 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-environment Cooperation Enables Zero-shot Multi-agent Coordination
Apr 20, 2025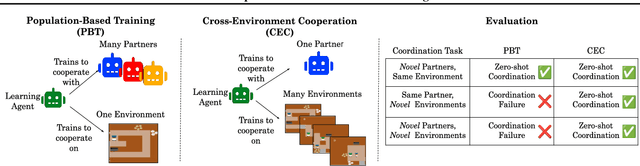

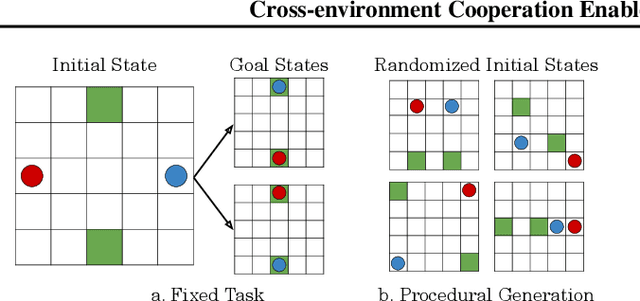
Zero-shot coordination (ZSC), the ability to adapt to a new partner in a cooperative task, is a critical component of human-compatible AI. While prior work has focused on training agents to cooperate on a single task, these specialized models do not generalize to new tasks, even if they are highly similar. Here, we study how reinforcement learning on a distribution of environments with a single partner enables learning general cooperative skills that support ZSC with many new partners on many new problems. We introduce two Jax-based, procedural generators that create billions of solvable coordination challenges. We develop a new paradigm called Cross-Environment Cooperation (CEC), and show that it outperforms competitive baselines quantitatively and qualitatively when collaborating with real people. Our findings suggest that learning to collaborate across many unique scenarios encourages agents to develop general norms, which prove effective for collaboration with different partners. Together, our results suggest a new route toward designing generalist cooperative agents capable of interacting with humans without requiring human data.
Naturalistic Computational Cognitive Science: Towards generalizable models and theories that capture the full range of natural behavior
Feb 27, 2025Artificial Intelligence increasingly pursues large, complex models that perform many tasks within increasingly realistic domains. How, if at all, should these developments in AI influence cognitive science? We argue that progress in AI offers timely opportunities for cognitive science to embrace experiments with increasingly naturalistic stimuli, tasks, and behaviors; and computational models that can accommodate these changes. We first review a growing body of research spanning neuroscience, cognitive science, and AI that suggests that incorporating a broader range of naturalistic experimental paradigms (and models that accommodate them) may be necessary to resolve some aspects of natural intelligence and ensure that our theories generalize. We then suggest that integrating recent progress in AI and cognitive science will enable us to engage with more naturalistic phenomena without giving up experimental control or the pursuit of theoretically grounded understanding. We offer practical guidance on how methodological practices can contribute to cumulative progress in naturalistic computational cognitive science, and illustrate a path towards building computational models that solve the real problems of natural cognition - together with a reductive understanding of the processes and principles by which they do so.
Predictive representations: building blocks of intelligence
Feb 09, 2024Adaptive behavior often requires predicting future events. The theory of reinforcement learning prescribes what kinds of predictive representations are useful and how to compute them. This paper integrates these theoretical ideas with work on cognition and neuroscience. We pay special attention to the successor representation (SR) and its generalizations, which have been widely applied both as engineering tools and models of brain function. This convergence suggests that particular kinds of predictive representations may function as versatile building blocks of intelligence.
Combining Behaviors with the Successor Features Keyboard
Oct 24, 2023The Option Keyboard (OK) was recently proposed as a method for transferring behavioral knowledge across tasks. OK transfers knowledge by adaptively combining subsets of known behaviors using Successor Features (SFs) and Generalized Policy Improvement (GPI). However, it relies on hand-designed state-features and task encodings which are cumbersome to design for every new environment. In this work, we propose the "Successor Features Keyboard" (SFK), which enables transfer with discovered state-features and task encodings. To enable discovery, we propose the "Categorical Successor Feature Approximator" (CSFA), a novel learning algorithm for estimating SFs while jointly discovering state-features and task encodings. With SFK and CSFA, we achieve the first demonstration of transfer with SFs in a challenging 3D environment where all the necessary representations are discovered. We first compare CSFA against other methods for approximating SFs and show that only CSFA discovers representations compatible with SF&GPI at this scale. We then compare SFK against transfer learning baselines and show that it transfers most quickly to long-horizon tasks.
