 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModular Safety Guardrails Are Necessary for Foundation-Model-Enabled Robots in the Real World
Feb 03, 2026The integration of foundation models (FMs) into robotics has accelerated real-world deployment, while introducing new safety challenges arising from open-ended semantic reasoning and embodied physical action. These challenges require safety notions beyond physical constraint satisfaction. In this paper, we characterize FM-enabled robot safety along three dimensions: action safety (physical feasibility and constraint compliance), decision safety (semantic and contextual appropriateness), and human-centered safety (conformance to human intent, norms, and expectations). We argue that existing approaches, including static verification, monolithic controllers, and end-to-end learned policies, are insufficient in settings where tasks, environments, and human expectations are open-ended, long-tailed, and subject to adaptation over time. To address this gap, we propose modular safety guardrails, consisting of monitoring (evaluation) and intervention layers, as an architectural foundation for comprehensive safety across the autonomy stack. Beyond modularity, we highlight possible cross-layer co-design opportunities through representation alignment and conservatism allocation to enable faster, less conservative, and more effective safety enforcement. We call on the community to explore richer guardrail modules and principled co-design strategies to advance safe real-world physical AI deployment.
Learning complete and explainable visual representations from itemized text supervision
Dec 11, 2025Training vision models with language supervision enables general and transferable representations. However, many visual domains, especially non-object-centric domains such as medical imaging and remote sensing, contain itemized text annotations: multiple text items describing distinct and semantically independent findings within a single image. Such supervision differs from standard multi-caption supervision, where captions are redundant or highly overlapping. Here, we introduce ItemizedCLIP, a framework for learning complete and explainable visual representations from itemized text supervision. ItemizedCLIP employs a cross-attention module to produce text item-conditioned visual embeddings and a set of tailored objectives that jointly enforce item independence (distinct regions for distinct items) and representation completeness (coverage of all items). Across four domains with naturally itemized text supervision (brain MRI, head CT, chest CT, remote sensing) and one additional synthetically itemized dataset, ItemizedCLIP achieves substantial improvements in zero-shot performance and fine-grained interpretability over baselines. The resulting ItemizedCLIP representations are semantically grounded, item-differentiable, complete, and visually interpretable. Our code is available at https://github.com/MLNeurosurg/ItemizedCLIP.
Towards Scalable Language-Image Pre-training for 3D Medical Imaging
May 28, 2025Language-image pre-training has demonstrated strong performance in 2D medical imaging, but its success in 3D modalities such as CT and MRI remains limited due to the high computational demands of volumetric data, which pose a significant barrier to training on large-scale, uncurated clinical studies. In this study, we introduce Hierarchical attention for Language-Image Pre-training (HLIP), a scalable pre-training framework for 3D medical imaging. HLIP adopts a lightweight hierarchical attention mechanism inspired by the natural hierarchy of radiology data: slice, scan, and study. This mechanism exhibits strong generalizability, e.g., +4.3% macro AUC on the Rad-ChestCT benchmark when pre-trained on CT-RATE. Moreover, the computational efficiency of HLIP enables direct training on uncurated datasets. Trained on 220K patients with 3.13 million scans for brain MRI and 240K patients with 1.44 million scans for head CT, HLIP achieves state-of-the-art performance, e.g., +32.4% balanced ACC on the proposed publicly available brain MRI benchmark Pub-Brain-5; +1.4% and +6.9% macro AUC on head CT benchmarks RSNA and CQ500, respectively. These results demonstrate that, with HLIP, directly pre-training on uncurated clinical datasets is a scalable and effective direction for language-image pre-training in 3D medical imaging. The code is available at https://github.com/Zch0414/hlip
Integrating Online Learning and Connectivity Maintenance for Communication-Aware Multi-Robot Coordination
Oct 08, 2024



This paper proposes a novel data-driven control strategy for maintaining connectivity in networked multi-robot systems. Existing approaches often rely on a pre-determined communication model specifying whether pairwise robots can communicate given their relative distance to guide the connectivity-aware control design, which may not capture real-world communication conditions. To relax that assumption, we present the concept of Data-driven Connectivity Barrier Certificates, which utilize Control Barrier Functions (CBF) and Gaussian Processes (GP) to characterize the admissible control space for pairwise robots based on communication performance observed online. This allows robots to maintain a satisfying level of pairwise communication quality (measured by the received signal strength) while in motion. Then we propose a Data-driven Connectivity Maintenance (DCM) algorithm that combines (1) online learning of the communication signal strength and (2) a bi-level optimization-based control framework for the robot team to enforce global connectivity of the realistic multi-robot communication graph and minimally deviate from their task-related motions. We provide theoretical proofs to justify the properties of our algorithm and demonstrate its effectiveness through simulations with up to 20 robots.
Courteous MPC for Autonomous Driving with CBF-inspired Risk Assessment
Aug 23, 2024



