 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Explore and Select for Coverage-Conditioned Retrieval-Augmented Generation
Jul 01, 2024



Interactions with billion-scale large language models typically yield long-form responses due to their extensive parametric capacities, along with retrieval-augmented features. While detailed responses provide insightful viewpoint of a specific subject, they frequently generate redundant and less engaging content that does not meet user interests. In this work, we focus on the role of query outlining (i.e., selected sequence of queries) in scenarios that users request a specific range of information, namely coverage-conditioned ($C^2$) scenarios. For simulating $C^2$ scenarios, we construct QTree, 10K sets of information-seeking queries decomposed with various perspectives on certain topics. By utilizing QTree, we train QPlanner, a 7B language model generating customized query outlines that follow coverage-conditioned queries. We analyze the effectiveness of generated outlines through automatic and human evaluation, targeting on retrieval-augmented generation (RAG). Moreover, the experimental results demonstrate that QPlanner with alignment training can further provide outlines satisfying diverse user interests. Our resources are available at https://github.com/youngerous/qtree.
Ask Optimal Questions: Aligning Large Language Models with Retriever's Preference in Conversational Search
Feb 19, 2024



Conversational search, unlike single-turn retrieval tasks, requires understanding the current question within a dialogue context. The common approach of rewrite-then-retrieve aims to decontextualize questions to be self-sufficient for off-the-shelf retrievers, but most existing methods produce sub-optimal query rewrites due to the limited ability to incorporate signals from the retrieval results. To overcome this limitation, we present a novel framework RetPO (Retriever's Preference Optimization), which is designed to optimize a language model (LM) for reformulating search queries in line with the preferences of the target retrieval systems. The process begins by prompting a large LM to produce various potential rewrites and then collects retrieval performance for these rewrites as the retrievers' preferences. Through the process, we construct a large-scale dataset called RF collection, containing Retrievers' Feedback on over 410K query rewrites across 12K conversations. Furthermore, we fine-tune a smaller LM using this dataset to align it with the retrievers' preferences as feedback. The resulting model achieves state-of-the-art performance on two recent conversational search benchmarks, significantly outperforming existing baselines, including GPT-3.5.
Tree of Clarifications: Answering Ambiguous Questions with Retrieval-Augmented Large Language Models
Oct 23, 2023Questions in open-domain question answering are often ambiguous, allowing multiple interpretations. One approach to handling them is to identify all possible interpretations of the ambiguous question (AQ) and to generate a long-form answer addressing them all, as suggested by Stelmakh et al., (2022). While it provides a comprehensive response without bothering the user for clarification, considering multiple dimensions of ambiguity and gathering corresponding knowledge remains a challenge. To cope with the challenge, we propose a novel framework, Tree of Clarifications (ToC): It recursively constructs a tree of disambiguations for the AQ -- via few-shot prompting leveraging external knowledge -- and uses it to generate a long-form answer. ToC outperforms existing baselines on ASQA in a few-shot setup across the metrics, while surpassing fully-supervised baselines trained on the whole training set in terms of Disambig-F1 and Disambig-ROUGE. Code is available at https://github.com/gankim/tree-of-clarifications.
KU-DMIS-MSRA at RadSum23: Pre-trained Vision-Language Model for Radiology Report Summarization
Jul 10, 2023In this paper, we introduce CheXOFA, a new pre-trained vision-language model (VLM) for the chest X-ray domain. Our model is initially pre-trained on various multimodal datasets within the general domain before being transferred to the chest X-ray domain. Following a prominent VLM, we unify various domain-specific tasks into a simple sequence-to-sequence schema. It enables the model to effectively learn the required knowledge and skills from limited resources in the domain. Demonstrating superior performance on the benchmark datasets provided by the BioNLP shared task, our model benefits from its training across multiple tasks and domains. With subtle techniques including ensemble and factual calibration, our system achieves first place on the RadSum23 leaderboard for the hidden test set.
