 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFair Bayesian Model-Based Clustering
Jun 15, 2025Fair clustering has become a socially significant task with the advancement of machine learning technologies and the growing demand for trustworthy AI. Group fairness ensures that the proportions of each sensitive group are similar in all clusters. Most existing group-fair clustering methods are based on the $K$-means clustering and thus require the distance between instances and the number of clusters to be given in advance. To resolve this limitation, we propose a fair Bayesian model-based clustering called Fair Bayesian Clustering (FBC). We develop a specially designed prior which puts its mass only on fair clusters, and implement an efficient MCMC algorithm. Advantages of FBC are that it can infer the number of clusters and can be applied to any data type as long as the likelihood is defined (e.g., categorical data). Experiments on real-world datasets show that FBC (i) reasonably infers the number of clusters, (ii) achieves a competitive utility-fairness trade-off compared to existing fair clustering methods, and (iii) performs well on categorical data.
Fair Clustering via Alignment
May 14, 2025Algorithmic fairness in clustering aims to balance the proportions of instances assigned to each cluster with respect to a given sensitive attribute. While recently developed fair clustering algorithms optimize clustering objectives under specific fairness constraints, their inherent complexity or approximation often results in suboptimal clustering utility or numerical instability in practice. To resolve these limitations, we propose a new fair clustering algorithm based on a novel decomposition of the fair K-means clustering objective function. The proposed algorithm, called Fair Clustering via Alignment (FCA), operates by alternately (i) finding a joint probability distribution to align the data from different protected groups, and (ii) optimizing cluster centers in the aligned space. A key advantage of FCA is that it theoretically guarantees approximately optimal clustering utility for any given fairness level without complex constraints, thereby enabling high-utility fair clustering in practice. Experiments show that FCA outperforms existing methods by (i) attaining a superior trade-off between fairness level and clustering utility, and (ii) achieving near-perfect fairness without numerical instability.
Fair Representation Learning for Continuous Sensitive Attributes using Expectation of Integral Probability Metrics
May 09, 2025AI fairness, also known as algorithmic fairness, aims to ensure that algorithms operate without bias or discrimination towards any individual or group. Among various AI algorithms, the Fair Representation Learning (FRL) approach has gained significant interest in recent years. However, existing FRL algorithms have a limitation: they are primarily designed for categorical sensitive attributes and thus cannot be applied to continuous sensitive attributes, such as age or income. In this paper, we propose an FRL algorithm for continuous sensitive attributes. First, we introduce a measure called the Expectation of Integral Probability Metrics (EIPM) to assess the fairness level of representation space for continuous sensitive attributes. We demonstrate that if the distribution of the representation has a low EIPM value, then any prediction head constructed on the top of the representation become fair, regardless of the selection of the prediction head. Furthermore, EIPM possesses a distinguished advantage in that it can be accurately estimated using our proposed estimator with finite samples. Based on these properties, we propose a new FRL algorithm called Fair Representation using EIPM with MMD (FREM). Experimental evidences show that FREM outperforms other baseline methods.
ReLU integral probability metric and its applications
Apr 26, 2025We propose a parametric integral probability metric (IPM) to measure the discrepancy between two probability measures. The proposed IPM leverages a specific parametric family of discriminators, such as single-node neural networks with ReLU activation, to effectively distinguish between distributions, making it applicable in high-dimensional settings. By optimizing over the parameters of the chosen discriminator class, the proposed IPM demonstrates that its estimators have good convergence rates and can serve as a surrogate for other IPMs that use smooth nonparametric discriminator classes. We present an efficient algorithm for practical computation, offering a simple implementation and requiring fewer hyperparameters. Furthermore, we explore its applications in various tasks, such as covariate balancing for causal inference and fair representation learning. Across such diverse applications, we demonstrate that the proposed IPM provides strong theoretical guarantees, and empirical experiments show that it achieves comparable or even superior performance to other methods.
Fairness Through Matching
Jan 06, 2025



