 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Web Agent Training through Automatic Data Generation and Fine-grained Evaluation
Feb 13, 2026We present a scalable pipeline for automatically generating high-quality training data for web agents. In particular, a major challenge in identifying high-quality training instances is trajectory evaluation - quantifying how much progress was made towards task completion. We introduce a novel constraint-based evaluation framework that provides fine-grained assessment of progress towards task completion. This enables us to leverage partially successful trajectories, which significantly expands the amount of usable training data. We evaluate our method on a new benchmark we propose called BookingArena, which consists of complex booking tasks across 20 popular websites, and demonstrate that our distilled student model outperforms open-source approaches and matches or exceeds commercial systems, while being a significantly smaller model. Our work addresses the challenge of efficiently creating diverse, realistic web interaction datasets and provides a systematic evaluation methodology for complex structured web tasks.
Gaming the Judge: Unfaithful Chain-of-Thought Can Undermine Agent Evaluation
Jan 21, 2026Large language models (LLMs) are increasingly used as judges to evaluate agent performance, particularly in non-verifiable settings where judgments rely on agent trajectories including chain-of-thought (CoT) reasoning. This paradigm implicitly assumes that the agent's CoT faithfully reflects both its internal reasoning and the underlying environment state. We show this assumption is brittle: LLM judges are highly susceptible to manipulation of agent reasoning traces. By systematically rewriting agent CoTs while holding actions and observations fixed, we demonstrate that manipulated reasoning alone can inflate false positive rates of state-of-the-art VLM judges by up to 90% across 800 trajectories spanning diverse web tasks. We study manipulation strategies spanning style-based approaches that alter only the presentation of reasoning and content-based approaches that fabricate signals of task progress, and find that content-based manipulations are consistently more effective. We evaluate prompting-based techniques and scaling judge-time compute, which reduce but do not fully eliminate susceptibility to manipulation. Our findings reveal a fundamental vulnerability in LLM-based evaluation and highlight the need for judging mechanisms that verify reasoning claims against observable evidence.
Scalable Video-to-Dataset Generation for Cross-Platform Mobile Agents
May 19, 2025Recent advancements in Large Language Models (LLMs) and Vision-Language Models (VLMs) have sparked significant interest in developing GUI visual agents. We introduce MONDAY (Mobile OS Navigation Task Dataset for Agents from YouTube), a large-scale dataset of 313K annotated frames from 20K instructional videos capturing diverse real-world mobile OS navigation across multiple platforms. Models that include MONDAY in their pre-training phases demonstrate robust cross-platform generalization capabilities, consistently outperforming models trained on existing single OS datasets while achieving an average performance gain of 18.11%p on an unseen mobile OS platform. To enable continuous dataset expansion as mobile platforms evolve, we present an automated framework that leverages publicly available video content to create comprehensive task datasets without manual annotation. Our framework comprises robust OCR-based scene detection (95.04% F1score), near-perfect UI element detection (99.87% hit ratio), and novel multi-step action identification to extract reliable action sequences across diverse interface configurations. We contribute both the MONDAY dataset and our automated collection framework to facilitate future research in mobile OS navigation.
Do Not Trust Licenses You See -- Dataset Compliance Requires Massive-Scale AI-Powered Lifecycle Tracing
Mar 04, 2025This paper argues that a dataset's legal risk cannot be accurately assessed by its license terms alone; instead, tracking dataset redistribution and its full lifecycle is essential. However, this process is too complex for legal experts to handle manually at scale. Tracking dataset provenance, verifying redistribution rights, and assessing evolving legal risks across multiple stages require a level of precision and efficiency that exceeds human capabilities. Addressing this challenge effectively demands AI agents that can systematically trace dataset redistribution, analyze compliance, and identify legal risks. We develop an automated data compliance system called NEXUS and show that AI can perform these tasks with higher accuracy, efficiency, and cost-effectiveness than human experts. Our massive legal analysis of 17,429 unique entities and 8,072 license terms using this approach reveals the discrepancies in legal rights between the original datasets before redistribution and their redistributed subsets, underscoring the necessity of the data lifecycle-aware compliance. For instance, we find that out of 2,852 datasets with commercially viable individual license terms, only 605 (21%) are legally permissible for commercialization. This work sets a new standard for AI data governance, advocating for a framework that systematically examines the entire lifecycle of dataset redistribution to ensure transparent, legal, and responsible dataset management.
Interactive and Expressive Code-Augmented Planning with Large Language Models
Nov 21, 2024