Towards More Realistic Generation of Information-Seeking Conversations
May 25, 2022
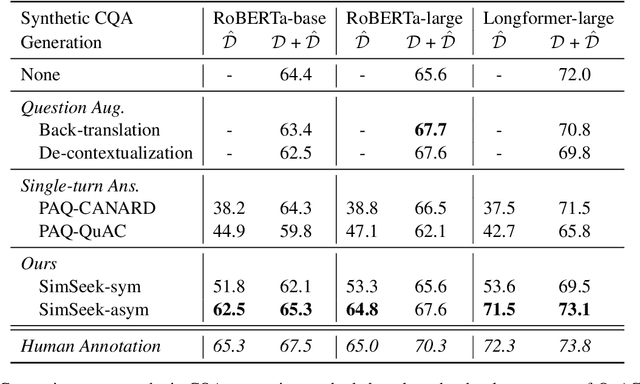

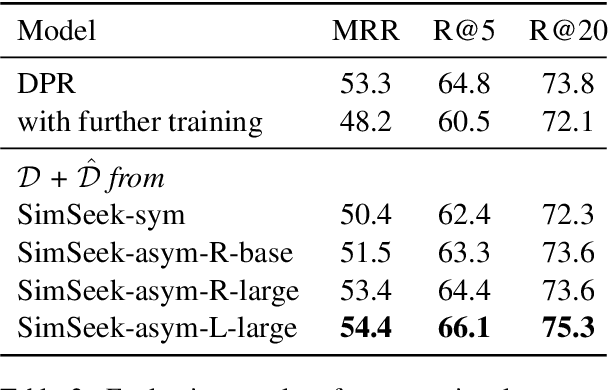
In this paper, we introduce a novel framework SimSeek (simulating information-seeking conversation from unlabeled documents) and compare two variants of it to provide a deeper perspective into the information-seeking behavior. We first introduce a strong simulator for information-symmetric conversation, SimSeek-sym, where questioner and answerer share all knowledge when conversing with one another. Although it simulates reasonable conversations, we take a further step toward more realistic information-seeking conversation. Hence, we propose SimSeek-asym that assumes information asymmetry between two agents, which encourages the questioner to seek new information from an inaccessible document. In our experiments, we demonstrate that SimSeek-asym successfully generates information-seeking conversations for two downstream tasks, CQA and conversational search. In particular, SimSeek-asym improves baseline models by 1.1-1.9 F1 score in QuAC, and by 1.1 of MRR in OR-QuAC. Moreover, we thoroughly analyze our synthetic datasets to identify crucial factors for realistic information-seeking conversation.
Saving Dense Retriever from Shortcut Dependency in Conversational Search
Feb 15, 2022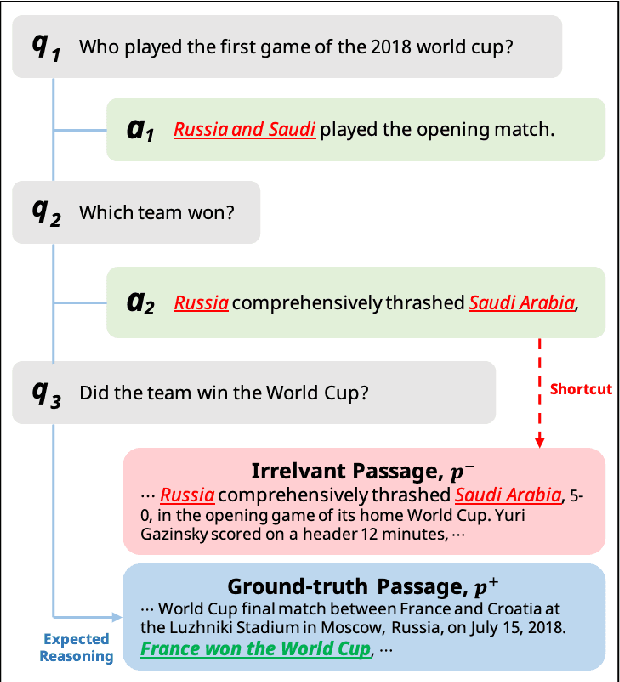
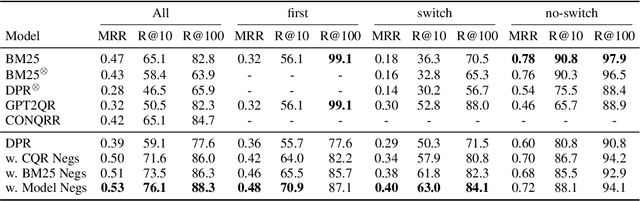
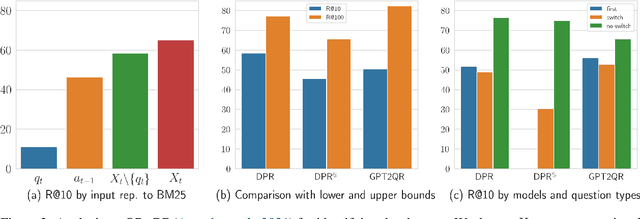
In conversational search (CS), it needs holistic understanding over conversational inputs to retrieve relevant passages. In this paper, we demonstrate the existence of a retrieval shortcut in CS, which causes models to retrieve passages solely relying on partial