 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaming the Judge: Unfaithful Chain-of-Thought Can Undermine Agent Evaluation
Jan 21, 2026Large language models (LLMs) are increasingly used as judges to evaluate agent performance, particularly in non-verifiable settings where judgments rely on agent trajectories including chain-of-thought (CoT) reasoning. This paradigm implicitly assumes that the agent's CoT faithfully reflects both its internal reasoning and the underlying environment state. We show this assumption is brittle: LLM judges are highly susceptible to manipulation of agent reasoning traces. By systematically rewriting agent CoTs while holding actions and observations fixed, we demonstrate that manipulated reasoning alone can inflate false positive rates of state-of-the-art VLM judges by up to 90% across 800 trajectories spanning diverse web tasks. We study manipulation strategies spanning style-based approaches that alter only the presentation of reasoning and content-based approaches that fabricate signals of task progress, and find that content-based manipulations are consistently more effective. We evaluate prompting-based techniques and scaling judge-time compute, which reduce but do not fully eliminate susceptibility to manipulation. Our findings reveal a fundamental vulnerability in LLM-based evaluation and highlight the need for judging mechanisms that verify reasoning claims against observable evidence.
Lost in the Noise: How Reasoning Models Fail with Contextual Distractors
Jan 12, 2026Recent advances in reasoning models and agentic AI systems have led to an increased reliance on diverse external information. However, this shift introduces input contexts that are inherently noisy, a reality that current sanitized benchmarks fail to capture. We introduce NoisyBench, a comprehensive benchmark that systematically evaluates model robustness across 11 datasets in RAG, reasoning, alignment, and tool-use tasks against diverse noise types, including random documents, irrelevant chat histories, and hard negative distractors. Our evaluation reveals a catastrophic performance drop of up to 80% in state-of-the-art models when faced with contextual distractors. Crucially, we find that agentic workflows often amplify these errors by over-trusting noisy tool outputs, and distractors can trigger emergent misalignment even without adversarial intent. We find that prompting, context engineering, SFT, and outcome-reward only RL fail to ensure robustness; in contrast, our proposed Rationale-Aware Reward (RARE) significantly strengthens resilience by incentivizing the identification of helpful information within noise. Finally, we uncover an inverse scaling trend where increased test-time computation leads to worse performance in noisy settings and demonstrate via attention visualization that models disproportionately focus on distractor tokens, providing vital insights for building the next generation of robust, reasoning-capable agents.
Adaptive Retrieval for Reasoning-Intensive Retrieval
Jan 08, 2026We study leveraging adaptive retrieval to ensure sufficient "bridge" documents are retrieved for reasoning-intensive retrieval. Bridge documents are those that contribute to the reasoning process yet are not directly relevant to the initial query. While existing reasoning-based reranker pipelines attempt to surface these documents in ranking, they suffer from bounded recall. Naive solution with adaptive retrieval into these pipelines often leads to planning error propagation. To address this, we propose REPAIR, a framework that bridges this gap by repurposing reasoning plans as dense feedback signals for adaptive retrieval. Our key distinction is enabling mid-course correction during reranking through selective adaptive retrieval, retrieving documents that support the pivotal plan. Experimental results on reasoning-intensive retrieval and complex QA tasks demonstrate that our method outperforms existing baselines by 5.6%pt.
DEER: A Comprehensive and Reliable Benchmark for Deep-Research Expert Reports
Dec 19, 2025As large language models (LLMs) advance, deep research systems can generate expert-level reports via multi-step reasoning and evidence-based synthesis, but evaluating such reports remains challenging. Existing benchmarks often lack systematic criteria for expert reporting, evaluations that rely heavily on LLM judges can fail to capture issues that require expert judgment, and source verification typically covers only a limited subset of explicitly cited statements rather than report-wide factual reliability. We introduce DEER, a benchmark for evaluating expert-level deep research reports. DEER comprises 50 report-writing tasks spanning 13 domains and an expert-grounded evaluation taxonomy (7 dimensions, 25 sub-dimension) operationalized into 130 fine-grained rubric items. DEER further provides task-specific expert guidance to help LLM judges assess expert-level report quality more consistently. Complementing rubric-based assessment, we propose a document-level fact-checking architecture that extracts and verifies all claims across the entire report, including both cited and uncited ones, and quantifies external-evidence quality. DEER correlates closely with human expert judgments and yields interpretable diagnostics of system strengths and weaknesses.
