 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel-based Preference Optimization in Abstractive Summarization without Human Feedback
Paper and Code
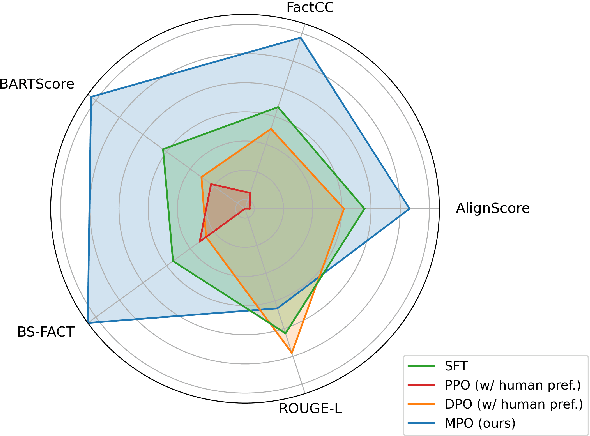
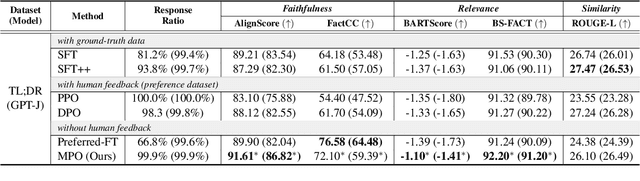

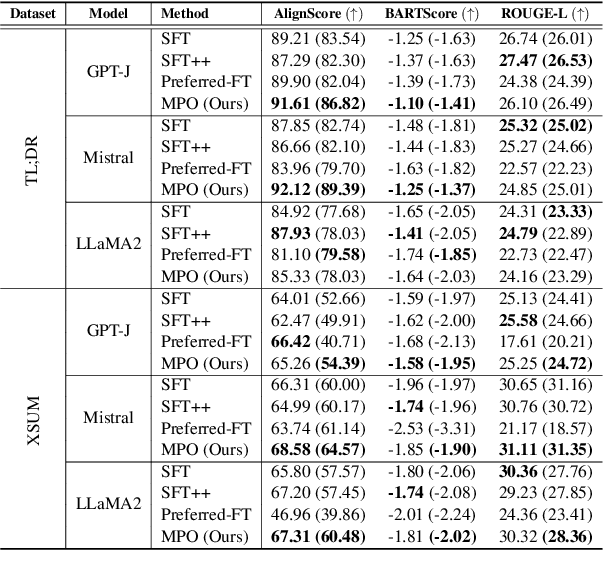
In abstractive summarization, the challenge of producing concise and accurate summaries arises from the vast amount of information contained in the source document. Consequently, although Large Language Models (LLMs) can generate fluent text, they often introduce inaccuracies by hallucinating content not found in the original source. While supervised fine-tuning methods that maximize likelihood contribute to this issue, they do not consistently enhance the faithfulness of the summaries. Preference-based optimization methods, such as Direct Preference Optimization (DPO), can further refine the model to align with human preferences. However, these methods still heavily depend on costly human feedback. In this work, we introduce a novel and straightforward approach called Model-based Preference Optimization (MPO) to fine-tune LLMs for improved summarization abilities without any human feedback. By leveraging the model's inherent summarization capabilities, we create a preference dataset that is fully generated by the model using different decoding strategies. Our experiments on standard summarization datasets and various metrics demonstrate that our proposed MPO significantly enhances the quality of generated summaries without relying on human feedback.