 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeT-FIX: Text-Based Explanations with Features Interpretable to eXperts
Nov 06, 2025As LLMs are deployed in knowledge-intensive settings (e.g., surgery, astronomy, therapy), users expect not just answers, but also meaningful explanations for those answers. In these settings, users are often domain experts (e.g., doctors, astrophysicists, psychologists) who require explanations that reflect expert-level reasoning. However, current evaluation schemes primarily emphasize plausibility or internal faithfulness of the explanation, which fail to capture whether the content of the explanation truly aligns with expert intuition. We formalize expert alignment as a criterion for evaluating explanations with T-FIX, a benchmark spanning seven knowledge-intensive domains. In collaboration with domain experts, we develop novel metrics to measure the alignment of LLM explanations with expert judgment.
When LRP Diverges from Leave-One-Out in Transformers
Oct 21, 2025Leave-One-Out (LOO) provides an intuitive measure of feature importance but is computationally prohibitive. While Layer-Wise Relevance Propagation (LRP) offers a potentially efficient alternative, its axiomatic soundness in modern Transformers remains largely under-examined. In this work, we first show that the bilinear propagation rules used in recent advances of AttnLRP violate the implementation invariance axiom. We prove this analytically and confirm it empirically in linear attention layers. Second, we also revisit CP-LRP as a diagnostic baseline and find that bypassing relevance propagation through the softmax layer -- backpropagating relevance only through the value matrices -- significantly improves alignment with LOO, particularly in middle-to-late Transformer layers. Overall, our results suggest that (i) bilinear factorization sensitivity and (ii) softmax propagation error potentially jointly undermine LRP's ability to approximate LOO in Transformers.
Probabilistic Stability Guarantees for Feature Attributions
Apr 18, 2025Stability guarantees are an emerging tool for evaluating feature attributions, but existing certification methods rely on smoothed classifiers and often yield conservative guarantees. To address these limitations, we introduce soft stability and propose a simple, model-agnostic, and sample-efficient stability certification algorithm (SCA) that provides non-trivial and interpretable guarantees for any attribution. Moreover, we show that mild smoothing enables a graceful tradeoff between accuracy and stability, in contrast to prior certification methods that require a more aggressive compromise. Using Boolean function analysis, we give a novel characterization of stability under smoothing. We evaluate SCA on vision and language tasks, and demonstrate the effectiveness of soft stability in measuring the robustness of explanation methods.
NSF-SciFy: Mining the NSF Awards Database for Scientific Claims
Mar 11, 2025



We present NSF-SciFy, a large-scale dataset for scientific claim extraction derived from the National Science Foundation (NSF) awards database, comprising over 400K grant abstracts spanning five decades. While previous datasets relied on published literature, we leverage grant abstracts which offer a unique advantage: they capture claims at an earlier stage in the research lifecycle before publication takes effect. We also introduce a new task to distinguish between existing scientific claims and aspirational research intentions in proposals.Using zero-shot prompting with frontier large language models, we jointly extract 114K scientific claims and 145K investigation proposals from 16K grant abstracts in the materials science domain to create a focused subset called NSF-SciFy-MatSci. We use this dataset to evaluate 3 three key tasks: (1) technical to non-technical abstract generation, where models achieve high BERTScore (0.85+ F1); (2) scientific claim extraction, where fine-tuned models outperform base models by 100% relative improvement; and (3) investigation proposal extraction, showing 90%+ improvement with fine-tuning. We introduce novel LLM-based evaluation metrics for robust assessment of claim/proposal extraction quality. As the largest scientific claim dataset to date -- with an estimated 2.8 million claims across all STEM disciplines funded by the NSF -- NSF-SciFy enables new opportunities for claim verification and meta-scientific research. We publicly release all datasets, trained models, and evaluation code to facilitate further research.
Efficient Model Editing with Task Vector Bases: A Theoretical Framework and Scalable Approach
Feb 03, 2025

