 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Models Know, How Well They Know It: Knowledge-Weighted Fine-Tuning for Learning When to Say "I Don't Know"
Apr 07, 2026While large language models (LLMs) demonstrate strong capabilities across diverse user queries, they still suffer from hallucinations, often arising from knowledge misalignment between pre-training and fine-tuning. To address this misalignment, we reliably estimate a fine-grained, instance-level knowledge score via multi-sampled inference. Using the knowledge score, we scale the learning signal according to the model's existing knowledge, while encouraging explicit "I don't know" responses for out-of-scope queries. Experimental results show that this approach allows the model to explicitly express uncertainty when it lacks knowledge, while maintaining accuracy on questions it can answer. Furthermore, we propose evaluation metrics for uncertainty, showing that accurate discrimination between known and unknown instances consistently improves performance.
Robust Domain Generalization under Divergent Marginal and Conditional Distributions
Feb 02, 2026Domain generalization (DG) aims to learn predictive models that can generalize to unseen domains. Most existing DG approaches focus on learning domain-invariant representations under the assumption of conditional distribution shift (i.e., primarily addressing changes in $P(X\mid Y)$ while assuming $P(Y)$ remains stable). However, real-world scenarios with multiple domains often involve compound distribution shifts where both the marginal label distribution $P(Y)$ and the conditional distribution $P(X\mid Y)$ vary simultaneously. To address this, we propose a unified framework for robust domain generalization under divergent marginal and conditional distributions. We derive a novel risk bound for unseen domains by explicitly decomposing the joint distribution into marginal and conditional components and characterizing risk gaps arising from both sources of divergence. To operationalize this bound, we design a meta-learning procedure that minimizes and validates the proposed risk bound across seen domains, ensuring strong generalization to unseen ones. Empirical evaluations demonstrate that our method achieves state-of-the-art performance not only on conventional DG benchmarks but also in challenging multi-domain long-tailed recognition settings where both marginal and conditional shifts are pronounced.
What If TSF: A Benchmark for Reframing Forecasting as Scenario-Guided Multimodal Forecasting
Jan 13, 2026Time series forecasting is critical to real-world decision making, yet most existing approaches remain unimodal and rely on extrapolating historical patterns. While recent progress in large language models (LLMs) highlights the potential for multimodal forecasting, existing benchmarks largely provide retrospective or misaligned raw context, making it unclear whether such models meaningfully leverage textual inputs. In practice, human experts incorporate what-if scenarios with historical evidence, often producing distinct forecasts from the same observations under different scenarios. Inspired by this, we introduce What If TSF (WIT), a multimodal forecasting benchmark designed to evaluate whether models can condition their forecasts on contextual text, especially future scenarios. By providing expert-crafted plausible or counterfactual scenarios, WIT offers a rigorous testbed for scenario-guided multimodal forecasting. The benchmark is available at https://github.com/jinkwan1115/WhatIfTSF.
From Threat to Tool: Leveraging Refusal-Aware Injection Attacks for Safety Alignment
Jun 07, 2025Safely aligning large language models (LLMs) often demands extensive human-labeled preference data, a process that's both costly and time-consuming. While synthetic data offers a promising alternative, current methods frequently rely on complex iterative prompting or auxiliary models. To address this, we introduce Refusal-Aware Adaptive Injection (RAAI), a straightforward, training-free, and model-agnostic framework that repurposes LLM attack techniques. RAAI works by detecting internal refusal signals and adaptively injecting predefined phrases to elicit harmful, yet fluent, completions. Our experiments show RAAI effectively jailbreaks LLMs, increasing the harmful response rate from a baseline of 2.15% to up to 61.04% on average across four benchmarks. Crucially, fine-tuning LLMs with the synthetic data generated by RAAI improves model robustness against harmful prompts while preserving general capabilities on standard tasks like MMLU and ARC. This work highlights how LLM attack methodologies can be reframed as practical tools for scalable and controllable safety alignment.
