 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMergeBench: A Benchmark for Merging Domain-Specialized LLMs
May 16, 2025Model merging provides a scalable alternative to multi-task training by combining specialized finetuned models through parameter arithmetic, enabling efficient deployment without the need for joint training or access to all task data. While recent methods have shown promise, existing evaluations are limited in both model scale and task diversity, leaving open questions about their applicability to large, domain-specialized LLMs. To tackle the challenges, we introduce MergeBench, a comprehensive evaluation suite designed to assess model merging at scale. MergeBench builds on state-of-the-art open-source language models, including Llama and Gemma families at 2B to 9B scales, and covers five key domains: instruction following, mathematics, multilingual understanding, coding and safety. We standardize finetuning and evaluation protocols, and assess eight representative merging methods across multi-task performance, forgetting and runtime efficiency. Based on extensive experiments, we provide practical guidelines for algorithm selection and share insights showing that model merging tends to perform better on stronger base models, with techniques such as merging coefficient tuning and sparsification improving knowledge retention. However, several challenges remain, including the computational cost on large models, the gap for in-domain performance compared to multi-task models, and the underexplored role of model merging in standard LLM training pipelines. We hope MergeBench provides a foundation for future research to advance the understanding and practical application of model merging. We open source our code at \href{https://github.com/uiuctml/MergeBench}{https://github.com/uiuctml/MergeBench}.
Optimizing FDTD Solvers for Electromagnetics: A Compiler-Guided Approach with High-Level Tensor Abstractions
Apr 12, 2025The Finite Difference Time Domain (FDTD) method is a widely used numerical technique for solving Maxwell's equations, particularly in computational electromagnetics and photonics. It enables accurate modeling of wave propagation in complex media and structures but comes with significant computational challenges. Traditional FDTD implementations rely on handwritten, platform-specific code that optimizes certain kernels while underperforming in others. The lack of portability increases development overhead and creates performance bottlenecks, limiting scalability across modern hardware architectures. To address these challenges, we introduce an end-to-end domain-specific compiler based on the MLIR/LLVM infrastructure for FDTD simulations. Our approach generates efficient and portable code optimized for diverse hardware platforms.We implement the three-dimensional FDTD kernel as operations on a 3D tensor abstraction with explicit computational semantics. High-level optimizations such as loop tiling, fusion, and vectorization are automatically applied by the compiler. We evaluate our customized code generation pipeline on Intel, AMD, and ARM platforms, achieving up to $10\times$ speedup over baseline Python implementation using NumPy.
Efficient Model Editing with Task Vector Bases: A Theoretical Framework and Scalable Approach
Feb 03, 2025

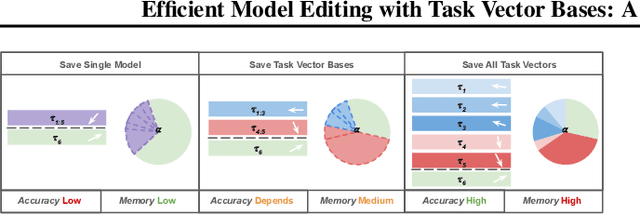

Task vectors, which are derived from the difference between pre-trained and fine-tuned model weights, enable flexible task adaptation and model merging through arithmetic operations such as addition and negation. However, existing approaches often rely on heuristics with limited theoretical support, often leading to performance gaps comparing to direct task fine tuning. Meanwhile, although it is easy to manipulate saved task vectors with arithmetic for different purposes, such compositional flexibility demands high memory usage, especially when dealing with a huge number of tasks, limiting scalability. This work addresses these issues with a theoretically grounded framework that explains task vector arithmetic and introduces the task vector bases framework. Building upon existing task arithmetic literature, our method significantly reduces the memory cost for downstream arithmetic with little effort, while achieving competitive performance and maintaining compositional advantage, providing a practical solution for large-scale task arithmetic.
MICCAI-CDMRI 2023 QuantConn Challenge Findings on Achieving Robust Quantitative Connectivity through Harmonized Preprocessing of Diffusion MRI
Nov 14, 2024



