 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStable On-Policy Distillation through Adaptive Target Reformulation
Jan 12, 2026Knowledge distillation (KD) is a widely adopted technique for transferring knowledge from large language models to smaller student models; however, conventional supervised KD often suffers from a distribution mismatch between training and inference. While on-policy KD approaches attempt to mitigate this issue by learning directly from student-generated outputs, they frequently encounter training instabilities because the distributional gap between the novice student and the expert teacher is often too wide to bridge directly. These challenges manifest as pathological gradients in forward KL objectives or diversity collapse in reverse KL regimes. To address these limitations, we propose Veto, an objective-level reformulation that constructs a geometric bridge in the logit space. Unlike prior methods that mix data samples, Veto creates an intermediate target distribution that promotes alignment between the teacher and the student. By introducing a tunable parameter beta, Veto serves as an Adaptive Gradient Veto that stabilizes optimization by suppressing harmful gradients on low-confidence tokens, while simultaneously acting as a Decisiveness Knob to balance reward-driven performance with output diversity. Extensive experiments across various reasoning and generation tasks demonstrate that Veto consistently outperforms supervised fine-tuning and existing on-policy baselines.
ATAS: Any-to-Any Self-Distillation for Enhanced Open-Vocabulary Dense Prediction
Jun 10, 2025Vision-language models such as CLIP have recently propelled open-vocabulary dense prediction tasks by enabling recognition of a broad range of visual concepts. However, CLIP still struggles with fine-grained, region-level understanding, hindering its effectiveness on these dense prediction tasks. We identify two pivotal factors required to address this limitation: semantic coherence and fine-grained vision-language alignment. Current adaptation methods often improve fine-grained alignment at the expense of semantic coherence, and often rely on extra modules or supervised fine-tuning. To overcome these issues, we propose Any-to-Any Self-Distillation (ATAS), a novel approach that simultaneously enhances semantic coherence and fine-grained alignment by leveraging own knowledge of a model across all representation levels. Unlike prior methods, ATAS uses only unlabeled images and an internal self-distillation process to refine representations of CLIP vision encoders, preserving local semantic consistency while sharpening local detail recognition. On open-vocabulary object detection and semantic segmentation benchmarks, ATAS achieves substantial performance gains, outperforming baseline CLIP models. These results validate the effectiveness of our approach and underscore the importance of jointly maintaining semantic coherence and fine-grained alignment for advanced open-vocabulary dense prediction.
When Vision Models Meet Parameter Efficient Look-Aside Adapters Without Large-Scale Audio Pretraining
Dec 08, 2024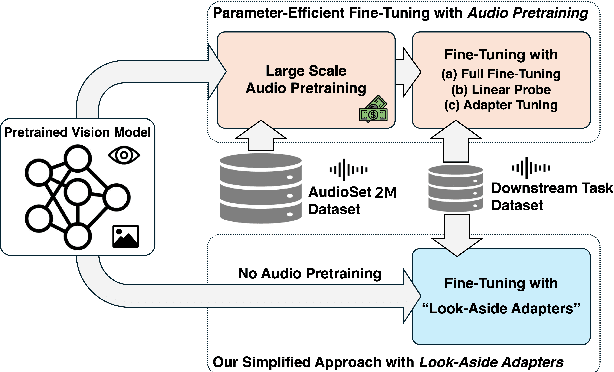
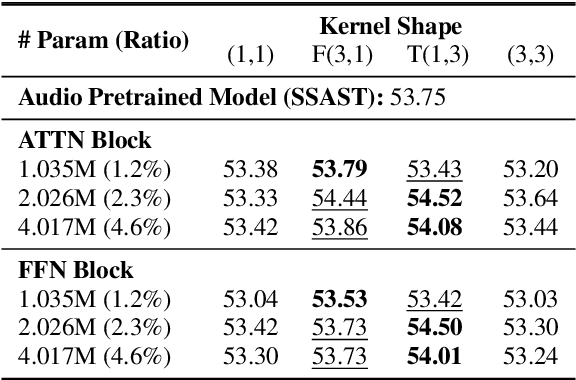
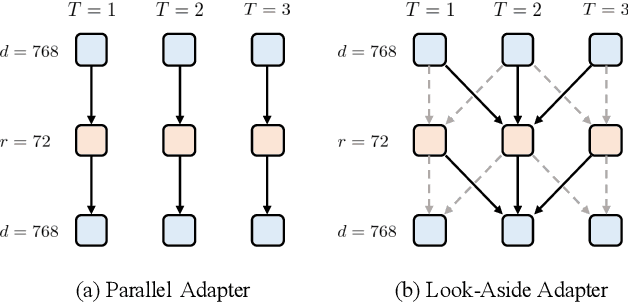
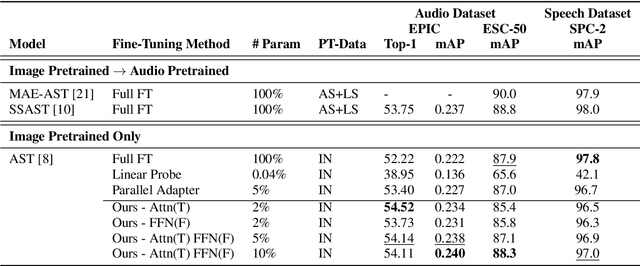
Recent studies show that pretrained vision models can boost performance in audio downstream tasks. To enhance the performance further, an additional pretraining stage with large scale audio data is typically required to infuse audio specific knowledge into the vision model. However, such approaches require extensive audio data and a carefully designed objective function. In this work, we propose bypassing the pretraining stage by directly fine-tuning the vision model with our Look Aside Adapter (LoAA) designed for efficient audio understanding. Audio spectrum data is represented across two heterogeneous dimensions time and frequency and we refine adapters to facilitate interactions between tokens across these dimensions. Our experiments demonstrate that our adapters allow vision models to reach or surpass the performance of pretrained audio models in various audio and speech tasks, offering a resource efficient and effective solution for leveraging vision models in audio applications.