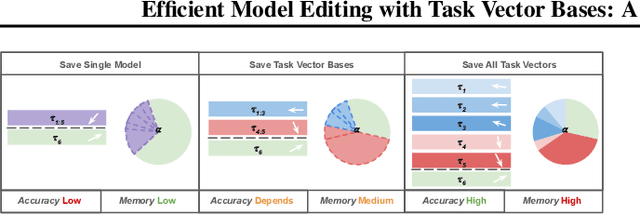

Task vectors, which are derived from the difference between pre-trained and fine-tuned model weights, enable flexible task adaptation and model merging through arithmetic operations such as addition and negation. However, existing approaches often rely on heuristics with limited theoretical support, often leading to performance gaps comparing to direct task fine tuning. Meanwhile, although it is easy to manipulate saved task vectors with arithmetic for different purposes, such compositional flexibility demands high memory usage, especially when dealing with a huge number of tasks, limiting scalability. This work addresses these issues with a theoretically grounded framework that explains task vector arithmetic and introduces the task vector bases framework. Building upon existing task arithmetic literature, our method significantly reduces the memory cost for downstream arithmetic with little effort, while achieving competitive performance and maintaining compositional advantage, providing a practical solution for large-scale task arithmetic.
Cyber-Attack Technique Classification Using Two-Stage Trained Large Language Models
Nov 27, 2024



Understanding the attack patterns associated with a cyberattack is crucial for comprehending the attacker's behaviors and implementing the right mitigation measures. However, majority of the information regarding new attacks is typically presented in unstructured text, posing significant challenges for security analysts in collecting necessary information. In this paper, we present a sentence classification system that can identify the attack techniques described in natural language sentences from cyber threat intelligence (CTI) reports. We propose a new method for utilizing auxiliary data with the same labels to improve classification for the low-resource cyberattack classification task. The system first trains the model using the augmented training data and then trains more using only the primary data. We validate our model using the TRAM data1 and the MITRE ATT&CK framework. Experiments show that our method enhances Macro-F1 by 5 to 9 percentage points and keeps Micro-F1 scores competitive when compared to the baseline performance on the TRAM dataset.
The FIX Benchmark: Extracting Features Interpretable to eXperts
Sep 20, 2024

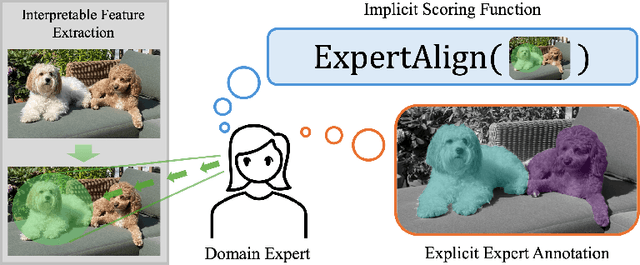
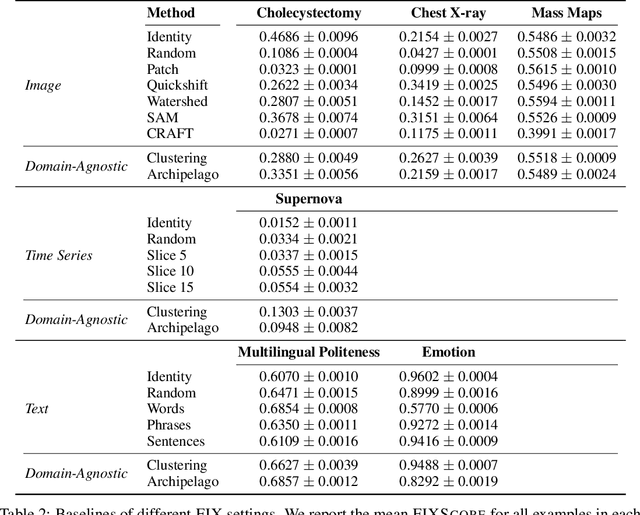
Feature-based methods are commonly used to explain model predictions, but these methods often implicitly assume that interpretable features are readily available. However, this is often not the case for high-dimensional data, and it can be hard even for domain experts to mathematically specify which features are important. Can we instead automatically extract collections or groups of features that are aligned with expert knowledge? To address this gap, we present FIX (Features Interpretable to eXperts), a benchmark for measuring how well a collection of features aligns with expert knowledge. In collaboration with domain experts, we have developed feature interpretability objectives across diverse real-world settings and unified them into a single framework that is the FIX benchmark. We find that popular feature-based explanation methods have poor alignment with expert-specified knowledge, highlighting the need for new methods that can better identify features interpretable to experts.
Sum-of-Parts Models: Faithful Attributions for Groups of Features
Oct 25, 2023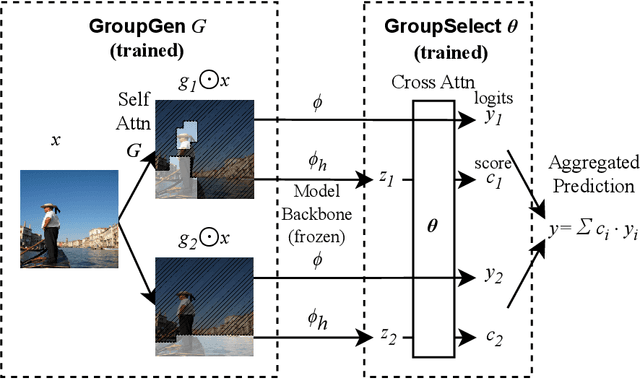
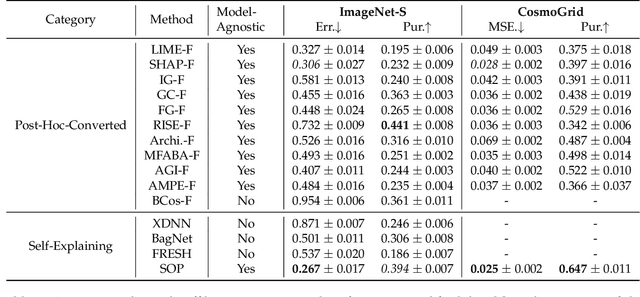

