 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThinking Like a Doctor: Conversational Diagnosis through the Exploration of Diagnostic Knowledge Graphs
Feb 02, 2026Conversational diagnosis requires multi-turn history-taking, where an agent asks clarifying questions to refine differential diagnoses under incomplete information. Existing approaches often rely on the parametric knowledge of a model or assume that patients provide rich and concrete information, which is unrealistic. To address these limitations, we propose a conversational diagnosis system that explores a diagnostic knowledge graph to reason in two steps: (i) generating diagnostic hypotheses from the dialogue context, and (ii) verifying hypotheses through clarifying questions, which are repeated until a final diagnosis is reached. Since evaluating the system requires a realistic patient simulator that responds to the system's questions, we adopt a well-established simulator along with patient profiles from MIMIC-IV. We further adapt it to describe symptoms vaguely to reflect real-world patients during early clinical encounters. Experiments show improved diagnostic accuracy and efficiency over strong baselines, and evaluations by physicians support the realism of our simulator and the clinical utility of the generated questions. Our code will be released upon publication.
Mechanism Shift During Post-training from Autoregressive to Masked Diffusion Language Models
Jan 21, 2026Post-training pretrained Autoregressive models (ARMs) into Masked Diffusion models (MDMs) has emerged as a cost-effective strategy to overcome the limitations of sequential generation. However, the internal algorithmic transformations induced by this paradigm shift remain unexplored, leaving it unclear whether post-trained MDMs acquire genuine bidirectional reasoning capabilities or merely repackage autoregressive heuristics. In this work, we address this question by conducting a comparative circuit analysis of ARMs and their MDM counterparts. Our analysis reveals a systematic "mechanism shift" dependent on the structural nature of the task. Structurally, we observe a distinct divergence: while MDMs largely retain autoregressive circuitry for tasks dominated by local causal dependencies, they abandon initialized pathways for global planning tasks, exhibiting distinct rewiring characterized by increased early-layer processing. Semantically, we identify a transition from sharp, localized specialization in ARMs to distributed integration in MDMs. Through these findings, we conclude that diffusion post-training does not merely adapt model parameters but fundamentally reorganizes internal computation to support non-sequential global planning.
Emotional Support Evaluation Framework via Controllable and Diverse Seeker Simulator
Jan 12, 2026As emotional support chatbots have recently gained significant traction across both research and industry, a common evaluation strategy has emerged: use help-seeker simulators to interact with supporter chatbots. However, current simulators suffer from two critical limitations: (1) they fail to capture the behavioral diversity of real-world seekers, often portraying them as overly cooperative, and (2) they lack the controllability required to simulate specific seeker profiles. To address these challenges, we present a controllable seeker simulator driven by nine psychological and linguistic features that underpin seeker behavior. Using authentic Reddit conversations, we train our model via a Mixture-of-Experts (MoE) architecture, which effectively differentiates diverse seeker behaviors into specialized parameter subspaces, thereby enhancing fine-grained controllability. Our simulator achieves superior profile adherence and behavioral diversity compared to existing approaches. Furthermore, evaluating 7 prominent supporter models with our system uncovers previously obscured performance degradations. These findings underscore the utility of our framework in providing a more faithful and stress-tested evaluation for emotional support chatbots.
A Framework for Personalized Persuasiveness Prediction via Context-Aware User Profiling
Jan 09, 2026Estimating the persuasiveness of messages is critical in various applications, from recommender systems to safety assessment of LLMs. While it is imperative to consider the target persuadee's characteristics, such as their values, experiences, and reasoning styles, there is currently no established systematic framework to optimize leveraging a persuadee's past activities (e.g., conversations) to the benefit of a persuasiveness prediction model. To address this problem, we propose a context-aware user profiling framework with two trainable components: a query generator that generates optimal queries to retrieve persuasion-relevant records from a user's history, and a profiler that summarizes these records into a profile to effectively inform the persuasiveness prediction model. Our evaluation on the ChangeMyView Reddit dataset shows consistent improvements over existing methods across multiple predictor models, with gains of up to +13.77%p in F1 score. Further analysis shows that effective user profiles are context-dependent and predictor-specific, rather than relying on static attributes or surface-level similarity. Together, these results highlight the importance of task-oriented, context-dependent user profiling for personalized persuasiveness prediction.