With more autonomous vehicles (AVs) sharing roadways with human-driven vehicles (HVs), ensuring safe and courteous maneuvers that respect HVs' behavior becomes increasingly important. To promote both safety and courtesy in AV's behavior, an extension of Control Barrier Functions (CBFs)-inspired risk evaluation framework is proposed in this paper by considering both noisy observed positions and velocities of surrounding vehicles. The perceived risk by the ego vehicle can be visualized as a risk map that reflects the understanding of the surrounding environment and thus shows the potential for facilitating safe and courteous driving. By incorporating the risk evaluation framework into the Model Predictive Control (MPC) scheme, we propose a Courteous MPC for ego AV to generate courteous behaviors that 1) reduce the overall risk imposed on other vehicles and 2) respect the hard safety constraints and the original objective for efficiency. We demonstrate the performance of the proposed Courteous MPC via theoretical analysis and simulation experiments.
Decentralized Multi-Robot Line-of-Sight Connectivity Maintenance under Uncertainty
Jun 18, 2024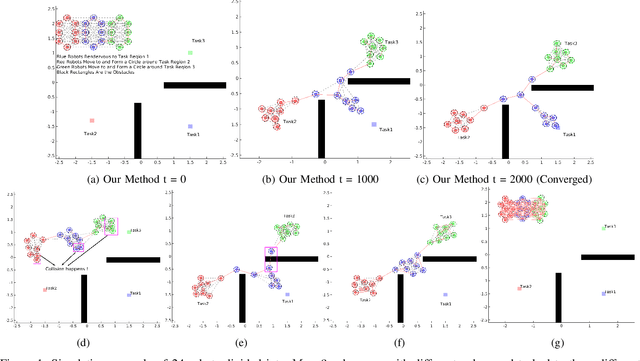



In this paper, we propose a novel decentralized control method to maintain Line-of-Sight connectivity for multi-robot networks in the presence of Guassian-distributed localization uncertainty. In contrast to most existing work that assumes perfect positional information about robots or enforces overly restrictive rigid formation against uncertainty, our method enables robots to preserve Line-of-Sight connectivity with high probability under unbounded Gaussian-like positional noises while remaining minimally intrusive to the original robots' tasks. This is achieved by a motion coordination framework that jointly optimizes the set of existing Line-of-Sight edges to preserve and control revisions to the nominal task-related controllers, subject to the safety constraints and the corresponding composition of uncertainty-aware Line-of-Sight control constraints. Such compositional control constraints, expressed by our novel notion of probabilistic Line-of-Sight connectivity barrier certificates (PrLOS-CBC) for pairwise robots using control barrier functions, explicitly characterize the deterministic admissible control space for the two robots. The resulting motion ensures Line-of-Sight connectedness for the robot team with high probability. Furthermore, we propose a fully decentralized algorithm that decomposes the motion coordination framework by interleaving the composite constraint specification and solving for the resulting optimization-based controllers. The optimality of our approach is justified by the theoretical proofs. Simulation and real-world experiments results are given to demonstrate the effectiveness of our method.
Hierarchical Learned Risk-Aware Planning Framework for Human Driving Modeling
May 10, 2024



This paper presents a novel approach to modeling human driving behavior, designed for use in evaluating autonomous vehicle control systems in a simulation environments. Our methodology leverages a hierarchical forward-looking, risk-aware estimation framework with learned parameters to generate human-like driving trajectories, accommodating multiple driver levels determined by model parameters. This approach is grounded in multimodal trajectory prediction, using a deep neural network with LSTM-based social pooling to predict the trajectories of surrounding vehicles. These trajectories are used to compute forward-looking risk assessments along the ego vehicle's path, guiding its navigation. Our method aims to replicate human driving behaviors by learning parameters that emulate human decision-making during driving. We ensure that our model exhibits robust generalization capabilities by conducting simulations, employing real-world driving data to validate the accuracy of our approach in modeling human behavior. The results reveal that our model effectively captures human behavior, showcasing its versatility in modeling human drivers in diverse highway scenarios.
Super-resolution of biomedical volumes with 2D supervision
Apr 15, 2024



Volumetric biomedical microscopy has the potential to increase the diagnostic information extracted from clinical tissue specimens and improve the diagnostic accuracy of both human pathologists and computational pathology models. Unfortunately, barriers to integrating 3-dimensional (3D) volumetric microscopy into clinical medicine include long imaging times, poor depth / z-axis resolution, and an insufficient amount of high-quality volumetric data. Leveraging the abundance of high-resolution 2D microscopy data, we introduce masked slice diffusion for super-resolution (MSDSR), which exploits the inherent equivalence in the data-generating distribution across all spatial dimensions of biological specimens. This intrinsic characteristic allows for super-resolution models trained on high-resolution images from one plane (e.g., XY) to effectively generalize to others (XZ, YZ), overcoming the traditional dependency on orientation. We focus on the application of MSDSR to stimulated Raman histology (SRH), an optical imaging modality for biological specimen analysis and intraoperative diagnosis, characterized by its rapid acquisition of high-resolution 2D images but slow and costly optical z-sectioning. To evaluate MSDSR's efficacy, we introduce a new performance metric, SliceFID, and demonstrate MSDSR's superior performance over baseline models through extensive evaluations. Our findings reveal that MSDSR not only significantly enhances the quality and resolution of 3D volumetric data, but also addresses major obstacles hindering the broader application of 3D volumetric microscopy in clinical diagnostics and biomedical research.
Step-Calibrated Diffusion for Biomedical Optical Image Restoration
Mar 26, 2024



