 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLessons from Penetration Tests on Large-Scale Agent Systems
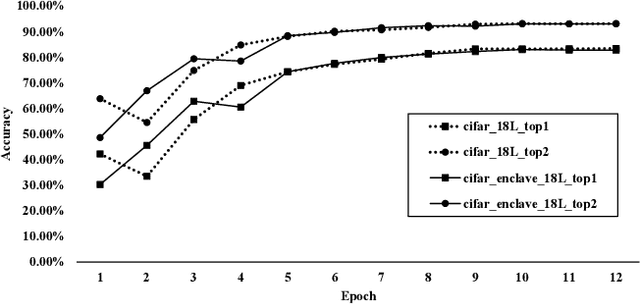
May 26, 2026As AI systems gain increasing autonomy and execution capability, the number of discovered security vulnerabilities continues to rise. However, many of these vulnerabilities are not fundamentally novel, but instead reflect recurring classes of weaknesses long observed in prior computing systems. Execution-capable AI agents are effectively unbounded, self-modifying programs that interact extensively with multiple layers of the computing stack. This broad interaction surface imposes a significant security burden on developers, who must reason about and secure complex cross-layer behaviors. Prior research has primarily focused on vulnerabilities in open-source agents and agent frameworks. In contrast, it remains unclear whether proprietary agent systems -- developed under stricter coding standards and formal review processes -- exhibit similar security weaknesses. In this paper, we present findings from two penetration tests conducted in 2025 against proprietary agent products and evaluate whether the security posture of AI agents has improved since these assessments.
Toward Cybersecurity-Expert Small Language Models
Oct 15, 2025Large language models (LLMs) are transforming everyday applications, yet deployment in cybersecurity lags due to a lack of high-quality, domain-specific models and training datasets. To address this gap, we present CyberPal 2.0, a family of cybersecurity-expert small language models (SLMs) ranging from 4B-20B parameters. To train CyberPal 2.0, we generate an enriched chain-of-thought cybersecurity instruction dataset built with our data enrichment and formatting pipeline, SecKnowledge 2.0, which integrates expert-in-the-loop steering of reasoning formats alongside LLM-driven multi-step grounding, yielding higher-fidelity, task-grounded reasoning traces for security tasks. Across diverse cybersecurity benchmarks, CyberPal 2.0 consistently outperforms its baselines and matches or surpasses various open and closed-source frontier models, while remaining a fraction of their size. On core cyber threat intelligence knowledge tasks, our models outperform almost all tested frontier models, ranking second only to Sec-Gemini v1. On core threat-investigation tasks, such as correlating vulnerabilities and bug tickets with weaknesses, our best 20B-parameter model outperforms GPT-4o, o1, o3-mini, and Sec-Gemini v1, ranking first, while our smallest 4B-parameter model ranks second.