SpeakerSleuth: Evaluating Large Audio-Language Models as Judges for Multi-turn Speaker Consistency
Jan 07, 2026Large Audio-Language Models (LALMs) as judges have emerged as a prominent approach for evaluating speech generation quality, yet their ability to assess speaker consistency across multi-turn conversations remains unexplored. We present SpeakerSleuth, a benchmark evaluating whether LALMs can reliably judge speaker consistency in multi-turn dialogues through three tasks reflecting real-world requirements. We construct 1,818 human-verified evaluation instances across four diverse datasets spanning synthetic and real speech, with controlled acoustic difficulty. Evaluating nine widely-used LALMs, we find that models struggle to reliably detect acoustic inconsistencies. For instance, given audio samples of the same speaker's turns, some models overpredict inconsistency, whereas others are overly lenient. Models further struggle to identify the exact turns that are problematic. When other interlocutors' turns are provided together, performance degrades dramatically as models prioritize textual coherence over acoustic cues, failing to detect even obvious gender switches for a speaker. On the other hand, models perform substantially better in choosing the audio that best matches the speaker among several acoustic variants, demonstrating inherent acoustic discrimination capabilities. These findings expose a significant bias in LALMs: they tend to prioritize text over acoustics, revealing fundamental modality imbalances that need to be addressed to build reliable audio-language judges.
MatKV: Trading Compute for Flash Storage in LLM Inference
Dec 20, 2025We observe two major trends in LLM-based generative AI: (1) inference is becoming the dominant factor in terms of cost and power consumption, surpassing training, and (2) retrieval augmented generation (RAG) is becoming prevalent. When processing long inputs in RAG, the prefill phase of computing the key-value vectors of input text is energy-intensive and time-consuming even with high-end GPUs. Thus, it is crucial to make the prefill phase in RAG inference efficient. To address this issue, we propose MatKV, a scheme that precomputes the key-value vectors (KVs) of RAG objects (e.g., documents), materializes them in inexpensive but fast and power-efficient flash storage, and reuses them at inference time instead of recomputing the KVs using costly and power-inefficient GPU. Experimental results using Hugging Face's Transformers library across state-of-the-art GPUs and flash memory SSDs confirm that, compared to full KV computation on GPUs, MatKV reduces both inference time and power consumption by half for RAG workloads, without severely impacting accuracy in the question-answering task. Furthermore, we demonstrate that MatKV enables additional optimizations in two ways. First, a GPU can decode text while simultaneously loading the materialized KVs for the next instance, reducing load latency. Second, since decoding speed is less sensitive to GPU performance than KV computation, low-end GPUs can be leveraged for decoding without significantly compromising speed once the materialized KVs are loaded into GPU memory. These findings underscore MatKV's potential to make large-scale generative AI applications more cost-effective, power-efficient, and accessible across a wider range of tasks and hardware environments.
Don't Adapt Small Language Models for Tools; Adapt Tool Schemas to the Models
Oct 08, 2025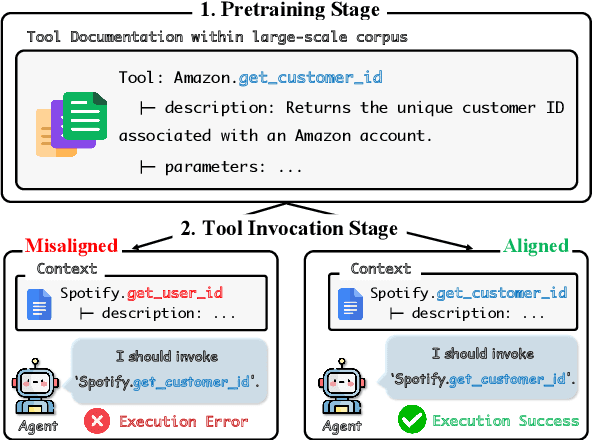

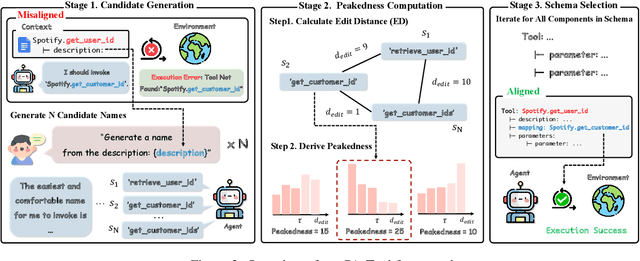

Small language models (SLMs) offer significant computational advantages for tool-augmented AI systems, yet they struggle with tool-use tasks, particularly in selecting appropriate tools and identifying correct parameters. A common failure mode is schema misalignment: models hallucinate plausible but non-existent tool names that reflect naming conventions internalized during pretraining but absent from the provided tool schema. Rather than forcing models to adapt to arbitrary schemas, we propose adapting schemas to align with models' pretrained knowledge. We introduce PA-Tool (Pretraining-Aligned Tool Schema Generation), a training-free method