 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCyber-Attack Technique Classification Using Two-Stage Trained Large Language Models
Nov 27, 2024



Understanding the attack patterns associated with a cyberattack is crucial for comprehending the attacker's behaviors and implementing the right mitigation measures. However, majority of the information regarding new attacks is typically presented in unstructured text, posing significant challenges for security analysts in collecting necessary information. In this paper, we present a sentence classification system that can identify the attack techniques described in natural language sentences from cyber threat intelligence (CTI) reports. We propose a new method for utilizing auxiliary data with the same labels to improve classification for the low-resource cyberattack classification task. The system first trains the model using the augmented training data and then trains more using only the primary data. We validate our model using the TRAM data1 and the MITRE ATT&CK framework. Experiments show that our method enhances Macro-F1 by 5 to 9 percentage points and keeps Micro-F1 scores competitive when compared to the baseline performance on the TRAM dataset.
Towards Generating Informative Textual Description for Neurons in Language Models
Jan 30, 2024Recent developments in transformer-based language models have allowed them to capture a wide variety of world knowledge that can be adapted to downstream tasks with limited resources. However, what pieces of information are understood in these models is unclear, and neuron-level contributions in identifying them are largely unknown. Conventional approaches in neuron explainability either depend on a finite set of pre-defined descriptors or require manual annotations for training a secondary model that can then explain the neurons of the primary model. In this paper, we take BERT as an example and we try to remove these constraints and propose a novel and scalable framework that ties textual descriptions to neurons. We leverage the potential of generative language models to discover human-interpretable descriptors present in a dataset and use an unsupervised approach to explain neurons with these descriptors. Through various qualitative and quantitative analyses, we demonstrate the effectiveness of this framework in generating useful data-specific descriptors with little human involvement in identifying the neurons that encode these descriptors. In particular, our experiment shows that the proposed approach achieves 75% precision@2, and 50% recall@2
Split-NER: Named Entity Recognition via Two Question-Answering-based Classifications
Oct 30, 2023



In this work, we address the NER problem by splitting it into two logical sub-tasks: (1) Span Detection which simply extracts entity mention spans irrespective of entity type; (2) Span Classification which classifies the spans into their entity types. Further, we formulate both sub-tasks as question-answering (QA) problems and produce two leaner models which can be optimized separately for each sub-task. Experiments with four cross-domain datasets demonstrate that this two-step approach is both effective and time efficient. Our system, SplitNER outperforms baselines on OntoNotes5.0, WNUT17 and a cybersecurity dataset and gives on-par performance on BioNLP13CG. In all cases, it achieves a significant reduction in training time compared to its QA baseline counterpart. The effectiveness of our system stems from fine-tuning the BERT model twice, separately for span detection and classification. The source code can be found at https://github.com/c3sr/split-ner.
Looking Beyond IoCs: Automatically Extracting Attack Patterns from External CTI
Nov 01, 2022



Public and commercial companies extensively share cyber threat intelligence (CTI) to prepare systems to defend against emerging cyberattacks. Most used intelligence thus far has been limited to tracking known threat indicators such as IP addresses and domain names as they are easier to extract using regular expressions. Due to the limited long-term usage and difficulty of performing a long-term analysis on indicators, we propose using significantly more robust threat intelligence signals called attack patterns. However, extracting attack patterns at scale is a challenging task. In this paper, we present LADDER, a knowledge extraction framework that can extract text-based attack patterns from CTI reports at scale. The model characterizes attack patterns by capturing phases of an attack in android and enterprise networks. It then systematically maps them to the MITRE ATT\&CK pattern framework. We present several use cases to demonstrate the application of LADDER for SOC analysts in determining the presence of attack vectors belonging to emerging attacks in preparation for defenses in advance.