history while disregarding the latest question. With in-depth analysis, we first show naively trained dense retrievers heavily exploit the shortcut and hence perform poorly when asked to answer history-independent questions. To prevent models from solely relying on the shortcut, we explore iterative hard negatives mined by pre-trained dense retrievers. Experimental results show that training with the iterative hard negatives effectively mitigates the dependency on the shortcut and makes substantial improvement on recent CS benchmarks. Our retrievers achieve new state-of-the-art results, outperforming the previous best models by 9.7 in Recall@10 on QReCC and 12.4 in Recall@5 on TopiOCQA. Furthermore, in our end-to-end QA experiments, FiD readers combined with our retrievers surpass the previous state-of-the-art models by 3.7 and 1.0 EM scores on QReCC and TopiOCQA, respectively.
Learn to Resolve Conversational Dependency: A Consistency Training Framework for Conversational Question Answering
Jun 22, 2021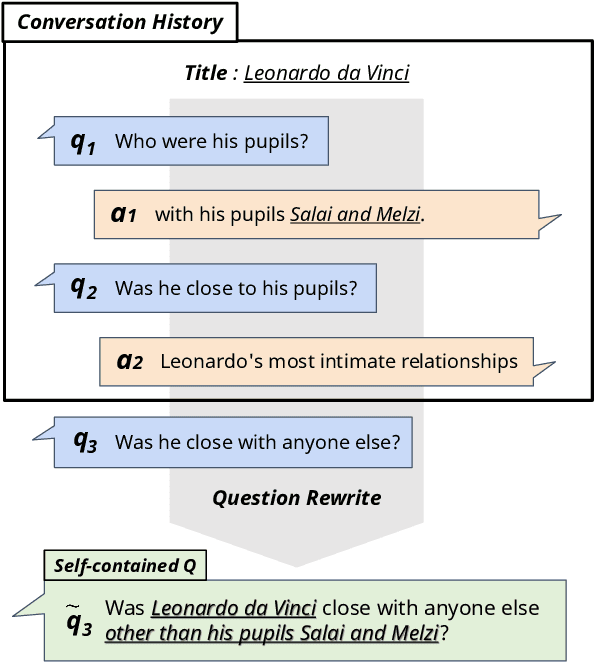
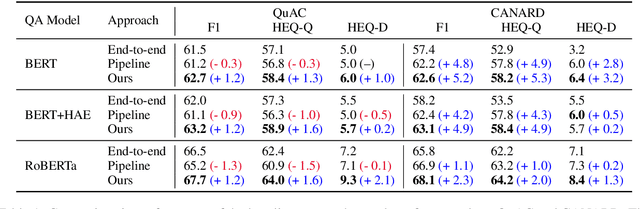
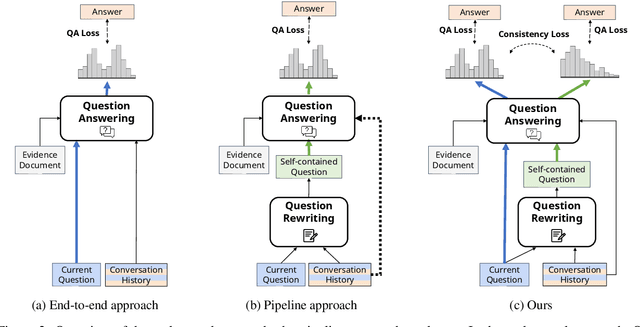
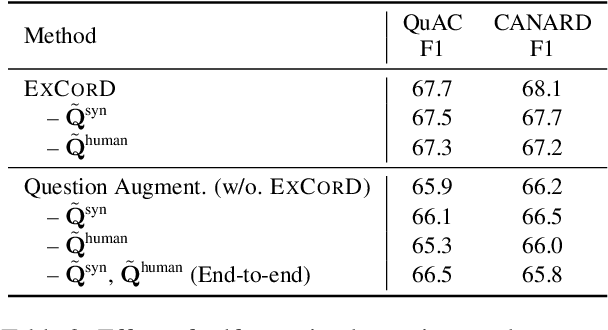
One of the main challenges in conversational question answering (CQA) is to resolve the conversational dependency, such as anaphora and ellipsis. However, existing approaches do not explicitly train QA models on how to resolve the dependency, and thus these models are limited in understanding human dialogues. In this paper, we propose a novel framework, ExCorD (Explicit guidance on how to resolve Conversational Dependency) to enhance the abilities of QA models in comprehending conversational context. ExCorD first generates self-contained questions that can be