URET: Universal Robustness Evaluation Toolkit (for Evasion)
Aug 03, 2023
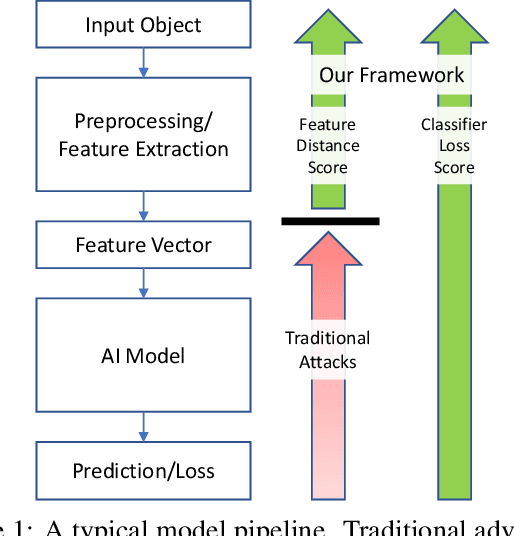

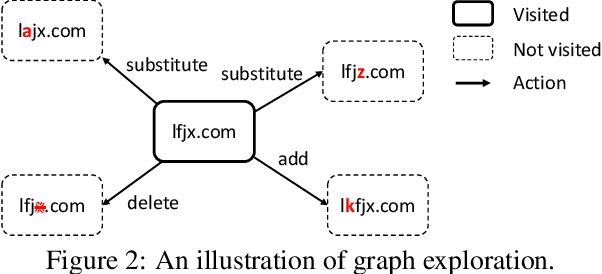
Machine learning models are known to be vulnerable to adversarial evasion attacks as illustrated by image classification models. Thoroughly understanding such attacks is critical in order to ensure the safety and robustness of critical AI tasks. However, most evasion attacks are difficult to deploy against a majority of AI systems because they have focused on image domain with only few constraints. An image is composed of homogeneous, numerical, continuous, and independent features, unlike many other input types to AI systems used in practice. Furthermore, some input types include additional semantic and functional constraints that must be observed to generate realistic adversarial inputs. In this work, we propose a new framework to enable the generation of adversarial inputs irrespective of the input type and task domain. Given an input and a set of pre-defined input transformations, our framework discovers a sequence of transformations that result in a semantically correct and functional adversarial input. We demonstrate the generality of our approach on several diverse machine learning tasks with various input representations. We also show the importance of generating adversarial examples as they enable the deployment of mitigation techniques.
Adaptive Verifiable Training Using Pairwise Class Similarity
Dec 14, 2020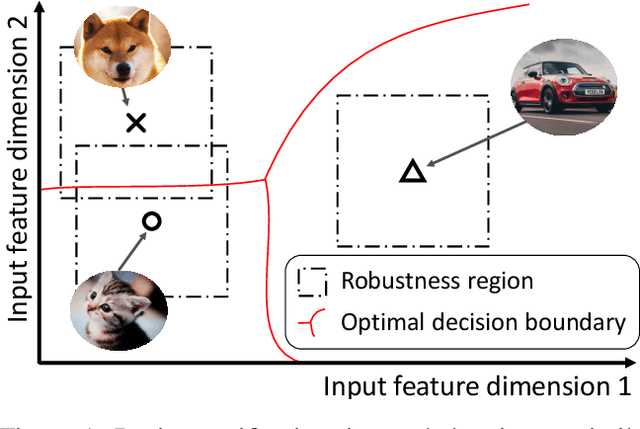
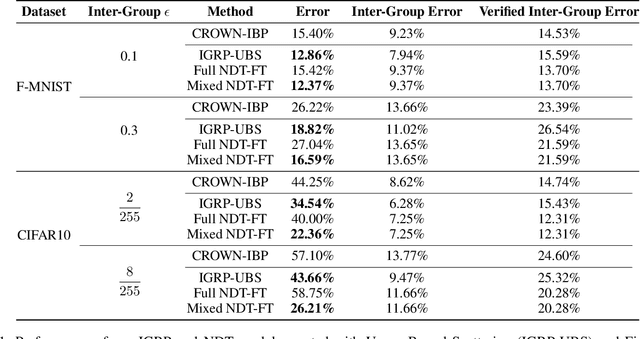
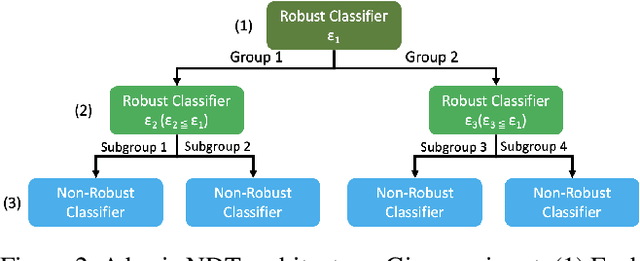
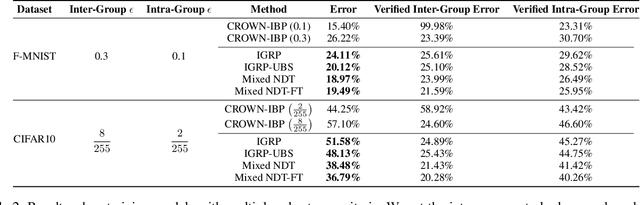
Verifiable training has shown success in creating neural networks that are provably robust to a given amount of noise. However, despite only enforcing a single robustness criterion, its performance scales poorly with dataset complexity. On CIFAR10, a non-robust LeNet model has a 21.63% error rate, while a model created using verifiable training and a L-infinity robustness criterion of 8/255, has an error rate of 57.10%. Upon examination, we find that when labeling visually similar classes, the model's error rate is as high as 61.65%. We attribute the loss in performance to inter-class similarity. Similar classes (i.e., close in the feature space) increase the difficulty of learning a robust model. While it's desirable to train a robust model for a large robustness region, pairwise class similarities limit the potential gains. Also, consideration must be made regarding the relative cost of mistaking similar classes. In security or safety critical tasks, similar classes are likely to belong to the same group, and thus are equally sensitive. In this work, we propose a new approach that utilizes inter-class similarity to improve the performance of verifiable training and create robust models with respect to multiple adversarial criteria. First, we use agglomerate clustering to group