High-quality, high-resolution medical imaging is essential for clinical care. Raman-based biomedical optical imaging uses non-ionizing infrared radiation to evaluate human tissues in real time and is used for early cancer detection, brain tumor diagnosis, and intraoperative tissue analysis. Unfortunately, optical imaging is vulnerable to image degradation due to laser scattering and absorption, which can result in diagnostic errors and misguided treatment. Restoration of optical images is a challenging computer vision task because the sources of image degradation are multi-factorial, stochastic, and tissue-dependent, preventing a straightforward method to obtain paired low-quality/high-quality data. Here, we present Restorative Step-Calibrated Diffusion (RSCD), an unpaired image restoration method that views the image restoration problem as completing the finishing steps of a diffusion-based image generation task. RSCD uses a step calibrator model to dynamically determine the severity of image degradation and the number of steps required to complete the reverse diffusion process for image restoration. RSCD outperforms other widely used unpaired image restoration methods on both image quality and perceptual evaluation metrics for restoring optical images. Medical imaging experts consistently prefer images restored using RSCD in blinded comparison experiments and report minimal to no hallucinations. Finally, we show that RSCD improves performance on downstream clinical imaging tasks, including automated brain tumor diagnosis and deep tissue imaging. Our code is available at https://github.com/MLNeurosurg/restorative_step-calibrated_diffusion.
A self-supervised framework for learning whole slide representations
Feb 09, 2024
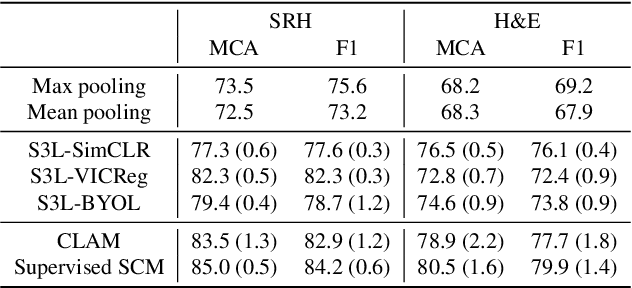
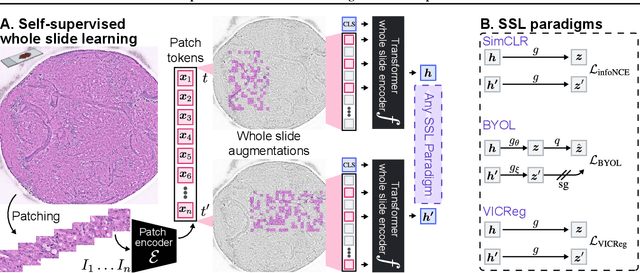
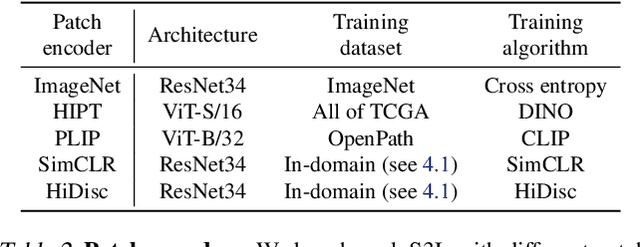
Whole slide imaging is fundamental to biomedical microscopy and computational pathology. However, whole slide images (WSIs) present a complex computer vision challenge due to their gigapixel size, diverse histopathologic features, spatial heterogeneity, and limited/absent data annotations. These challenges highlight that supervised training alone can result in suboptimal whole slide representations. Self-supervised representation learning can achieve high-quality WSI visual feature learning for downstream diagnostic tasks, such as cancer diagnosis or molecular genetic prediction. Here, we present a general self-supervised whole slide learning (S3L) framework for gigapixel-scale self-supervision of WSIs. S3L combines data transformation strategies from transformer-based vision and language modeling into a single unified framework to generate paired views for self-supervision. S3L leverages the inherent regional heterogeneity, histologic feature variability, and information redundancy within WSIs to learn high-quality whole-slide representations. We benchmark S3L visual representations on two diagnostic tasks for two biomedical microscopy modalities. S3L significantly outperforms WSI baselines for cancer diagnosis and genetic mutation prediction. Additionally, S3L achieves good performance using both in-domain and out-of-distribution patch encoders, demonstrating good flexibility and generalizability.