 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Domain Generalization under Divergent Marginal and Conditional Distributions
Feb 02, 2026Domain generalization (DG) aims to learn predictive models that can generalize to unseen domains. Most existing DG approaches focus on learning domain-invariant representations under the assumption of conditional distribution shift (i.e., primarily addressing changes in $P(X\mid Y)$ while assuming $P(Y)$ remains stable). However, real-world scenarios with multiple domains often involve compound distribution shifts where both the marginal label distribution $P(Y)$ and the conditional distribution $P(X\mid Y)$ vary simultaneously. To address this, we propose a unified framework for robust domain generalization under divergent marginal and conditional distributions. We derive a novel risk bound for unseen domains by explicitly decomposing the joint distribution into marginal and conditional components and characterizing risk gaps arising from both sources of divergence. To operationalize this bound, we design a meta-learning procedure that minimizes and validates the proposed risk bound across seen domains, ensuring strong generalization to unseen ones. Empirical evaluations demonstrate that our method achieves state-of-the-art performance not only on conventional DG benchmarks but also in challenging multi-domain long-tailed recognition settings where both marginal and conditional shifts are pronounced.
Angular Gradient Sign Method: Uncovering Vulnerabilities in Hyperbolic Networks
Nov 17, 2025Adversarial examples in neural networks have been extensively studied in Euclidean geometry, but recent advances in \textit{hyperbolic networks} call for a reevaluation of attack strategies in non-Euclidean geometries. Existing methods such as FGSM and PGD apply perturbations without regard to the underlying hyperbolic structure, potentially leading to inefficient or geometrically inconsistent attacks. In this work, we propose a novel adversarial attack that explicitly leverages the geometric properties of hyperbolic space. Specifically, we compute the gradient of the loss function in the tangent space of hyperbolic space, decompose it into a radial (depth) component and an angular (semantic) component, and apply perturbation derived solely from the angular direction. Our method generates adversarial examples by focusing perturbations in semantically sensitive directions encoded in angular movement within the hyperbolic geometry. Empirical results on image classification, cross-modal retrieval tasks and network architectures demonstrate that our attack achieves higher fooling rates than conventional adversarial attacks, while producing high-impact perturbations with deeper insights into vulnerabilities of hyperbolic embeddings. This work highlights the importance of geometry-aware adversarial strategies in curved representation spaces and provides a principled framework for attacking hierarchical embeddings.
TAROT: Towards Essentially Domain-Invariant Robustness with Theoretical Justification
May 10, 2025Robust domain adaptation against adversarial attacks is a critical research area that aims to develop models capable of maintaining consistent performance across diverse and challenging domains. In this paper, we derive a new generalization bound for robust risk on the target domain using a novel divergence measure specifically designed for robust domain adaptation. Building upon this, we propose a new algorithm named TAROT, which is designed to enhance both domain adaptability and robustness. Through extensive experiments, TAROT not only surpasses state-of-the-art methods in accuracy and robustness but also significantly enhances domain generalization and scalability by effectively learning domain-invariant features. In particular, TAROT achieves superior performance on the challenging DomainNet dataset, demonstrating its ability to learn domain-invariant representations that generalize well across different domains, including unseen ones. These results highlight the broader applicability of our approach in real-world domain adaptation scenarios.
Enhancing Adversarial Robustness in Low-Label Regime via Adaptively Weighted Regularization and Knowledge Distillation
Aug 08, 2023Adversarial robustness is a research area that has recently received a lot of attention in the quest for trustworthy artificial intelligence. However, recent works on adversarial robustness have focused on supervised learning where it is assumed that labeled data is plentiful. In this paper, we investigate semi-supervised adversarial training where labeled data is scarce. We derive two upper bounds for the robust risk and propose a regularization term for unlabeled data motivated by these two upper bounds. Then, we develop a semi-supervised adversarial training algorithm that combines the proposed regularization term with knowledge distillation using a semi-supervised teacher (i.e., a teacher model trained using a semi-supervised learning algorithm). Our experiments show that our proposed algorithm achieves state-of-the-art performance with significant margins compared to existing algorithms. In particular, compared to supervised learning algorithms, performance of our proposed algorithm is not much worse even when the amount of labeled data is very small. For example, our algorithm with only 8\% labeled data is comparable to supervised adversarial training algorithms that use all labeled data, both in terms of standard and robust accuracies on CIFAR-10.
Improving Performance of Semi-Supervised Learning by Adversarial Attacks
Aug 08, 2023

Semi-supervised learning (SSL) algorithm is a setup built upon a realistic assumption that access to a large amount of labeled data is tough. In this study, we present a generalized framework, named SCAR, standing for Selecting Clean samples with Adversarial Robustness, for improving the performance of recent SSL algorithms. By adversarially attacking pre-trained models with semi-supervision, our framework shows substantial advances in classifying images. We introduce how adversarial attacks successfully select high-confident unlabeled data to be labeled with current predictions. On CIFAR10, three recent SSL algorithms with SCAR result in significantly improved image classification.