Large Language Models (LLMs) demonstrate strong abilities in common-sense reasoning and interactive decision-making, but often struggle with complex, long-horizon planning tasks. Recent techniques have sought to structure LLM outputs using control flow and other code-adjacent techniques to improve planning performance. These techniques include using variables (to track important information) and functions (to divide complex tasks into smaller re-usable sub-tasks). However, purely code-based approaches can be error-prone and insufficient for handling ambiguous or unstructured data. To address these challenges, we propose REPL-Plan, an LLM planning approach that is fully code-expressive (it can utilize all the benefits of code) while also being dynamic (it can flexibly adapt from errors and use the LLM for fuzzy situations). In REPL-Plan, an LLM solves tasks by interacting with a Read-Eval-Print Loop (REPL), which iteratively executes and evaluates code, similar to language shells or interactive code notebooks, allowing the model to flexibly correct errors and handle tasks dynamically. We demonstrate that REPL-Plan achieves strong results across various planning domains compared to previous methods.
Auto-Intent: Automated Intent Discovery and Self-Exploration for Large Language Model Web Agents
Oct 29, 2024



In this paper, we introduce Auto-Intent, a method to adapt a pre-trained large language model (LLM) as an agent for a target domain without direct fine-tuning, where we empirically focus on web navigation tasks. Our approach first discovers the underlying intents from target domain demonstrations unsupervisedly, in a highly compact form (up to three words). With the extracted intents, we train our intent predictor to predict the next intent given the agent's past observations and actions. In particular, we propose a self-exploration approach where top-k probable intent predictions are provided as a hint to the pre-trained LLM agent, which leads to enhanced decision-making capabilities. Auto-Intent substantially improves the performance of GPT-{3.5, 4} and Llama-3.1-{70B, 405B} agents on the large-scale real-website navigation benchmarks from Mind2Web and online navigation tasks from WebArena with its cross-benchmark generalization from Mind2Web.
AutoGuide: Automated Generation and Selection of State-Aware Guidelines for Large Language Model Agents
Mar 13, 2024



The primary limitation of large language models (LLMs) is their restricted understanding of the world. This poses significant difficulties for LLM-based agents, particularly in domains where pre-trained LLMs lack sufficient knowledge. In this paper, we introduce a novel framework, called AutoGuide, that bridges the knowledge gap in pre-trained LLMs by leveraging implicit knowledge in offline experiences. Specifically, AutoGuide effectively extracts knowledge embedded in offline data by extracting a set of state-aware guidelines. Importantly, each state-aware guideline is expressed in concise natural language and follows a conditional structure, clearly describing the state where it is applicable. As such, the resulting guidelines enable a principled way to provide helpful knowledge pertinent to an agent's current decision-making process. We show that our approach outperforms competitive LLM-based baselines by a large margin in sequential decision-making benchmarks.
TOD-Flow: Modeling the Structure of Task-Oriented Dialogues
Dec 07, 2023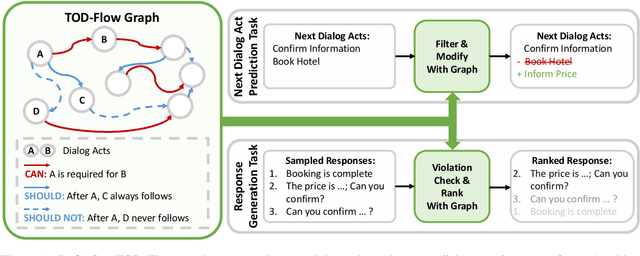
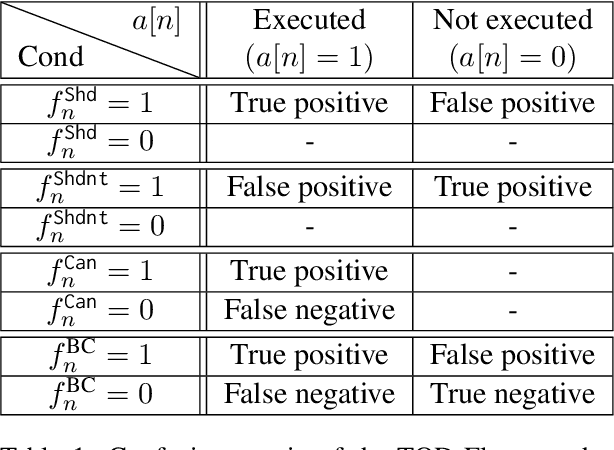
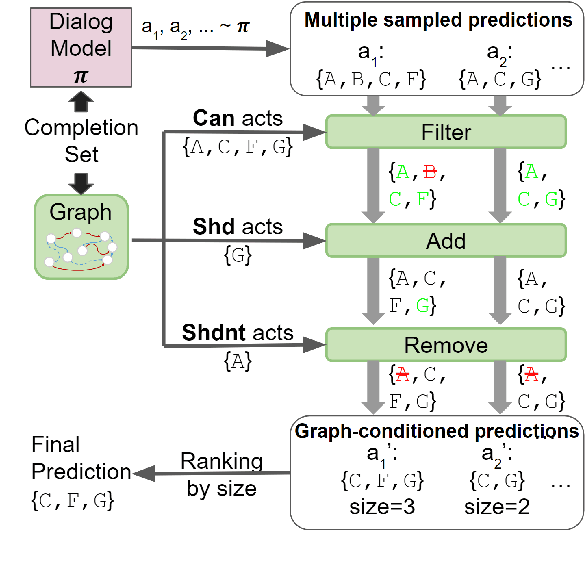