similar classes and assign robustness criteria based on the similarity between clusters. Next, we propose two methods to apply our approach: (1) Inter-Group Robustness Prioritization, which uses a custom loss term to create a single model with multiple robustness guarantees and (2) neural decision trees, which trains multiple sub-classifiers with different robustness guarantees and combines them in a decision tree architecture. On Fashion-MNIST and CIFAR10, our approach improves clean performance by 9.63% and 30.89% respectively. On CIFAR100, our approach improves clean performance by 26.32%.
Adversarial Examples and Metrics
Jul 15, 2020
Adversarial examples are a type of attack on machine learning (ML) systems which cause misclassification of inputs. Achieving robustness against adversarial examples is crucial to apply ML in the real world. While most prior work on adversarial examples is empirical, a recent line of work establishes fundamental limitations of robust classification based on cryptographic hardness. Most positive and negative results in this field however assume that there is a fixed target metric which constrains the adversary, and we argue that this is often an unrealistic assumption. In this work we study the limitations of robust classification if the target metric is uncertain. Concretely, we construct a classification problem, which admits robust classification by a small classifier if the target metric is known at the time the model is trained, but for which robust classification is impossible for small classifiers if the target metric is chosen after the fact. In the process, we explore a novel connection between hardness of robust classification and bounded storage model cryptography.
A new measure for overfitting and its implications for backdooring of deep learning
Jun 18, 2020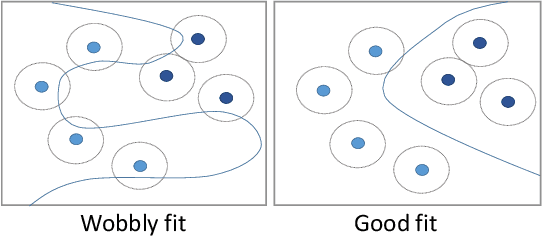
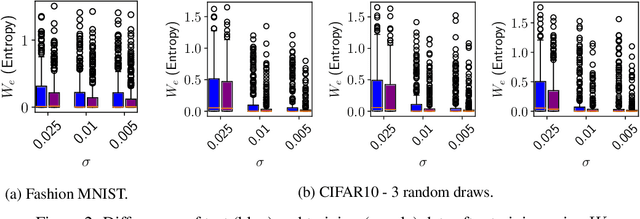
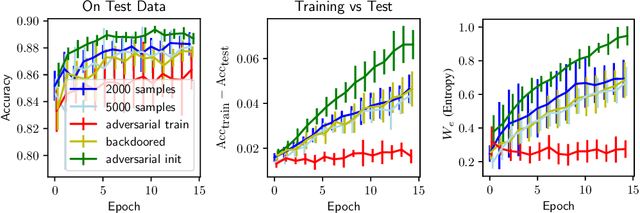
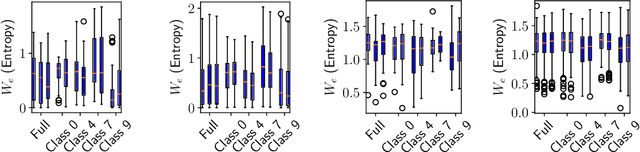
Overfitting describes the phenomenon that a machine learning model fits the given data instead of learning the underlying distribution. Existing approaches are computationally expensive, require large amounts of labeled data, consider overfitting global phenomenon, and often compute a single measurement. Instead, we propose a local measurement around a small number of unlabeled test points to obtain features of overfitting. Our extensive evaluation shows that the measure can reflect the model's different fit of training and test data, identify changes of the fit during training, and even suggest different fit among classes. We further apply our method to verify if backdoors rely on overfitting, a common claim in security of deep learning. Instead, we find that backdoors rely on underfitting. Our findings also provide evidence that even unbackdoored neural networks contain patterns similar to backdoors that are reliably classified as one class.