CyNER: A Python Library for Cybersecurity Named Entity Recognition
Apr 08, 2022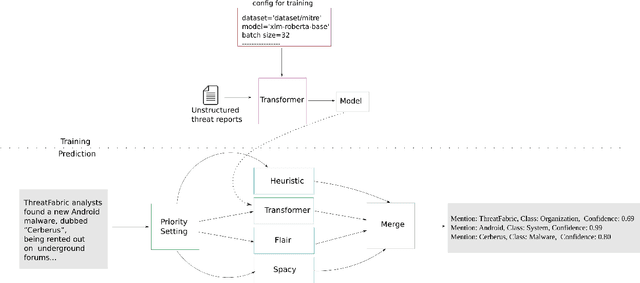


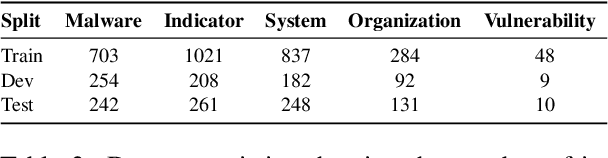
Open Cyber threat intelligence (OpenCTI) information is available in an unstructured format from heterogeneous sources on the Internet. We present CyNER, an open-source python library for cybersecurity named entity recognition (NER). CyNER combines transformer-based models for extracting cybersecurity-related entities, heuristics for extracting different indicators of compromise, and publicly available NER models for generic entity types. We provide models trained on a diverse corpus that users can readily use. Events are described as classes in previous research - MALOnt2.0 (Christian et al., 2021) and MALOnt (Rastogi et al., 2020) and together extract a wide range of malware attack details from a threat intelligence corpus. The user can combine predictions from multiple different approaches to suit their needs. The library is made publicly available.
Ontology-driven Knowledge Graph for Android Malware
Sep 03, 2021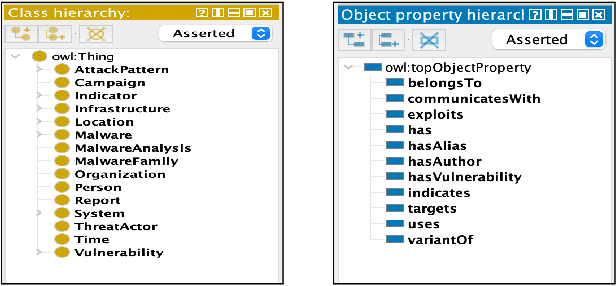
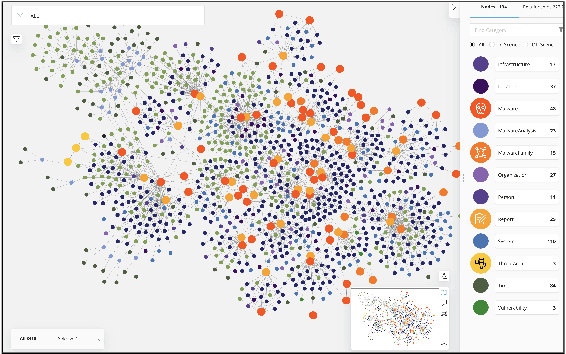
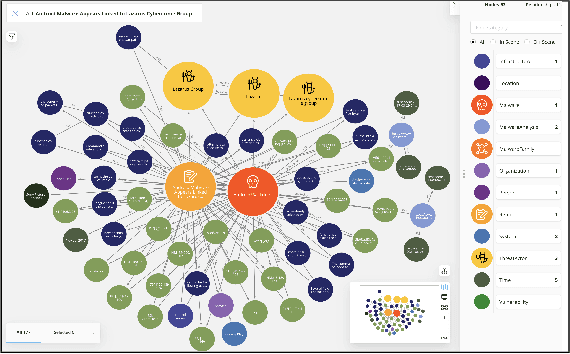
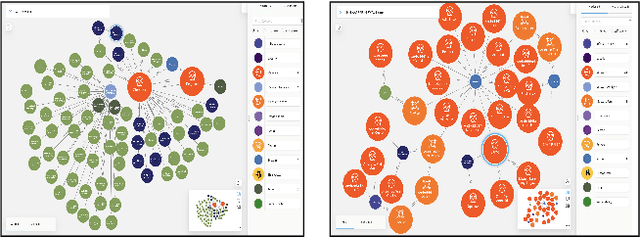
We present MalONT2.0 -- an ontology for malware threat intelligence \cite{rastogi2020malont}. New classes (attack patterns, infrastructural resources to enable attacks, malware analysis to incorporate static analysis, and dynamic analysis of binaries) and relations have been added following a broadened scope of core competency questions. MalONT2.0 allows researchers to extensively capture all requisite classes and relations that gather semantic and syntactic characteristics of an android malware attack. This ontology forms the basis for the malware threat intelligence knowledge graph, MalKG, which we exemplify using three different, non-overlapping demonstrations. Malware features have been extracted from CTI reports on android threat intelligence shared on the Internet and written in the form of unstructured text. Some of these sources are blogs, threat intelligence reports, tweets, and news articles. The smallest unit of information that captures malware features is written as triples comprising head and tail entities, each connected with a relation. In the poster and demonstration, we discuss MalONT2.0, MalKG, as well as the dynamically growing knowledge graph, TINKER.