that leverages peakedness-a signal from contamination detection indicating pretraining familiarity-to automatically rename tool components. By generating multiple candidates and selecting those with highest output concentration across samples, PA-Tool identifies pretrain-aligned naming patterns. Experiments on MetaTool and RoTBench show improvements of up to 17% points, with schema misalignment errors reduced by 80%. PA-Tool enables small models to approach state-of-the-art performance while maintaining computational efficiency for adaptation to new tools without retraining. Our work demonstrates that schema-level interventions can unlock the tool-use potential of resource-efficient models by adapting schemas to models rather than models to schemas.
Quantifying Data Contamination in Psychometric Evaluations of LLMs
Oct 08, 2025Recent studies apply psychometric questionnaires to Large Language Models (LLMs) to assess high-level psychological constructs such as values, personality, moral foundations, and dark traits. Although prior work has raised concerns about possible data contamination from psychometric inventories, which may threaten the reliability of such evaluations, there has been no systematic attempt to quantify the extent of this contamination. To address this gap, we propose a framework to systematically measure data contamination in psychometric evaluations of LLMs, evaluating three aspects: (1) item memorization, (2) evaluation memorization, and (3) target score matching. Applying this framework to 21 models from major families and four widely used psychometric inventories, we provide evidence that popular inventories such as the Big Five Inventory (BFI-44) and Portrait Values Questionnaire (PVQ-40) exhibit strong contamination, where models not only memorize items but can also adjust their responses to achieve specific target scores.
ThinkBrake: Mitigating Overthinking in Tool Reasoning
Oct 01, 2025Small reasoning models (SRMs) often overthink during tool use: they reach a correct tool-argument configuration, then continue reasoning and overwrite it with an incorrect final call. We diagnose overthinking via oracle rollouts that inject </think> at sentence boundaries. On the Berkeley Function Calling Leaderboard (BFCL), this oracle termination lifts average accuracy from 85.8\% to 94.2\% while reducing tokens by 80-94\%, revealing substantial recoverable headroom and potential redundant reasoning. While prior work on concise reasoning has largely targeted mathematics, tool reasoning remains underexplored. We adapt various early-termination baselines to tool use and introduce ThinkBrake, a training-free decoding heuristic. ThinkBrake monitors the log-probability margin between </think> and the current top token at sentence boundaries and triggers termination when this margin becomes small. Across BFCL's single turn, non-live and live splits, ThinkBrake preserves or improves accuracy while reducing tokens up to 25\%, outperforming various baselines.
Context Robust Knowledge Editing for Language Models
May 29, 2025Knowledge editing (KE) methods offer an efficient way to modify knowledge in large language models. Current KE evaluations typically assess editing success by considering only the edited knowledge without any preceding contexts. In real-world applications, however, preceding contexts often trigger the retrieval of the original knowledge and undermine the intended edit. To address this issue, we develop CHED -- a benchmark designed to evaluate the context robustness of KE methods. Evaluations on CHED show that they often fail when preceding contexts are present. To mitigate this shortcoming, we introduce CoRE, a KE method designed to strengthen context robustness by minimizing context-sensitive variance in hidden states of the model for edited knowledge. This method not only improves the editing success rate in situations where a preceding context is present but also preserves the overall capabilities of the model. We provide an in-depth analysis of the differing impacts of preceding contexts when introduced as user utterances versus assistant responses, and we dissect attention-score patterns to assess how specific tokens influence editing success.