performance to drop across the board. To overcome this limitation, we propose Multi-Task Learning with Excess Risks (ExcessMTL), an excess risk-based task balancing method that updates the task weights by their distances to convergence instead. Intuitively, ExcessMTL assigns higher weights to worse-trained tasks that are further from convergence. To estimate the excess risks, we develop an efficient and accurate method with Taylor approximation. Theoretically, we show that our proposed algorithm achieves convergence guarantees and Pareto stationarity. Empirically, we evaluate our algorithm on various MTL benchmarks and demonstrate its superior performance over existing methods in the presence of label noise.
DFML: Decentralized Federated Mutual Learning
Feb 02, 2024In the realm of real-world devices, centralized servers in Federated Learning (FL) present challenges including communication bottlenecks and susceptibility to a single point of failure. Additionally, contemporary devices inherently exhibit model and data heterogeneity. Existing work lacks a Decentralized FL (DFL) framework capable of accommodating such heterogeneity without imposing architectural restrictions or assuming the availability of public data. To address these issues, we propose a Decentralized Federated Mutual Learning (DFML) framework that is serverless, supports nonrestrictive heterogeneous models, and avoids reliance on public data. DFML effectively handles model and data heterogeneity through mutual learning, which distills knowledge between clients, and cyclically varying the amount of supervision and distillation signals. Extensive experimental results demonstrate consistent effectiveness of DFML in both convergence speed and global accuracy, outperforming prevalent baselines under various conditions. For example, with the CIFAR-100 dataset and 50 clients, DFML achieves a substantial increase of +17.20% and +19.95% in global accuracy under Independent and Identically Distributed (IID) and non-IID data shifts, respectively.
Parametric Feature Transfer: One-shot Federated Learning with Foundation Models
Feb 02, 2024In one-shot federated learning (FL), clients collaboratively train a global model in a single round of communication. Existing approaches for one-shot FL enhance communication efficiency at the expense of diminished accuracy. This paper introduces FedPFT (Federated Learning with Parametric Feature Transfer), a methodology that harnesses the transferability of foundation models to enhance both accuracy and communication efficiency in one-shot FL. The approach involves transferring per-client parametric models (specifically, Gaussian mixtures) of features extracted from foundation models. Subsequently, each parametric model is employed to generate synthetic features for training a classifier head. Experimental results on eight datasets demonstrate that FedPFT enhances the communication-accuracy frontier in both centralized and decentralized FL scenarios, as well as across diverse data-heterogeneity settings such as covariate shift and task shift, with improvements of up to 20.6%. Additionally, FedPFT adheres to the data minimization principle of FL, as clients do not send real features. We demonstrate that sending real features is vulnerable to potent reconstruction attacks. Moreover, we show that FedPFT is amenable to formal privacy guarantees via differential privacy, demonstrating favourable privacy-accuracy tradeoffs.