A new measure for overfitting and its implications for backdooring of deep learning
Jun 18, 2020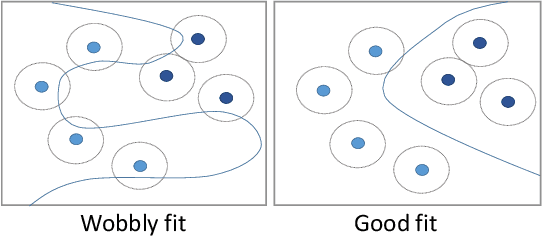
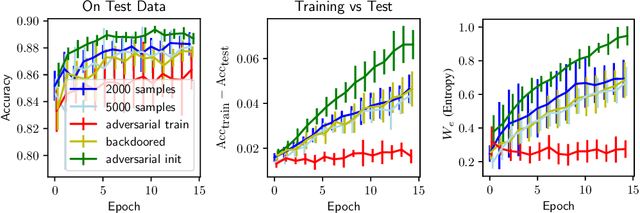
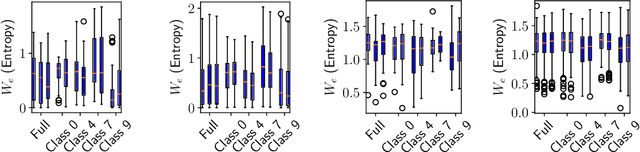
Overfitting describes the phenomenon that a machine learning model fits the given data instead of learning the underlying distribution. Existing approaches are computationally expensive, require large amounts of labeled data, consider overfitting global phenomenon, and often compute a single measurement. Instead, we propose a local measurement around a small number of unlabeled test points to obtain features of overfitting. Our extensive evaluation shows that the measure can reflect the model's different fit of training and test data, identify changes of the fit during training, and even suggest different fit among classes. We further apply our method to verify if backdoors rely on overfitting, a common claim in security of deep learning. Instead, we find that backdoors rely on underfitting. Our findings also provide evidence that even unbackdoored neural networks contain patterns similar to backdoors that are reliably classified as one class.
Learning Domain-Specific Word Embeddings from Sparse Cybersecurity Texts
Sep 21, 2017

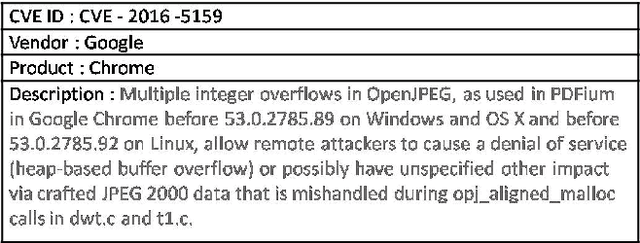
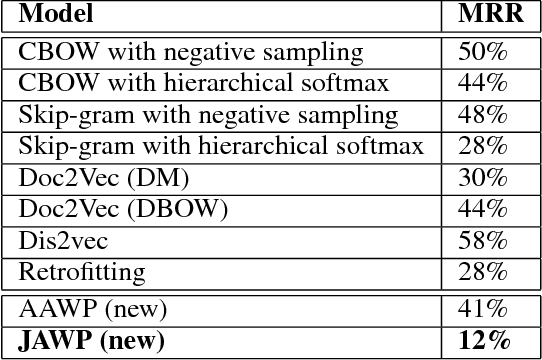
Word embedding is a Natural Language Processing (NLP) technique that automatically maps words from a vocabulary to vectors of real numbers in an embedding space. It has been widely used in recent years to boost the performance of a vari-ety of NLP tasks such as Named Entity Recognition, Syntac-tic Parsing and Sentiment Analysis. Classic word embedding methods such as Word2Vec and GloVe work well when they are given a large text corpus. When the input texts are sparse as in many specialized domains (e.g., cybersecurity), these methods often fail to produce high-quality vectors. In this pa-per, we describe a novel method to train domain-specificword embeddings from sparse texts. In addition to domain texts, our method also leverages diverse types of domain knowledge such as domain vocabulary and semantic relations. Specifi-cally, we first propose a general framework to encode diverse types of domain knowledge as text annotations. Then we de-velop a novel Word Annotation Embedding (WAE) algorithm to incorporate diverse types of text annotations in word em-bedding. We have evaluated our method on two cybersecurity text corpora: a malware description corpus and a Common Vulnerability and Exposure (CVE) corpus. Our evaluation re-sults have demonstrated the effectiveness of our method in learning domain-specific word embeddings.
