 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Backdoor Attacks on Deep Neural Networks by Activation Clustering
Nov 09, 2018

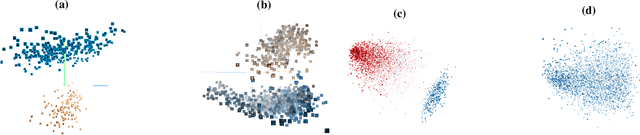

While machine learning (ML) models are being increasingly trusted to make decisions in different and varying areas, the safety of systems using such models has become an increasing concern. In particular, ML models are often trained on data from potentially untrustworthy sources, providing adversaries with the opportunity to manipulate them by inserting carefully crafted samples into the training set. Recent work has shown that this type of attack, called a poisoning attack, allows adversaries to insert backdoors or trojans into the model, enabling malicious behavior with simple external backdoor triggers at inference time and only a blackbox perspective of the model itself. Detecting this type of attack is challenging because the unexpected behavior occurs only when a backdoor trigger, which is known only to the adversary, is present. Model users, either direct users of training data or users of pre-trained model from a catalog, may not guarantee the safe operation of their ML-based system. In this paper, we propose a novel approach to backdoor detection and removal for neural networks. Through extensive experimental results, we demonstrate its effectiveness for neural networks classifying text and images. To the best of our knowledge, this is the first methodology capable of detecting poisonous data crafted to insert backdoors and repairing the model that does not require a verified and trusted dataset.
Defending Against Model Stealing Attacks Using Deceptive Perturbations
Sep 19, 2018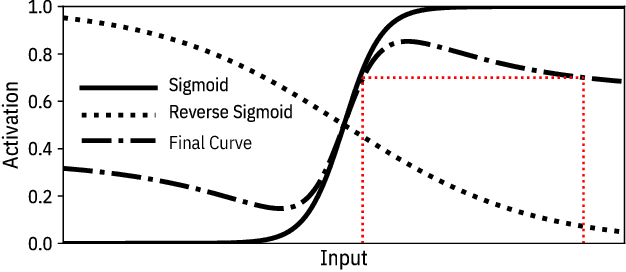
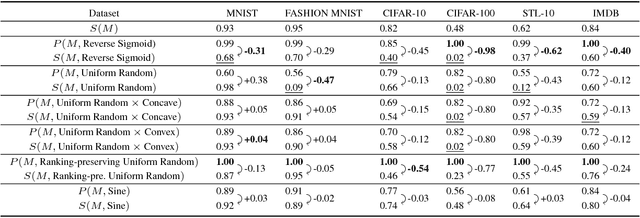
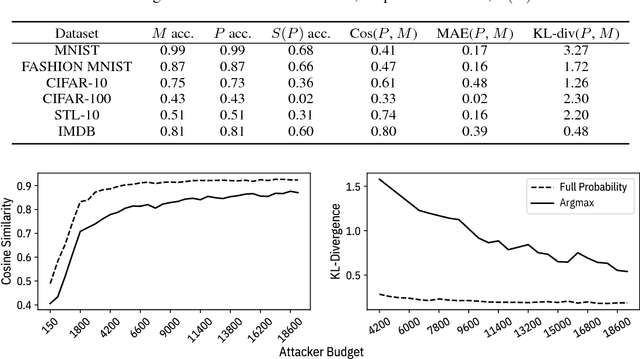
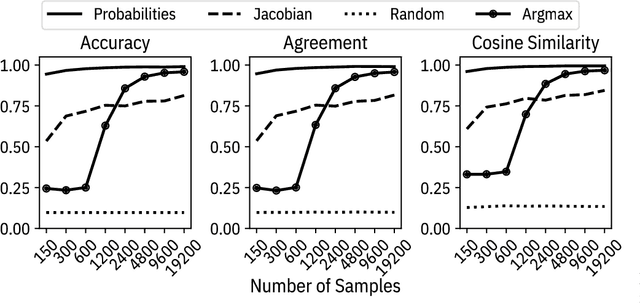
Machine learning models are vulnerable to simple model stealing attacks if the adversary can obtain output labels for chosen inputs. To protect against these attacks, it has been proposed to limit the information provided to the adversary by omitting probability scores, significantly impacting the utility of the provided service. In this work, we illustrate how a service provider can still provide useful, albeit misleading, class probability information, while significantly limiting the success of the attack. Our defense forces the adversary to discard the class probabilities, requiring significantly more queries before they can train a model with comparable performance. We evaluate several attack strategies, model architectures, and hyperparameters under varying adversarial models, and evaluate the efficacy of our defense against the strongest adversary. Finally, we quantify the amount of noise injected into the class probabilities to mesure the loss in utility, e.g., adding 1.26 nats per query on CIFAR-10 and 3.27 on MNIST. Our evaluation shows our defense can degrade the accuracy of the stolen model at least 20%, or require up to 64 times more queries while keeping the accuracy of the protected model almost intact.