Reaching Data Confidentiality and Model Accountability on the CalTrain
Dec 07, 2018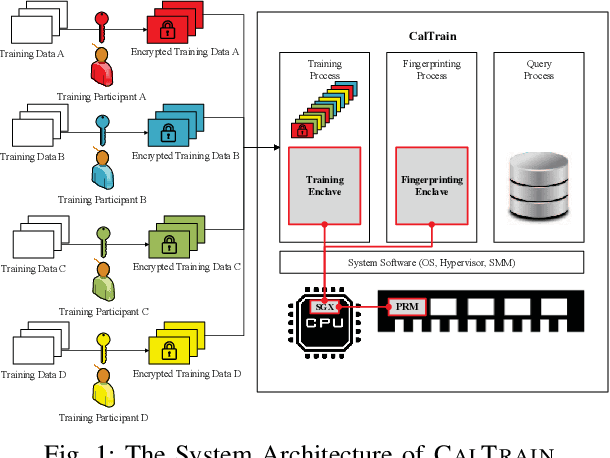
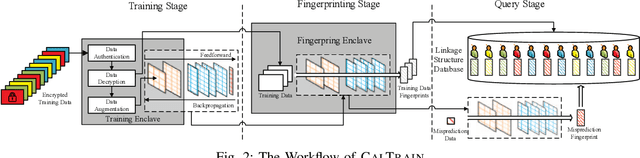

Distributed collaborative learning (DCL) paradigms enable building joint machine learning models from distrusting multi-party participants. Data confidentiality is guaranteed by retaining private training data on each participant's local infrastructure. However, this approach to achieving data confidentiality makes today's DCL designs fundamentally vulnerable to data poisoning and backdoor attacks. It also limits DCL's model accountability, which is key to backtracking the responsible "bad" training data instances/contributors. In this paper, we introduce CALTRAIN, a Trusted Execution Environment (TEE) based centralized multi-party collaborative learning system that simultaneously achieves data confidentiality and model accountability. CALTRAIN enforces isolated computation on centrally aggregated training data to guarantee data confidentiality. To support building accountable learning models, we securely maintain the links between training instances and their corresponding contributors. Our evaluation shows that the models generated from CALTRAIN can achieve the same prediction accuracy when compared to the models trained in non-protected environments. We also demonstrate that when malicious training participants tend to implant backdoors during model training, CALTRAIN can accurately and precisely discover the poisoned and mislabeled training data that lead to the runtime mispredictions.