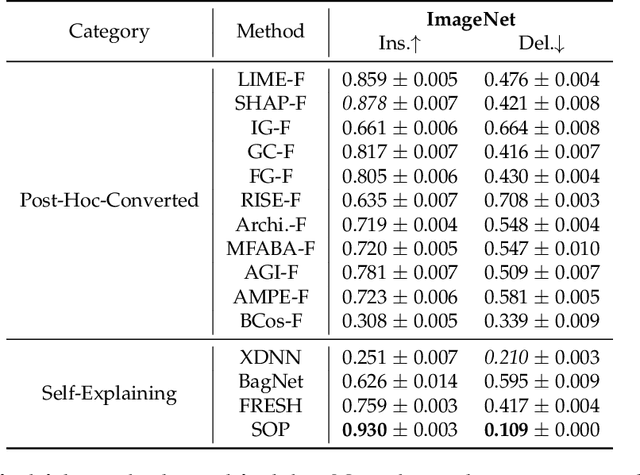
An explanation of a machine learning model is considered "faithful" if it accurately reflects the model's decision-making process. However, explanations such as feature attributions for deep learning are not guaranteed to be faithful, and can produce potentially misleading interpretations. In this work, we develop Sum-of-Parts (SOP), a class of models whose predictions come with grouped feature attributions that are faithful-by-construction. This model decomposes a prediction into an interpretable sum of scores, each of which is directly attributable to a sparse group of features. We evaluate SOP on benchmarks with standard interpretability metrics, and in a case study, we use the faithful explanations from SOP to help astrophysicists discover new knowledge about galaxy formation.
Causal Reasoning of Entities and Events in Procedural Texts
Jan 29, 2023
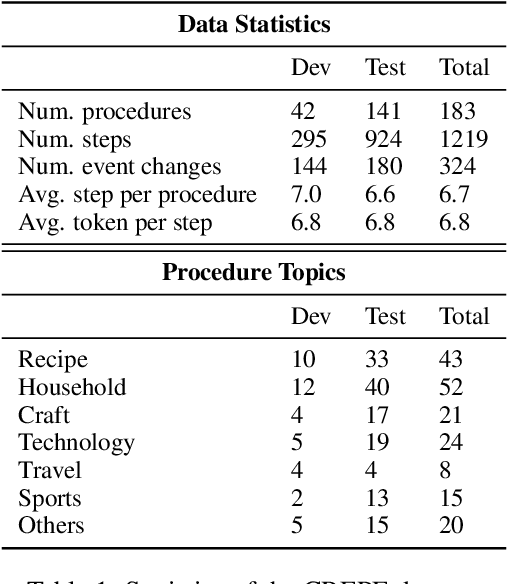