Representing data by sparse combination of contextual data points for classification
Aug 18, 2015
In this paper, we study the problem of using contextual da- ta points of a data point for its classification problem. We propose to represent a data point as the sparse linear reconstruction of its context, and learn the sparse context to gather with a linear classifier in a su- pervised way to increase its discriminative ability. We proposed a novel formulation for context learning, by modeling the learning of context reconstruction coefficients and classifier in a unified objective. In this objective, the reconstruction error is minimized and the coefficient spar- sity is encouraged. Moreover, the hinge loss of the classifier is minimized and the complexity of the classifier is reduced. This objective is opti- mized by an alternative strategy in an iterative algorithm. Experiments on three benchmark data set show its advantage over state-of-the-art context-based data representation and classification methods.
Supervised learning of sparse context reconstruction coefficients for data representation and classification
Aug 18, 2015
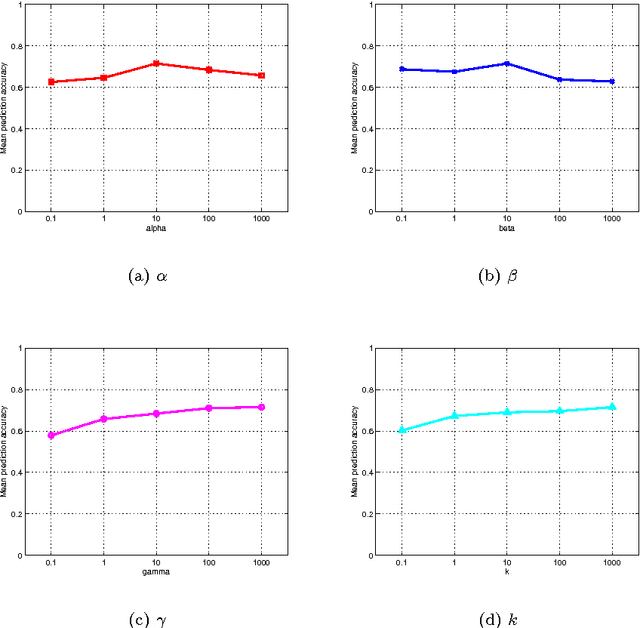
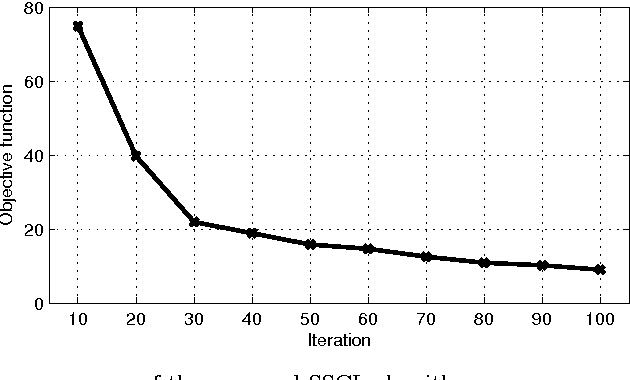
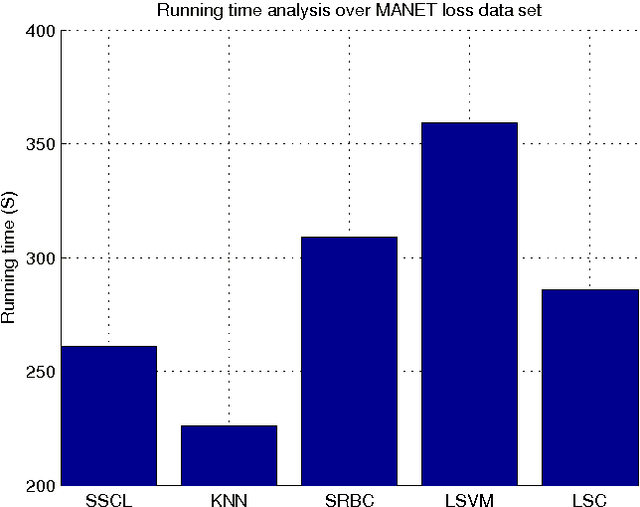
Context of data points, which is usually defined as the other data points in a data set, has been found to play important roles in data representation and classification. In this paper, we study the problem of using context of a data point for its classification problem. Our work is inspired by the observation that actually only very few data points are critical in the context of a data point for its representation and classification. We propose to represent a data point as the sparse linear combination of its context, and learn the sparse context in a supervised way to increase its discriminative ability. To this end, we proposed a novel formulation for context learning, by modeling the learning of context parameter and classifier in a unified objective, and optimizing it with an alternative strategy in an iterative algorithm. Experiments on three benchmark data set show its advantage over state-of-the-art context-based data representation and classification methods.