Masked Bayesian Neural Networks : Theoretical Guarantee and its Posterior Inference
May 24, 2023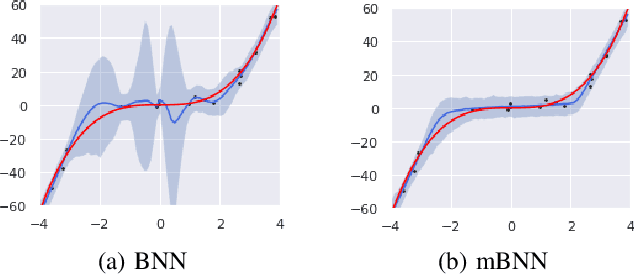
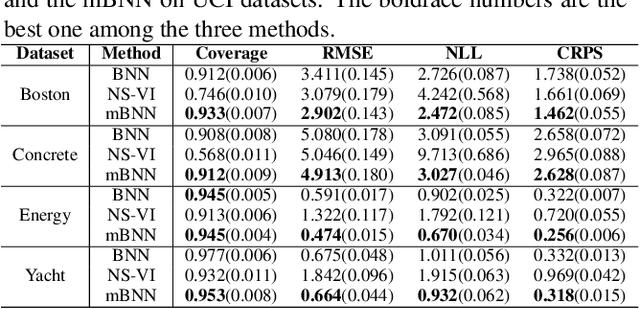
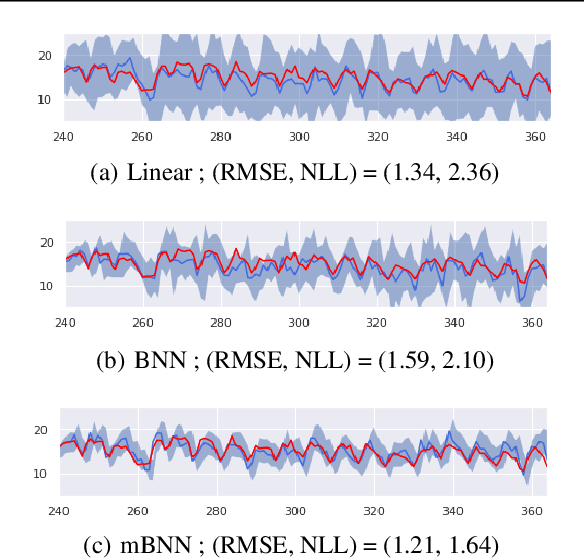
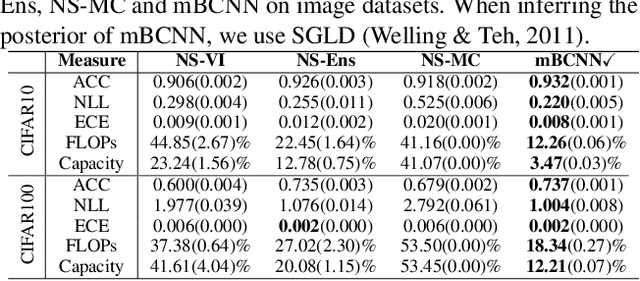
Bayesian approaches for learning deep neural networks (BNN) have been received much attention and successfully applied to various applications. Particularly, BNNs have the merit of having better generalization ability as well as better uncertainty quantification. For the success of BNN, search an appropriate architecture of the neural networks is an important task, and various algorithms to find good sparse neural networks have been proposed. In this paper, we propose a new node-sparse BNN model which has good theoretical properties and is computationally feasible. We prove that the posterior concentration rate to the true model is near minimax optimal and adaptive to the smoothness of the true model. In particular the adaptiveness is the first of its kind for node-sparse BNNs. In addition, we develop a novel MCMC algorithm which makes the Bayesian inference of the node-sparse BNN model feasible in practice.
Adaptive Regularization for Adversarial Training
Jun 07, 2022


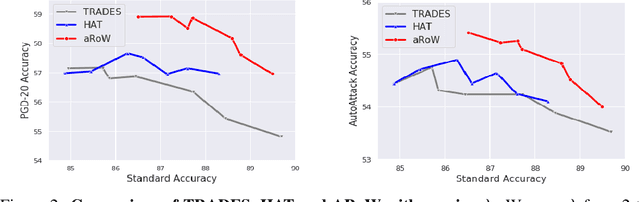
Adversarial training, which is to enhance robustness against adversarial attacks, has received much attention because it is easy to generate human-imperceptible perturbations of data to deceive a given deep neural network. In this paper, we propose a new adversarial training algorithm that is theoretically well motivated and empirically superior to other existing algorithms. A novel feature of the proposed algorithm is to use a data-adaptive regularization for robustifying a prediction model. We apply more regularization to data which are more vulnerable to adversarial attacks and vice versa. Even though the idea of data-adaptive regularization is not new, our data-adaptive regularization has a firm theoretical base of reducing an upper bound of the robust risk. Numerical experiments illustrate that our proposed algorithm improves the generalization (accuracy on clean samples) and robustness (accuracy on adversarial attacks) simultaneously to achieve the state-of-the-art performance.