understood without the conversation history, then trains a QA model with the pairs of original and self-contained questions using a consistency-based regularizer. In our experiments, we demonstrate that ExCorD significantly improves the QA models' performance by up to 1.2 F1 on QuAC, and 5.2 F1 on CANARD, while addressing the limitations of the existing approaches.
Transferability of Natural Language Inference to Biomedical Question Answering
Jul 01, 2020
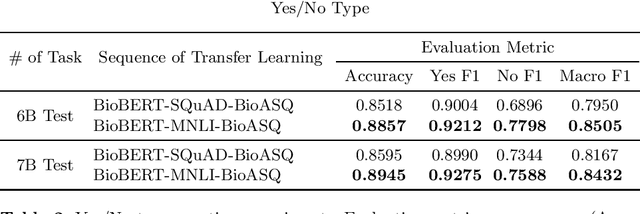
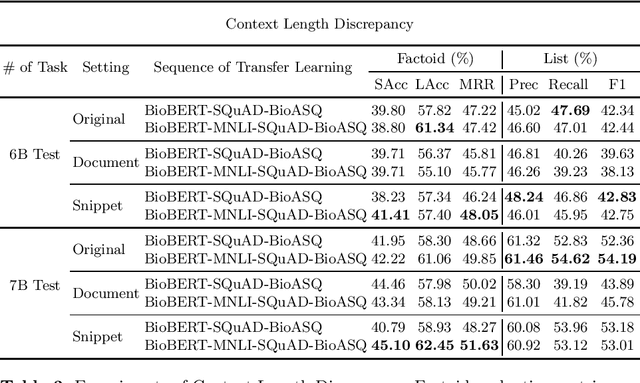
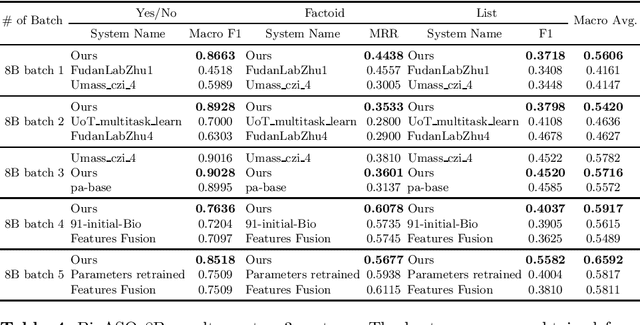
Biomedical question answering (QA) is a challenging problem due to the scarcity of data and the requirement of domain expertise. Growing interests of using pre-trained language models with transfer learning address the issue to some extent. Recently, learning linguistic knowledge of entailment in sentence pairs enhances the performance in general domain QA by leveraging such transferability between the two tasks. In this paper, we focus on facilitating the transferability by unifying the experimental setup from natural language inference (NLI) to biomedical QA. We observe that transferring from entailment data shows effective performance on Yes/No (+5.59%), Factoid (+0.53%), List (+13.58%) type questions compared to previous challenge reports (BioASQ 7B Phase B). We also observe that our method generally performs well in the 8th BioASQ Challenge (Phase B). For sequential transfer learning, the order of how tasks are fine-tuned is important. In factoid- and list-type questions, we thoroughly analyze an intrinsic limitation of the extractive QA setting when these questions are converted to the same format of the Stanford Question Answering Dataset (SQuAD).