White matter alterations are increasingly implicated in neurological diseases and their progression. International-scale studies use diffusion-weighted magnetic resonance imaging (DW-MRI) to qualitatively identify changes in white matter microstructure and connectivity. Yet, quantitative analysis of DW-MRI data is hindered by inconsistencies stemming from varying acquisition protocols. There is a pressing need to harmonize the preprocessing of DW-MRI datasets to ensure the derivation of robust quantitative diffusion metrics across acquisitions. In the MICCAI-CDMRI 2023 QuantConn challenge, participants were provided raw data from the same individuals collected on the same scanner but with two different acquisitions and tasked with preprocessing the DW-MRI to minimize acquisition differences while retaining biological variation. Submissions are evaluated on the reproducibility and comparability of cross-acquisition bundle-wise microstructure measures, bundle shape features, and connectomics. The key innovations of the QuantConn challenge are that (1) we assess bundles and tractography in the context of harmonization for the first time, (2) we assess connectomics in the context of harmonization for the first time, and (3) we have 10x additional subjects over prior harmonization challenge, MUSHAC and 100x over SuperMUDI. We find that bundle surface area, fractional anisotropy, connectome assortativity, betweenness centrality, edge count, modularity, nodal strength, and participation coefficient measures are most biased by acquisition and that machine learning voxel-wise correction, RISH mapping, and NeSH methods effectively reduce these biases. In addition, microstructure measures AD, MD, RD, bundle length, connectome density, efficiency, and path length are least biased by these acquisition differences.
* Accepted for publication at the Journal of Machine Learning for Biomedical Imaging (MELBA) https://melba-journal.org/2024/019
Towards Understanding the Fragility of Multilingual LLMs against Fine-Tuning Attacks
Oct 23, 2024Recent advancements in Large Language Models (LLMs) have sparked widespread concerns about their safety. Recent work demonstrates that safety alignment of LLMs can be easily removed by fine-tuning with a few adversarially chosen instruction-following examples, i.e., fine-tuning attacks. We take a further step to understand fine-tuning attacks in multilingual LLMs. We first discover cross-lingual generalization of fine-tuning attacks: using a few adversarially chosen instruction-following examples in one language, multilingual LLMs can also be easily compromised (e.g., multilingual LLMs fail to refuse harmful prompts in other languages). Motivated by this finding, we hypothesize that safety-related information is language-agnostic and propose a new method termed Safety Information Localization (SIL) to identify the safety-related information in the model parameter space. Through SIL, we validate this hypothesis and find that only changing 20% of weight parameters in fine-tuning attacks can break safety alignment across all languages. Furthermore, we provide evidence to the alternative pathways hypothesis for why freezing safety-related parameters does not prevent fine-tuning attacks, and we demonstrate that our attack vector can still jailbreak LLMs adapted to new languages.
Scaling Laws for Multilingual Language Models
Oct 15, 2024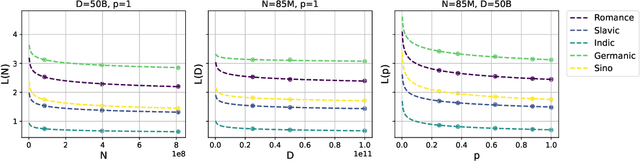