Composing Task Knowledge with Modular Successor Feature Approximators
Jan 28, 2023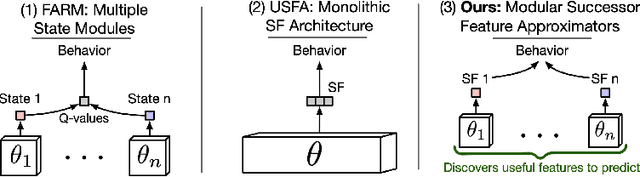

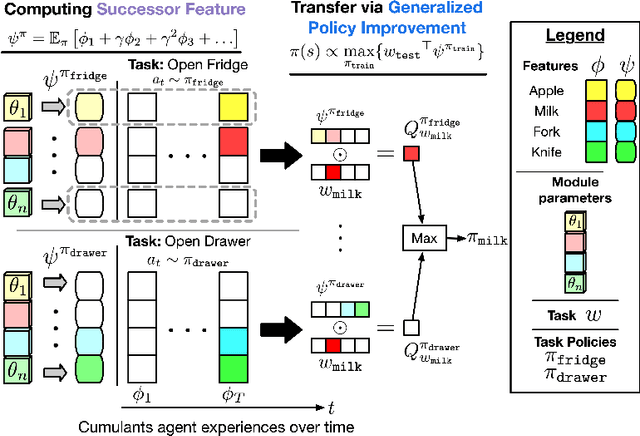

Recently, the Successor Features and Generalized Policy Improvement (SF&GPI) framework has been proposed as a method for learning, composing, and transferring predictive knowledge and behavior. SF&GPI works by having an agent learn predictive representations (SFs) that can be combined for transfer to new tasks with GPI. However, to be effective this approach requires state features that are useful to predict, and these state-features are typically hand-designed. In this work, we present a novel neural network architecture, "Modular Successor Feature Approximators" (MSFA), where modules both discover what is useful to predict, and learn their own predictive representations. We show that MSFA is able to better generalize compared to baseline architectures for learning SFs and modular architectures
Feature-Attending Recurrent Modules for Generalization in Reinforcement Learning
Dec 15, 2021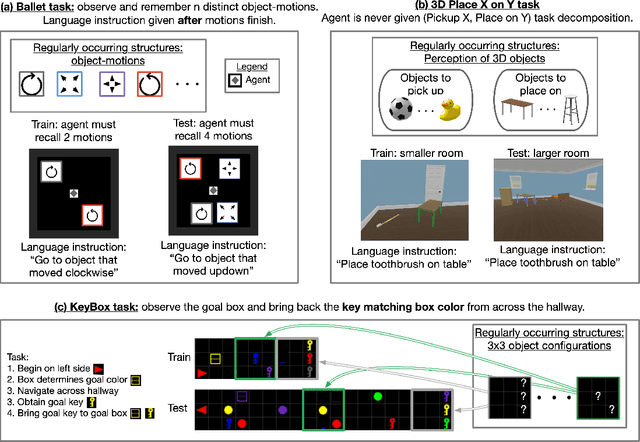
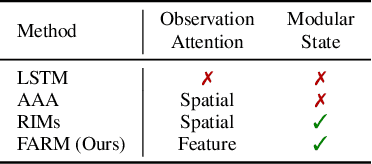
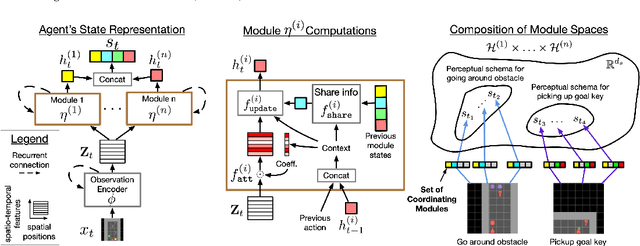
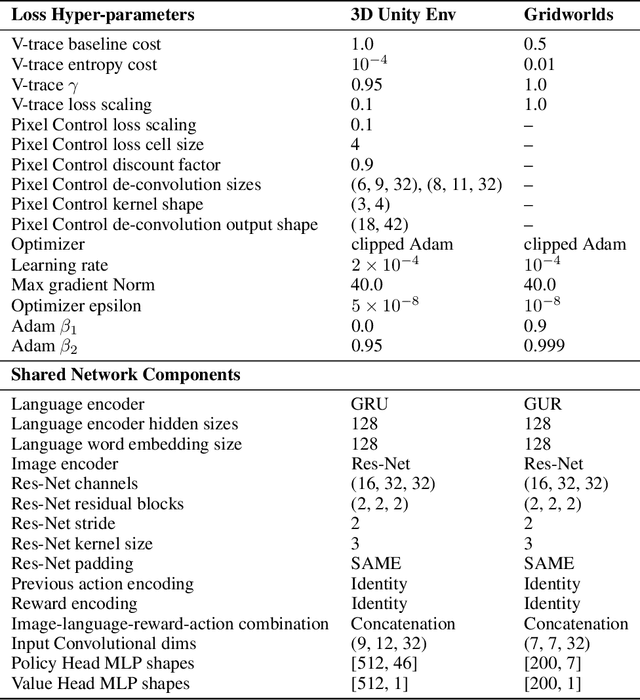
Deep reinforcement learning (Deep RL) has recently seen significant progress in developing algorithms for generalization. However, most algorithms target a single type of generalization setting. In this work, we study generalization across three disparate task structures: (a) tasks composed of spatial and temporal compositions of regularly occurring object motions; (b) tasks composed of active perception of and navigation towards regularly occurring 3D objects; and (c) tasks composed of remembering goal-information over sequences of regularly occurring object-configurations. These diverse task structures all share an underlying idea of compositionality: task completion always involves combining recurring segments of task-oriented perception and behavior. We hypothesize that an agent can generalize within a task structure if it can discover representations that capture these recurring task-segments. For our tasks, this corresponds to representations for recognizing individual object motions, for navigation towards 3D objects, and for navigating