Training-free Detection of AI-generated images via Cropping Robustness
Nov 18, 2025AI-generated image detection has become crucial with the rapid advancement of vision-generative models. Instead of training detectors tailored to specific datasets, we study a training-free approach leveraging self-supervised models without requiring prior data knowledge. These models, pre-trained with augmentations like RandomResizedCrop, learn to produce consistent representations across varying resolutions. Motivated by this, we propose WaRPAD, a training-free AI-generated image detection algorithm based on self-supervised models. Since neighborhood pixel differences in images are highly sensitive to resizing operations, WaRPAD first defines a base score function that quantifies the sensitivity of image embeddings to perturbations along high-frequency directions extracted via Haar wavelet decomposition. To simulate robustness against cropping augmentation, we rescale each image to a multiple of the models input size, divide it into smaller patches, and compute the base score for each patch. The final detection score is then obtained by averaging the scores across all patches. We validate WaRPAD on real datasets of diverse resolutions and domains, and images generated by 23 different generative models. Our method consistently achieves competitive performance and demonstrates strong robustness to test-time corruptions. Furthermore, as invariance to RandomResizedCrop is a common training scheme across self-supervised models, we show that WaRPAD is applicable across self-supervised models.
Hybrid Deep Searcher: Integrating Parallel and Sequential Search Reasoning
Aug 26, 2025Large reasoning models (LRMs) have demonstrated strong performance in complex, multi-step reasoning tasks. Existing methods enhance LRMs by sequentially integrating external knowledge retrieval; models iteratively generate queries, retrieve external information, and progressively reason over this information. However, purely sequential querying increases inference latency and context length, diminishing coherence and potentially reducing accuracy. To address these limitations, we introduce HDS-QA (Hybrid Deep Search QA), a synthetic dataset automatically generated from Natural Questions, explicitly designed to train LRMs to distinguish parallelizable from sequential queries. HDS-QA comprises hybrid-hop questions that combine parallelizable independent subqueries (executable simultaneously) and sequentially dependent subqueries (requiring step-by-step resolution), along with synthetic reasoning-querying-retrieval paths involving parallel queries. We fine-tune an LRM using HDS-QA, naming the model HybridDeepSearcher, which outperforms state-of-the-art baselines across multiple benchmarks, notably achieving +15.9 and +11.5 F1 on FanOutQA and a subset of BrowseComp, respectively, both requiring comprehensive and exhaustive search. Experimental results highlight two key advantages: HybridDeepSearcher reaches comparable accuracy with fewer search turns, significantly reducing inference latency, and it effectively scales as more turns are permitted. These results demonstrate the efficiency, scalability, and effectiveness of explicitly training LRMs to leverage hybrid parallel and sequential querying.
Revisiting LLM Value Probing Strategies: Are They Robust and Expressive?
Jul 17, 2025There has been extensive research on assessing the value orientation of Large Language Models (LLMs) as it can shape user experiences across demographic groups. However, several challenges remain. First, while the Multiple Choice Question (MCQ) setting has been shown to be vulnerable to perturbations, there is no systematic comparison of probing methods for value probing. Second, it is unclear to what extent the probed values capture in-context information and reflect models' preferences for real-world actions. In this paper, we evaluate the robustness and expressiveness of value representations across three widely used probing strategies. We use variations in prompts and options, showing that all methods exhibit large variances under input perturbations. We also introduce two tasks studying whether the values are responsive to demographic context, and how well they align with the models' behaviors in value-related scenarios. We show that the demographic context has little effect on the free-text generation, and the models' values only weakly correlate with their preference for value-based actions. Our work highlights the need for a more careful examination of LLM value probing and awareness of its limitations.
Shifting from Ranking to Set Selection for Retrieval Augmented Generation
Jul 09, 2025Retrieval in Retrieval-Augmented Generation(RAG) must ensure that retrieved passages are not only individually relevant but also collectively form a comprehensive set. Existing approaches primarily rerank top-k passages based on their individual relevance, often failing to meet the information needs of complex queries in multi-hop question answering. In this work, we propose a set-wise passage selection approach and introduce SETR, which explicitly identifies the information requirements of a query through Chain-of-Thought reasoning and selects an optimal set of passages that collectively satisfy those requirements. Experiments on multi-hop RAG benchmarks show that SETR outperforms both proprietary LLM-based rerankers and open-source baselines in terms of answer correctness and retrieval quality, providing an effective and efficient alternative to traditional rerankers in RAG systems. The code is available at https://github.com/LGAI-Research/SetR
SafeDPO: A Simple Approach to Direct Preference Optimization with Enhanced Safety
May 26, 2025As Large Language Models (LLMs) continue to advance and find applications across a growing number of fields, ensuring the safety of LLMs has become increasingly critical. To address safety concerns, recent studies have proposed integrating safety constraints into Reinforcement Learning from Human Feedback (RLHF). However, these approaches tend to be complex, as they encompass complicated procedures in RLHF along with additional steps required by the safety constraints. Inspired by Direct Preference Optimization (DPO), we introduce a new algorithm called SafeDPO, which is designed to directly optimize the safety alignment objective in a single stage of policy learning, without requiring relaxation. SafeDPO introduces only one additional hyperparameter to further enhance safety and requires only minor modifications to standard DPO. As a result, it eliminates the need to fit separate reward and cost models or to sample from the language model during fine-tuning, while still enhancing the safety of LLMs. Finally, we demonstrate that SafeDPO achieves competitive performance compared to state-of-the-art safety alignment algorithms, both in terms of aligning with human preferences and improving safety.