Detecting Backdoor Attacks on Deep Neural Networks by Activation Clustering
Nov 09, 2018

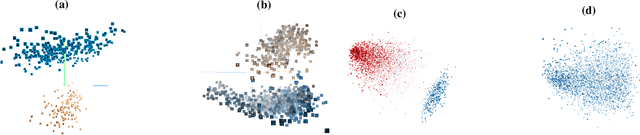

While machine learning (ML) models are being increasingly trusted to make decisions in different and varying areas, the safety of systems using such models has become an increasing concern. In particular, ML models are often trained on data from potentially untrustworthy sources, providing adversaries with the opportunity to manipulate them by inserting carefully crafted samples into the training set. Recent work has shown that this type of attack, called a poisoning attack, allows adversaries to insert backdoors or trojans into the model, enabling malicious behavior with simple external backdoor triggers at inference time and only a blackbox perspective of the model itself. Detecting this type of attack is challenging because the unexpected behavior occurs only when a backdoor trigger, which is known only to the adversary, is present. Model users, either direct users of training data or users of pre-trained model from a catalog, may not guarantee the safe operation of their ML-based system. In this paper, we propose a novel approach to backdoor detection and removal for neural networks. Through extensive experimental results, we demonstrate its effectiveness for neural networks classifying text and images. To the best of our knowledge, this is the first methodology capable of detecting poisonous data crafted to insert backdoors and repairing the model that does not require a verified and trusted dataset.
Defending Against Model Stealing Attacks Using Deceptive Perturbations
Sep 19, 2018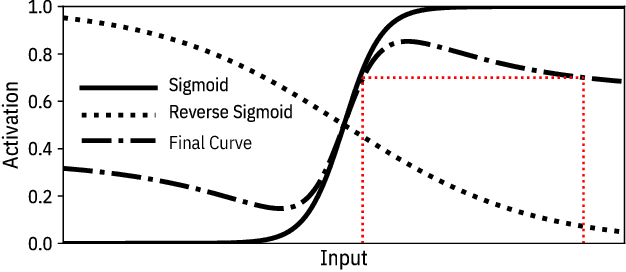
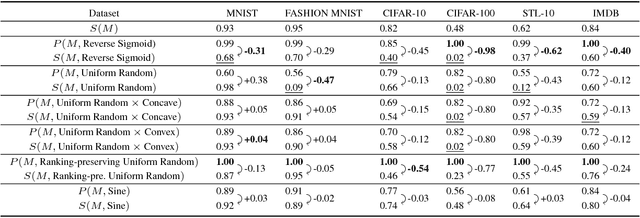
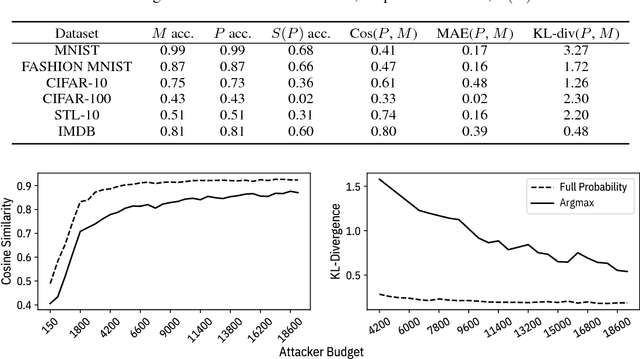
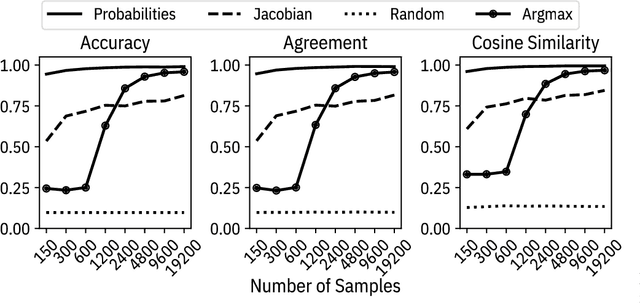
Machine learning models are vulnerable to simple model stealing attacks if the adversary can obtain output labels for chosen inputs. To protect against these attacks, it has been proposed to limit the information provided to the adversary by omitting probability scores, significantly impacting the utility of the provided service. In this work, we illustrate how a service provider can still provide useful, albeit misleading, class probability information, while significantly limiting the success of the attack. Our defense forces the adversary to discard the class probabilities, requiring significantly more queries before they can train a model with comparable performance. We evaluate several attack strategies, model architectures, and hyperparameters under varying adversarial models, and evaluate the efficacy of our defense against the strongest adversary. Finally, we quantify the amount of noise injected into the class probabilities to mesure the loss in utility, e.g., adding 1.26 nats per query on CIFAR-10 and 3.27 on MNIST. Our evaluation shows our defense can degrade the accuracy of the stolen model at least 20%, or require up to 64 times more queries while keeping the accuracy of the protected model almost intact.