through object-configurations. Taking inspiration from cognitive science, we term representations for recurring segments of an agent's experience, "perceptual schemas". We propose Feature Attending Recurrent Modules (FARM), which learns a state representation where perceptual schemas are distributed across multiple, relatively small recurrent modules. We compare FARM to recurrent architectures that leverage spatial attention, which reduces observation features to a weighted average over spatial positions. Our experiments indicate that our feature-attention mechanism better enables FARM to generalize across the diverse object-centric domains we study.
Successor Feature Landmarks for Long-Horizon Goal-Conditioned Reinforcement Learning
Nov 18, 2021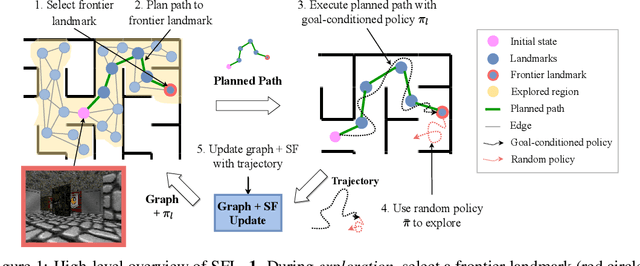
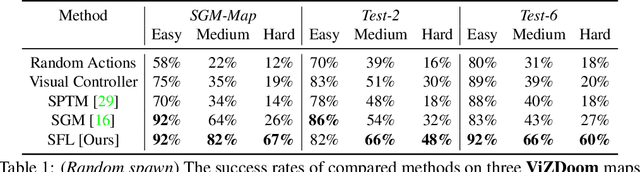
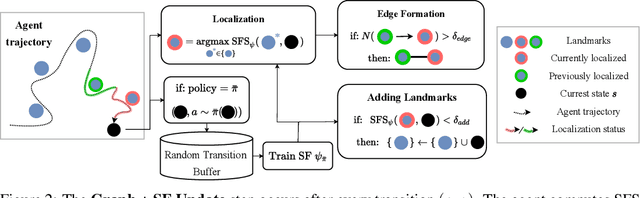
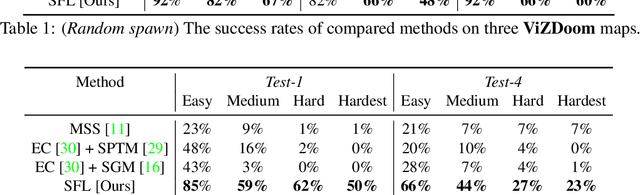
Operating in the real-world often requires agents to learn about a complex environment and apply this understanding to achieve a breadth of goals. This problem, known as goal-conditioned reinforcement learning (GCRL), becomes especially challenging for long-horizon goals. Current methods have tackled this problem by augmenting goal-conditioned policies with graph-based planning algorithms. However, they struggle to scale to large, high-dimensional state spaces and assume access to exploration mechanisms for efficiently collecting training data. In this work, we introduce Successor Feature Landmarks (SFL), a framework for exploring large, high-dimensional environments so as to obtain a policy that is proficient for any goal. SFL leverages the ability of successor features (SF) to capture transition dynamics, using it to drive exploration by estimating state-novelty and to enable high-level planning by abstracting the state-space as a non-parametric landmark-based graph. We further exploit SF to directly compute a goal-conditioned policy for inter-landmark traversal, which we use to execute plans to "frontier" landmarks at the edge of the explored state space. We show in our experiments on MiniGrid and ViZDoom that SFL enables efficient exploration of large, high-dimensional state spaces and outperforms state-of-the-art baselines on long-horizon GCRL tasks.