The CoT Encyclopedia: Analyzing, Predicting, and Controlling how a Reasoning Model will Think
May 15, 2025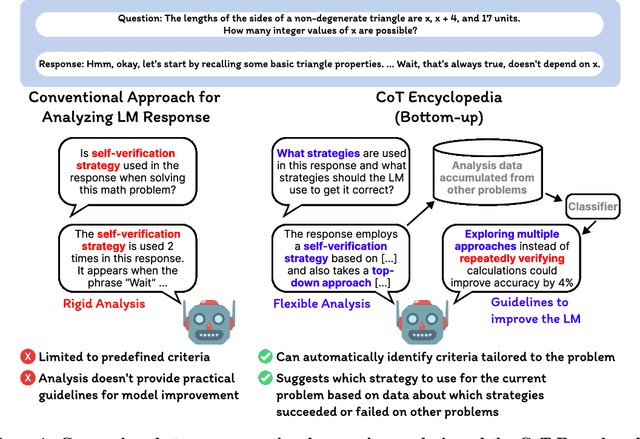
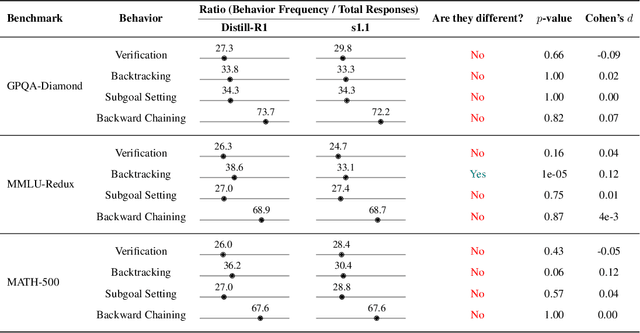
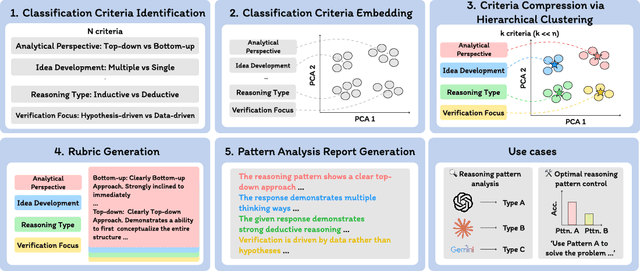
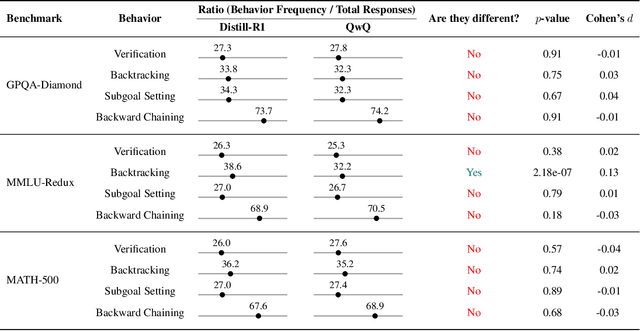
Long chain-of-thought (CoT) is an essential ingredient in effective usage of modern large language models, but our understanding of the reasoning strategies underlying these capabilities remains limited. While some prior works have attempted to categorize CoTs using predefined strategy types, such approaches are constrained by human intuition and fail to capture the full diversity of model behaviors. In this work, we introduce the CoT Encyclopedia, a bottom-up framework for analyzing and steering model reasoning. Our method automatically extracts diverse reasoning criteria from model-generated CoTs, embeds them into a semantic space, clusters them into representative categories, and derives contrastive rubrics to interpret reasoning behavior. Human evaluations show that this framework produces more interpretable and comprehensive analyses than existing methods. Moreover, we demonstrate that this understanding enables performance gains: we can predict which strategy a model is likely to use and guide it toward more effective alternatives. Finally, we provide practical insights, such as that training data format (e.g., free-form vs. multiple-choice) has a far greater impact on reasoning behavior than data domain, underscoring the importance of format-aware model design.