Masked Bayesian Neural Networks : Computation and Optimality
Jun 02, 2022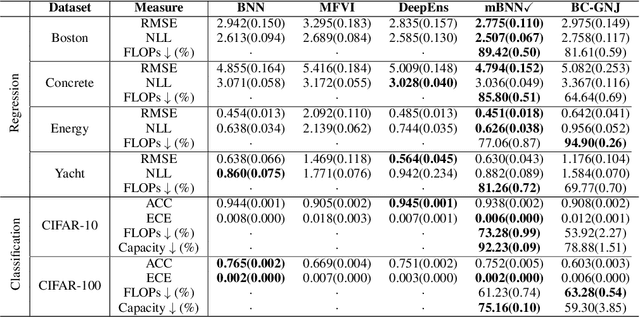
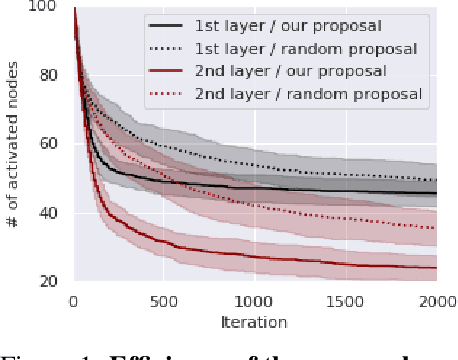
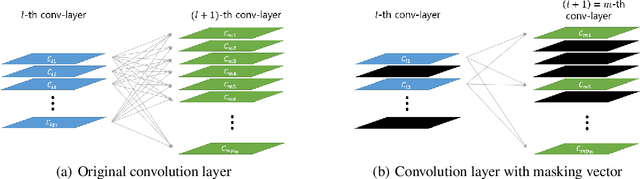
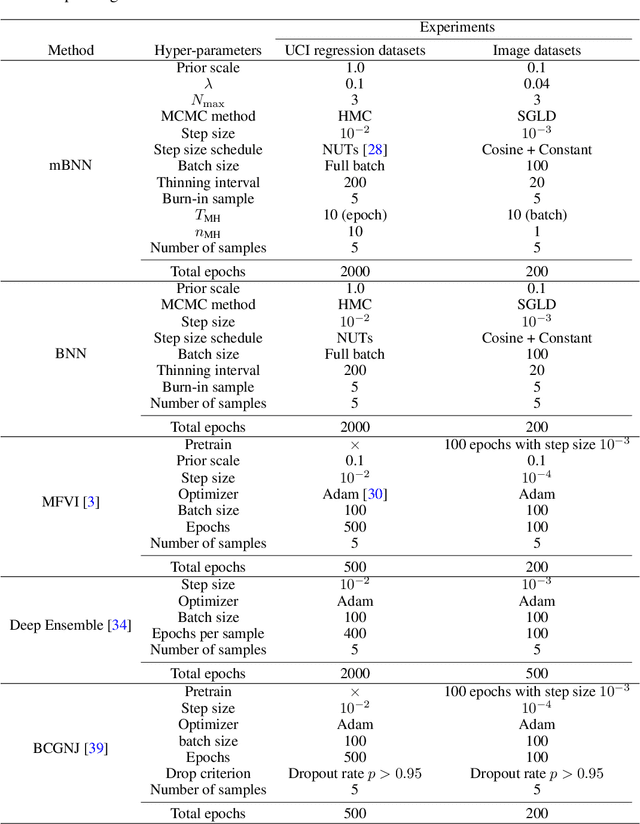
As data size and computing power increase, the architectures of deep neural networks (DNNs) have been getting more complex and huge, and thus there is a growing need to simplify such complex and huge DNNs. In this paper, we propose a novel sparse Bayesian neural network (BNN) which searches a good DNN with an appropriate complexity. We employ the masking variables at each node which can turn off some nodes according to the posterior distribution to yield a nodewise sparse DNN. We devise a prior distribution such that the posterior distribution has theoretical optimalities (i.e. minimax optimality and adaptiveness), and develop an efficient MCMC algorithm. By analyzing several benchmark datasets, we illustrate that the proposed BNN performs well compared to other existing methods in the sense that it discovers well condensed DNN architectures with similar prediction accuracy and uncertainty quantification compared to large DNNs.