Look at the First Sentence: Position Bias in Question Answering
Apr 30, 2020
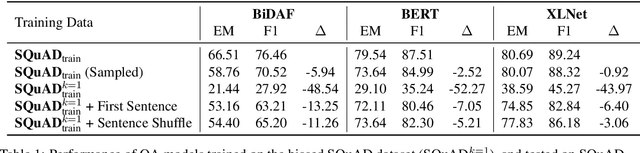
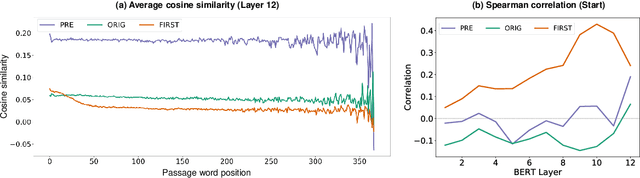
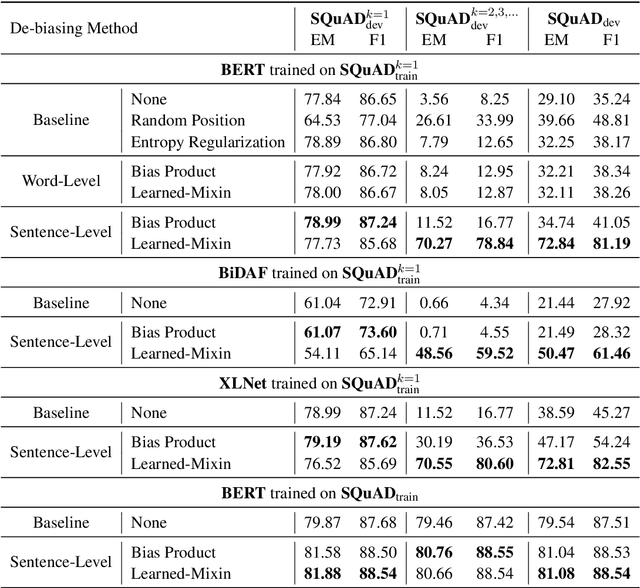
Many extractive question answering models are trained to predict start and end positions of answers. The choice of predicting answers as positions is mainly due to its simplicity and effectiveness. In this study, we hypothesize that when the distribution of the answer positions is highly skewed in the training set (e.g., answers lie only in the k-th sentence of each passage), QA models predicting answers as positions learn spurious positional cues and fail to give answers in different positions. We first illustrate this position bias in popular extractive QA models such as BiDAF and BERT and thoroughly examine how position bias propagates through each layer of BERT. To safely deliver position information without position bias, we train models with various de-biasing methods including entropy regularization and bias ensembling. Among them, we found that using the prior distribution of answer positions as a bias model is very effective at reducing position bias recovering the performance of BERT from 35.24% to 81.17% when trained on a biased SQuAD dataset.