Task-Oriented Dialogue (TOD) systems have become crucial components in interactive artificial intelligence applications. While recent advances have capitalized on pre-trained language models (PLMs), they exhibit limitations regarding transparency and controllability. To address these challenges, we propose a novel approach focusing on inferring the TOD-Flow graph from dialogue data annotated with dialog acts, uncovering the underlying task structure in the form of a graph. The inferred TOD-Flow graph can be easily integrated with any dialogue model to improve its prediction performance, transparency, and controllability. Our TOD-Flow graph learns what a model can, should, and should not predict, effectively reducing the search space and providing a rationale for the model's prediction. We show that the proposed TOD-Flow graph better resembles human-annotated graphs compared to prior approaches. Furthermore, when combined with several dialogue policies and end-to-end dialogue models, we demonstrate that our approach significantly improves dialog act classification and end-to-end response generation performance in the MultiWOZ and SGD benchmarks. Code available at: https://github.com/srsohn/TOD-Flow
Code Models are Zero-shot Precondition Reasoners
Nov 16, 2023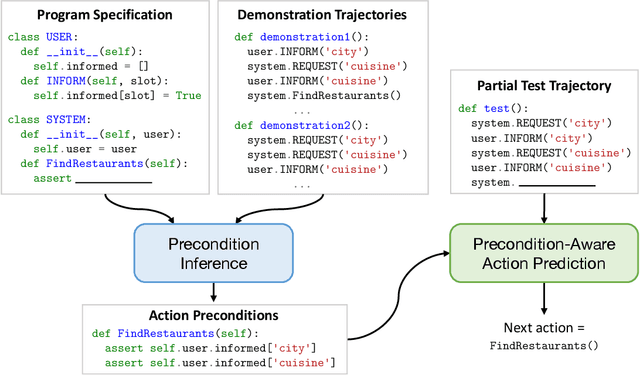

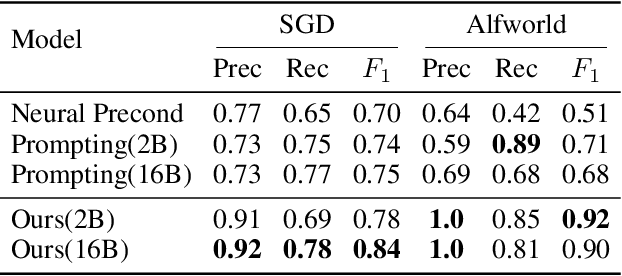
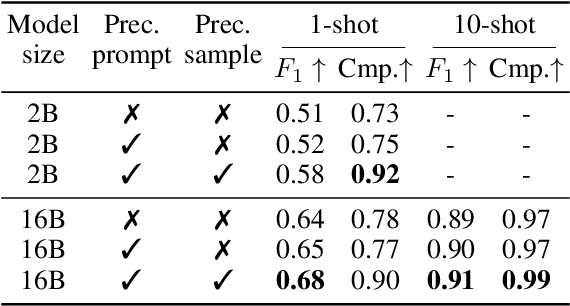
One of the fundamental skills required for an agent acting in an environment to complete tasks is the ability to understand what actions are plausible at any given point. This work explores a novel use of code representations to reason about action preconditions for sequential decision making tasks. Code representations offer the flexibility to model procedural activities and associated constraints as well as the ability to execute and verify constraint satisfaction. Leveraging code representations, we extract action preconditions from demonstration trajectories in a zero-shot manner using pre-trained code models. Given these extracted preconditions, we propose a precondition-aware action sampling strategy that ensures actions predicted by a policy are consistent with preconditions. We demonstrate that the proposed approach enhances the performance of few-shot policy learning approaches across task-oriented dialog and embodied textworld benchmarks.
MultiPrompter: Cooperative Prompt Optimization with Multi-Agent Reinforcement Learning
Oct 25, 2023



Recently, there has been an increasing interest in automated prompt optimization based on reinforcement learning (RL). This approach offers important advantages, such as generating interpretable prompts and being compatible with black-box foundation models. However, the substantial prompt space size poses challenges for RL-based methods, often leading to suboptimal policy convergence. This paper introduces MultiPrompter, a new framework that views prompt optimization as a cooperative game between prompters which take turns composing a prompt together. Our cooperative prompt optimization effectively reduces the problem size and helps prompters learn optimal prompts. We test our method on the text-to-image task and show its ability to generate higher-quality images than baselines.