When Vision Models Meet Parameter Efficient Look-Aside Adapters Without Large-Scale Audio Pretraining
Dec 08, 2024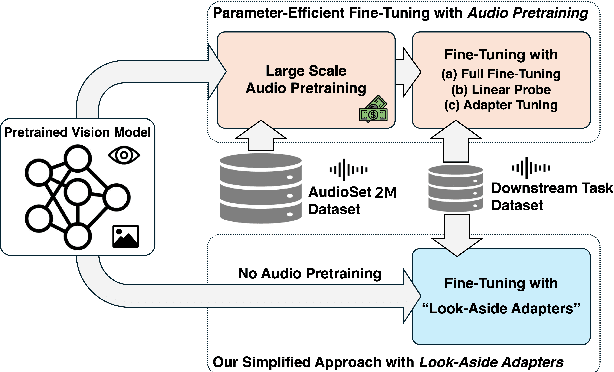
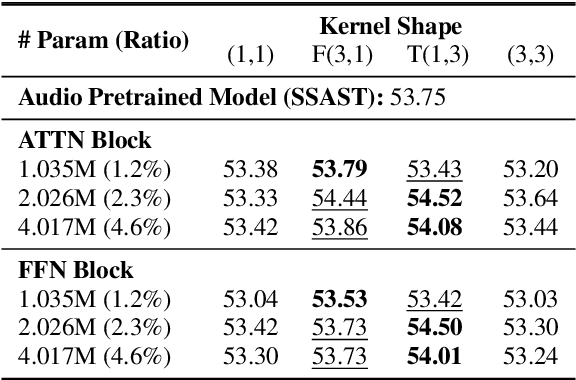
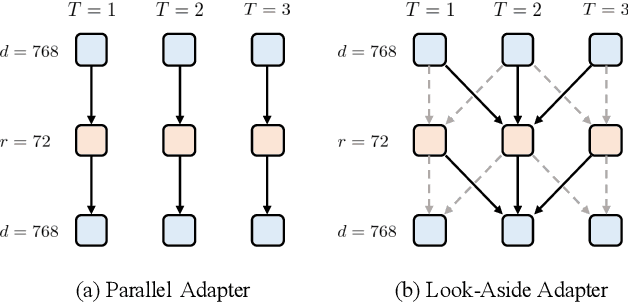
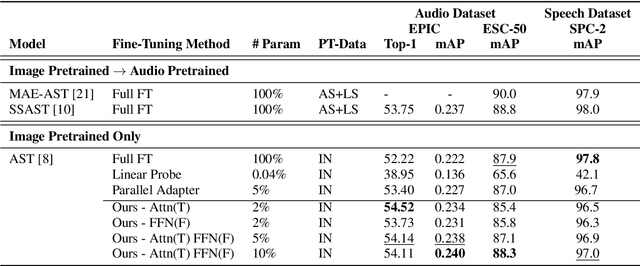
Recent studies show that pretrained vision models can boost performance in audio downstream tasks. To enhance the performance further, an additional pretraining stage with large scale audio data is typically required to infuse audio specific knowledge into the vision model. However, such approaches require extensive audio data and a carefully designed objective function. In this work, we propose bypassing the pretraining stage by directly fine-tuning the vision model with our Look Aside Adapter (LoAA) designed for efficient audio understanding. Audio spectrum data is represented across two heterogeneous dimensions time and frequency and we refine adapters to facilitate interactions between tokens across these dimensions. Our experiments demonstrate that our adapters allow vision models to reach or surpass the performance of pretrained audio models in various audio and speech tasks, offering a resource efficient and effective solution for leveraging vision models in audio applications.