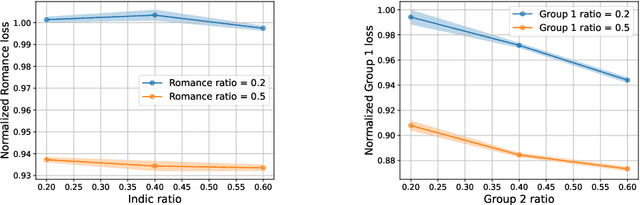
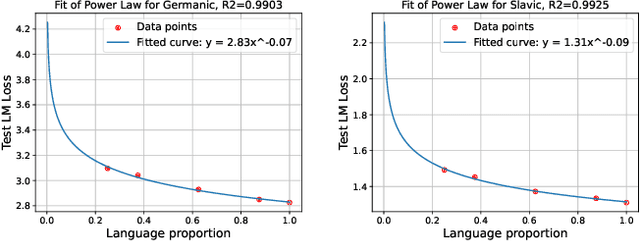
We propose a novel scaling law for general-purpose decoder-only language models (LMs) trained on multilingual data, addressing the problem of balancing languages during multilingual pretraining. A primary challenge in studying multilingual scaling is the difficulty of analyzing individual language performance due to cross-lingual transfer. To address this, we shift the focus from individual languages to language families. We introduce and validate a hypothesis that the test cross-entropy loss for each language family is determined solely by its own sampling ratio, independent of other languages in the mixture. This insight simplifies the complexity of multilingual scaling and make the analysis scalable to an arbitrary number of languages. Building on this hypothesis, we derive a power-law relationship that links performance with dataset size, model size and sampling ratios. This relationship enables us to predict performance across various combinations of the above three quantities, and derive the optimal sampling ratios at different model scales. To demonstrate the effectiveness and accuracy of our proposed scaling law, we perform a large-scale empirical study, training more than 100 models on 23 languages spanning 5 language families. Our experiments show that the optimal sampling ratios derived from small models (85M parameters) generalize effectively to models that are several orders of magnitude larger (1.2B parameters), offering a resource-efficient approach for multilingual LM training at scale.
Semi-Supervised Reward Modeling via Iterative Self-Training
Sep 10, 2024Reward models (RM) capture the values and preferences of humans and play a central role in Reinforcement Learning with Human Feedback (RLHF) to align pretrained large language models (LLMs). Traditionally, training these models relies on extensive human-annotated preference data, which poses significant challenges in terms of scalability and cost. To overcome these limitations, we propose Semi-Supervised Reward Modeling (SSRM), an approach that enhances RM training using unlabeled data. Given an unlabeled dataset, SSRM involves three key iterative steps: pseudo-labeling unlabeled examples, selecting high-confidence examples through a confidence threshold, and supervised finetuning on the refined dataset. Across extensive experiments on various model configurations, we demonstrate that SSRM significantly improves reward models without incurring additional labeling costs. Notably, SSRM can achieve performance comparable to models trained entirely on labeled data of equivalent volumes. Overall, SSRM substantially reduces the dependency on large volumes of human-annotated data, thereby decreasing the overall cost and time involved in training effective reward models.
Localize-and-Stitch: Efficient Model Merging via Sparse Task Arithmetic
Aug 24, 2024Model merging offers an effective strategy to combine the strengths of multiple finetuned models into a unified model that preserves the specialized capabilities of each. Existing methods merge models in a global manner, performing arithmetic operations across all model parameters. However, such global merging often leads to task interference, degrading the performance of the merged model. In this work, we introduce Localize-and-Stitch, a novel approach that merges models in a localized way. Our algorithm works in two steps: i) Localization: identify tiny ($1\%$ of the total parameters) localized regions in the finetuned models containing essential skills for the downstream tasks, and ii) Stitching: reintegrate only these essential regions back into the pretrained model for task synergy. We demonstrate that our approach effectively locates sparse regions responsible for finetuned performance, and the localized regions could be treated as compact and interpretable representations of the finetuned models (tasks). Empirically, we evaluate our method on various vision and language benchmarks, showing that it outperforms existing model merging methods under different data availability scenarios. Beyond strong empirical performance, our algorithm also facilitates model compression and preserves pretrained knowledge, enabling flexible and continual skill composition from multiple finetuned models with minimal storage and computational overhead. Our code is available at https://github.com/yifei-he/Localize-and-Stitch.
Robust Multi-Task Learning with Excess Risks
Feb 14, 2024



Multi-task learning (MTL) considers learning a joint model for multiple tasks by optimizing a convex combination of all task losses. To solve the optimization problem, existing methods use an adaptive weight updating scheme, where task weights are dynamically adjusted based on their respective losses to prioritize difficult tasks. However, these algorithms face a great challenge whenever label noise is present, in which case excessive weights tend to be assigned to noisy tasks that have relatively large Bayes optimal errors, thereby overshadowing other tasks and causing performance to drop across the board. To overcome this limitation, we propose Multi-Task Learning with Excess Risks (ExcessMTL), an excess risk-based task balancing method that updates the task weights by their distances to convergence instead. Intuitively, ExcessMTL assigns higher weights to worse-trained tasks that are further from convergence. To estimate the excess risks, we develop an efficient and accurate method with Taylor approximation. Theoretically, we show that our proposed algorithm achieves convergence guarantees and Pareto stationarity. Empirically, we evaluate our algorithm on various MTL benchmarks and demonstrate its superior performance over existing methods in the presence of label noise.
Survey on Memory-Augmented Neural Networks: Cognitive Insights to AI Applications
Dec 13, 2023This paper explores Memory-Augmented Neural Networks (MANNs), delving into how they blend human-like memory processes into AI. It covers different memory types, like sensory, short-term, and long-term memory, linking psychological theories with AI applications. The study investigates advanced architectures such as Hopfield Networks, Neural Turing Machines, Correlation Matrix Memories, Memformer, and Neural Attention Memory, explaining how they work and where they excel. It dives into real-world uses of MANNs across Natural Language Processing, Computer Vision, Multimodal Learning, and Retrieval Models, showing how memory boosters enhance accuracy, efficiency, and reliability in AI tasks. Overall, this survey provides a comprehensive view of MANNs, offering insights for future research in memory-based AI systems.