Entities and events have long been regarded as the crux of machine reasoning. Specifically, procedural texts have received increasing attention due to the dynamic nature of involved entities and events. Existing work has exclusively focused on entity state tracking (e.g., the temperature of a pan) or counterfactual event reasoning (e.g., how likely am I to burn myself by touching the pan), while these two tasks are tightly intertwined. In this work, we propose CREPE, the first benchmark on causal reasoning about event plausibility based on entity states. We experiment with strong large language models and show that most models including GPT3 perform close to chance of .30 F1, lagging far behind the human performance of .87 F1. Inspired by the finding that structured representations such as programming languages benefits event reasoning as a prompt to code language models such as Codex, we creatively inject the causal relations between entities and events through intermediate variables and boost the performance to .67 to .72 F1. Our proposed event representation not only allows for knowledge injection, but also marks the first successful attempt of chain-of-thought reasoning with code language models.
Macro-Average: Rare Types Are Important Too
Apr 12, 2021
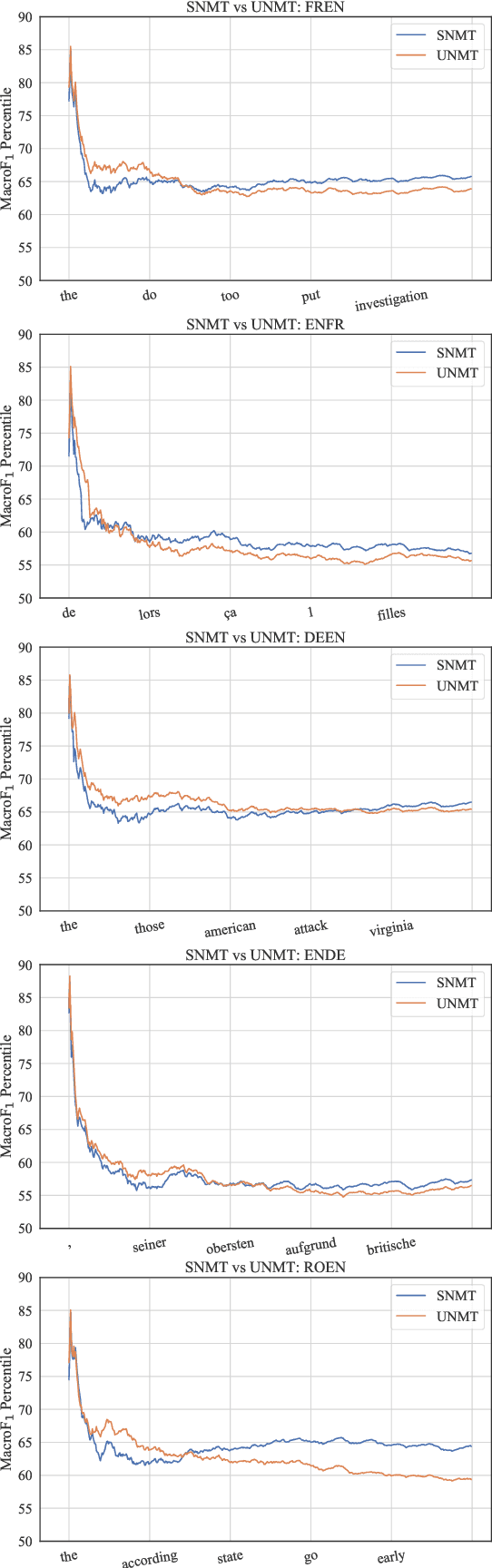
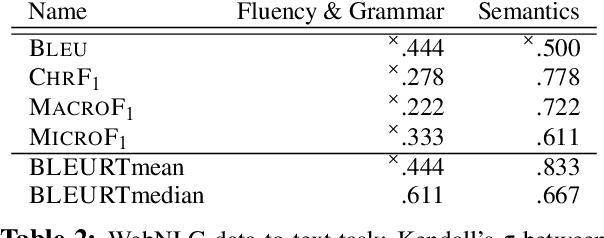
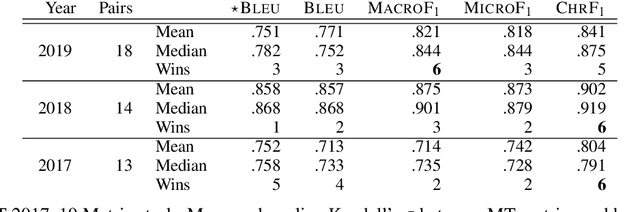
While traditional corpus-level evaluation metrics for machine translation (MT) correlate well with fluency, they struggle to reflect adequacy. Model-based MT metrics trained on segment-level human judgments have emerged as an attractive replacement due to strong correlation results. These models, however, require potentially expensive re-training for new domains and languages. Furthermore, their decisions are inherently non-transparent and appear to reflect unwelcome biases. We explore the simple type-based classifier metric, MacroF1, and study its applicability to MT evaluation. We find that MacroF1 is competitive on direct assessment, and outperforms others in indicating downstream cross-lingual information retrieval task performance. Further, we show that MacroF1 can be used to effectively compare supervised and unsupervised neural machine translation, and reveal significant qualitative differences in the methods' outputs.