Reinforcement Learning for Sparse-Reward Object-Interaction Tasks in First-person Simulated 3D Environments
Oct 28, 2020
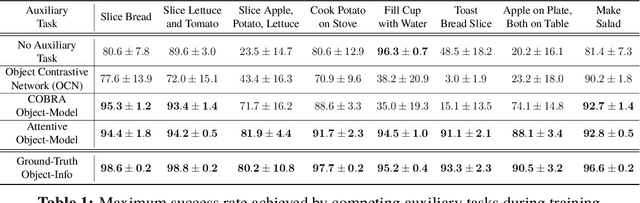
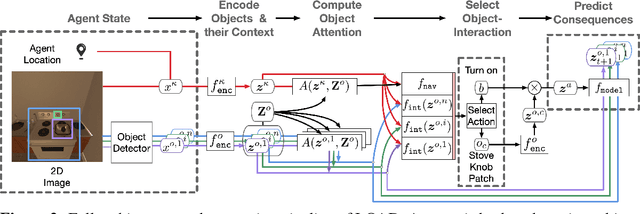
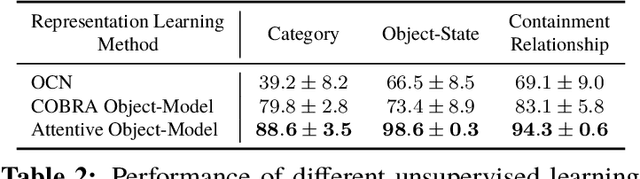
First-person object-interaction tasks in high-fidelity, 3D, simulated environments such as the AI2Thor virtual home-environment pose significant sample-efficiency challenges for reinforcement learning (RL) agents learning from sparse task rewards. To alleviate these challenges, prior work has provided extensive supervision via a combination of reward-shaping, ground-truth object-information, and expert demonstrations. In this work, we show that one can learn object-interaction tasks from scratch without supervision by learning an attentive object-model as an auxiliary task during task learning with an object-centric relational RL agent. Our key insight is that learning an object-model that incorporates object-attention into forward prediction provides a dense learning signal for unsupervised representation learning of both objects and their relationships. This, in turn, enables faster policy learning for an object-centric relational RL agent. We demonstrate our agent by introducing a set of challenging object-interaction tasks in the AI2Thor environment where learning with our attentive object-model is key to strong performance. Specifically, we compare our agent and relational RL agents with alternative auxiliary tasks to a relational RL agent equipped with ground-truth object-information, and show that learning with our object-model best closes the performance gap in terms of both learning speed and maximum success rate. Additionally, we find that incorporating object-attention into an object-model's forward predictions is key to learning representations which capture object-category and object-state.
Detecting Backdoor Attacks on Deep Neural Networks by Activation Clustering
Nov 09, 2018

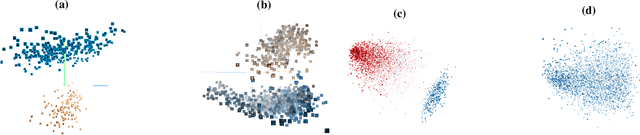

While machine learning (ML) models are being increasingly trusted to make decisions in different and varying areas, the safety of systems using such models has become an increasing concern. In particular, ML models are often trained on data from potentially untrustworthy sources, providing adversaries with the opportunity to manipulate them by inserting carefully crafted samples into the training set. Recent work has shown that this type of attack, called a poisoning attack, allows adversaries to insert backdoors or trojans into the model, enabling malicious behavior with simple external backdoor triggers at inference time and only a blackbox perspective of the model itself. Detecting this type of attack is challenging because the unexpected behavior occurs only when a backdoor trigger, which is known only to the adversary, is present. Model users, either direct users of training data or users of pre-trained model from a catalog, may not guarantee the safe operation of their ML-based system. In this paper, we propose a novel approach to backdoor detection and removal for neural networks. Through extensive experimental results, we demonstrate its effectiveness for neural networks classifying text and images. To the best of our knowledge, this is the first methodology capable of detecting poisonous data crafted to insert backdoors and repairing the model that does not require a verified and trusted dataset.