DinTucker: Scaling up Gaussian process models on multidimensional arrays with billions of elements
Feb 01, 2014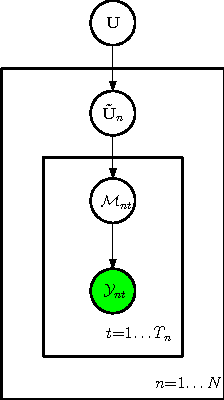
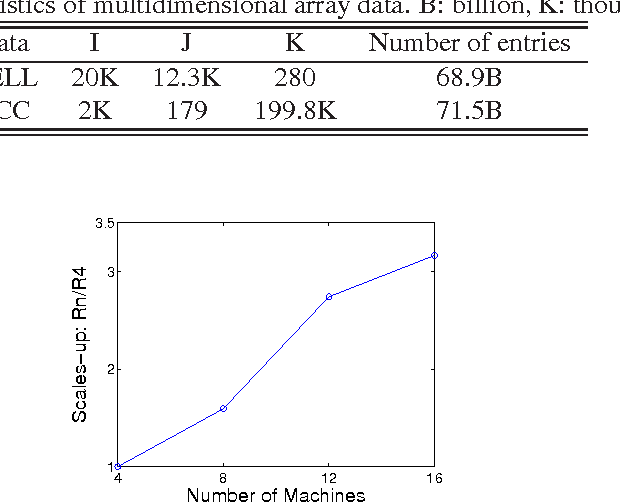
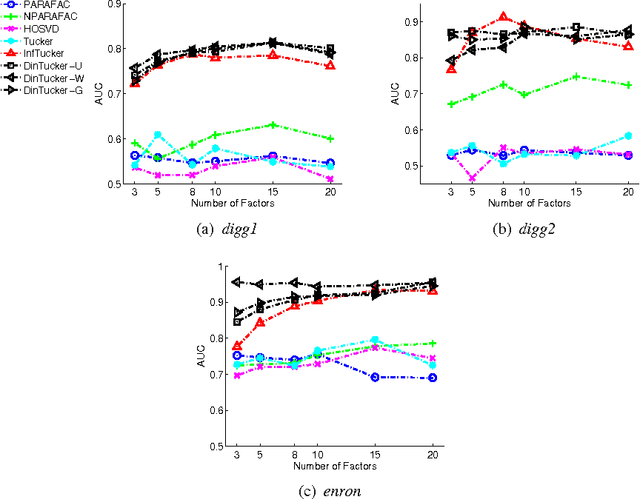

Infinite Tucker Decomposition (InfTucker) and random function prior models, as nonparametric Bayesian models on infinite exchangeable arrays, are more powerful models than widely-used multilinear factorization methods including Tucker and PARAFAC decomposition, (partly) due to their capability of modeling nonlinear relationships between array elements. Despite their great predictive performance and sound theoretical foundations, they cannot handle massive data due to a prohibitively high training time. To overcome this limitation, we present Distributed Infinite Tucker (DINTUCKER), a large-scale nonlinear tensor decomposition algorithm on MAPREDUCE. While maintaining the predictive accuracy of InfTucker, it is scalable on massive data. DINTUCKER is based on a new hierarchical Bayesian model that enables local training of InfTucker on subarrays and information integration from all local training results. We use distributed stochastic gradient descent, coupled with variational inference, to train this model. We apply DINTUCKER to multidimensional arrays with billions of elements from applications in the "Read the Web" project (Carlson et al., 2010) and in information security and compare it with the state-of-the-art large-scale tensor decomposition method, GigaTensor. On both datasets, DINTUCKER achieves significantly higher prediction accuracy with less computational time.