DinTucker: Scaling up Gaussian process models on multidimensional arrays with billions of elements
Feb 01, 2014
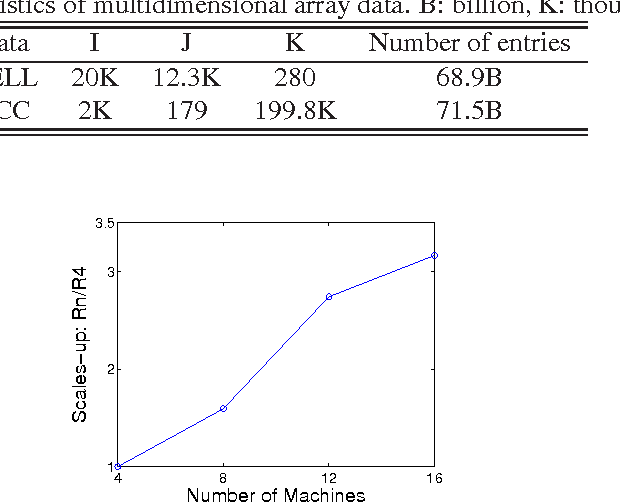
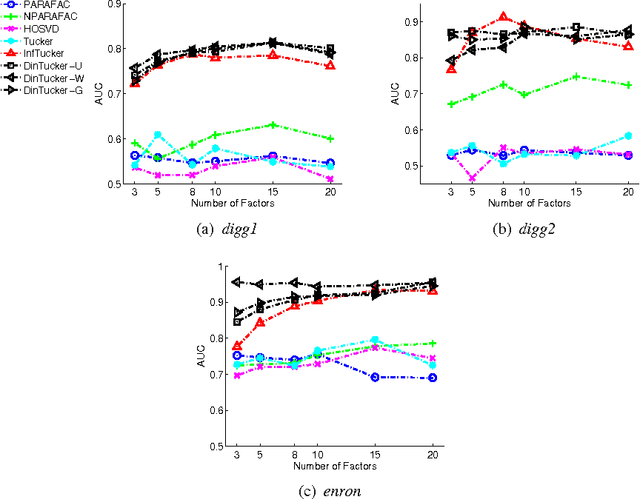

Infinite Tucker Decomposition (InfTucker) and random function prior models, as nonparametric Bayesian models on infinite exchangeable arrays, are more powerful models than widely-used multilinear factorization methods including Tucker and PARAFAC decomposition, (partly) due to their capability of modeling nonlinear relationships between array elements. Despite their great predictive performance and sound theoretical foundations, they cannot handle massive data due to a prohibitively high training time. To overcome this limitation, we present Distributed Infinite Tucker (DINTUCKER), a large-scale nonlinear tensor decomposition algorithm on MAPREDUCE. While maintaining the predictive accuracy of InfTucker, it is scalable on massive data. DINTUCKER is based on a new hierarchical Bayesian model that enables local training of InfTucker on subarrays and information integration from all local training results. We use distributed stochastic gradient descent, coupled with variational inference, to train this model. We apply DINTUCKER to multidimensional arrays with billions of elements from applications in the "Read the Web" project (Carlson et al., 2010) and in information security and compare it with the state-of-the-art large-scale tensor decomposition method, GigaTensor. On both datasets, DINTUCKER achieves significantly higher prediction accuracy with less computational time.