Model-based Preference Optimization in Abstractive Summarization without Human Feedback
Sep 27, 2024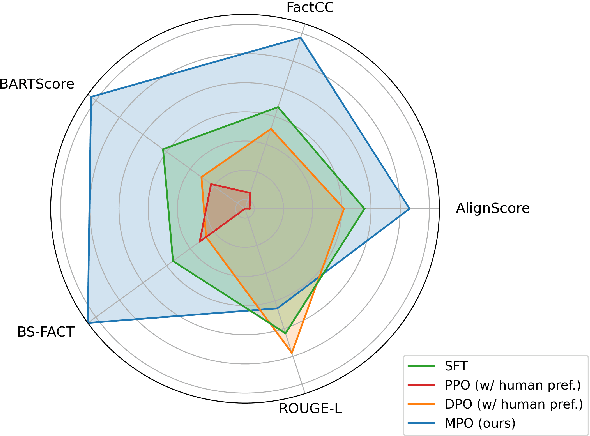
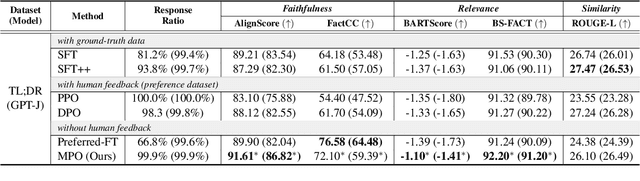

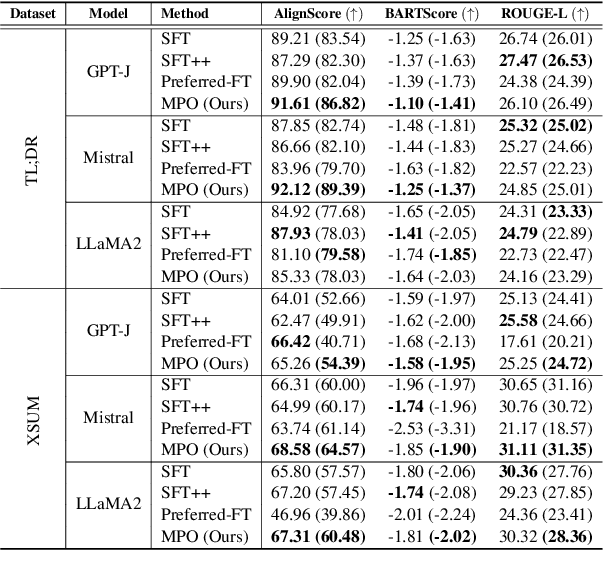
In abstractive summarization, the challenge of producing concise and accurate summaries arises from the vast amount of information contained in the source document. Consequently, although Large Language Models (LLMs) can generate fluent text, they often introduce inaccuracies by hallucinating content not found in the original source. While supervised fine-tuning methods that maximize likelihood contribute to this issue, they do not consistently enhance the faithfulness of the summaries. Preference-based optimization methods, such as Direct Preference Optimization (DPO), can further refine the model to align with human preferences. However, these methods still heavily depend on costly human feedback. In this work, we introduce a novel and straightforward approach called Model-based Preference Optimization (MPO) to fine-tune LLMs for improved summarization abilities without any human feedback. By leveraging the model's inherent summarization capabilities, we create a preference dataset that is fully generated by the model using different decoding strategies. Our experiments on standard summarization datasets and various metrics demonstrate that our proposed MPO significantly enhances the quality of generated summaries without relying on human feedback.
Mitigating Hallucination in Abstractive Summarization with Domain-Conditional Mutual Information
Apr 15, 2024A primary challenge in abstractive summarization is hallucination -- the phenomenon where a model generates plausible text that is absent in the source text. We hypothesize that the domain (or topic) of the source text triggers the model to generate text that is highly probable in the domain, neglecting the details of the source text. To alleviate this model bias, we introduce a decoding strategy based on domain-conditional pointwise mutual information. This strategy adjusts the generation probability of each token by comparing it with the token's marginal probability within the domain of the source text. According to evaluation on the XSUM dataset, our method demonstrates improvement in terms of faithfulness and source relevance. The code is publicly available at \url{https://github.com/qqplot/dcpmi}.