Group fairness requires that different protected groups, characterized by a given sensitive attribute, receive equal outcomes overall. Typically, the level of group fairness is measured by the statistical gap between predictions from different protected groups. In this study, we reveal an implicit property of existing group fairness measures, which provides an insight into how the group-fair models behave. Then, we develop a new group-fair constraint based on this implicit property to learn group-fair models. To do so, we first introduce a notable theoretical observation: every group-fair model has an implicitly corresponding transport map between the input spaces of each protected group. Based on this observation, we introduce a new group fairness measure termed Matched Demographic Parity (MDP), which quantifies the averaged gap between predictions of two individuals (from different protected groups) matched by a given transport map. Then, we prove that any transport map can be used in MDP to learn group-fair models, and develop a novel algorithm called Fairness Through Matching (FTM), which learns a group-fair model using MDP constraint with an user-specified transport map. We specifically propose two favorable types of transport maps for MDP, based on the optimal transport theory, and discuss their advantages. Experiments reveal that FTM successfully trains group-fair models with certain desirable properties by choosing the transport map accordingly.
Improving Performance of Semi-Supervised Learning by Adversarial Attacks
Aug 08, 2023

Semi-supervised learning (SSL) algorithm is a setup built upon a realistic assumption that access to a large amount of labeled data is tough. In this study, we present a generalized framework, named SCAR, standing for Selecting Clean samples with Adversarial Robustness, for improving the performance of recent SSL algorithms. By adversarially attacking pre-trained models with semi-supervision, our framework shows substantial advances in classifying images. We introduce how adversarial attacks successfully select high-confident unlabeled data to be labeled with current predictions. On CIFAR10, three recent SSL algorithms with SCAR result in significantly improved image classification.
ODIM: an efficient method to detect outliers via inlier-memorization effect of deep generative models
Jan 11, 2023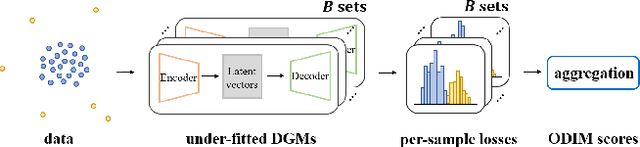
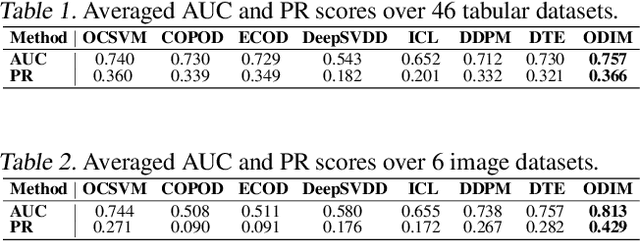

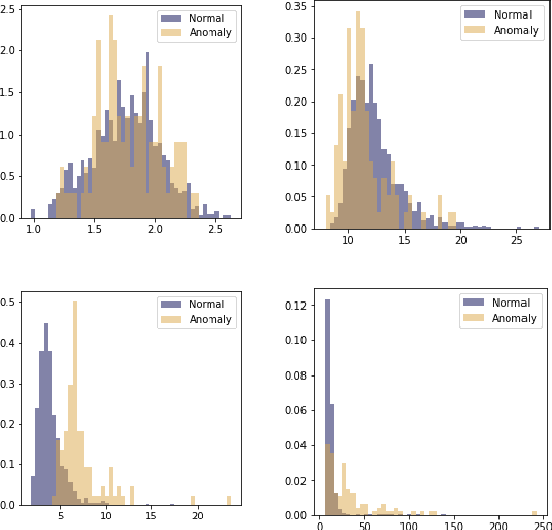
Identifying whether a given sample is an outlier or not is an important issue in various real-world domains. This study aims to solve the unsupervised outlier detection problem where training data contain outliers, but any label information about inliers and outliers is not given. We propose a powerful and efficient learning framework to identify outliers in a training data set using deep neural networks. We start with a new observation called the inlier-memorization (IM) effect. When we train a deep generative model with data contaminated with outliers, the model first memorizes inliers before outliers. Exploiting this finding, we develop a new method called the outlier detection via the IM effect (ODIM). The ODIM only requires a few updates; thus, it is computationally efficient, tens of times faster than other deep-learning-based algorithms. Also, the ODIM filters out outliers successfully, regardless of the types of data, such as tabular, image, and sequential. We empirically demonstrate the superiority and efficiency of the ODIM by analyzing 20 data sets.
Learning fair representation with a parametric integral probability metric
Feb 17, 2022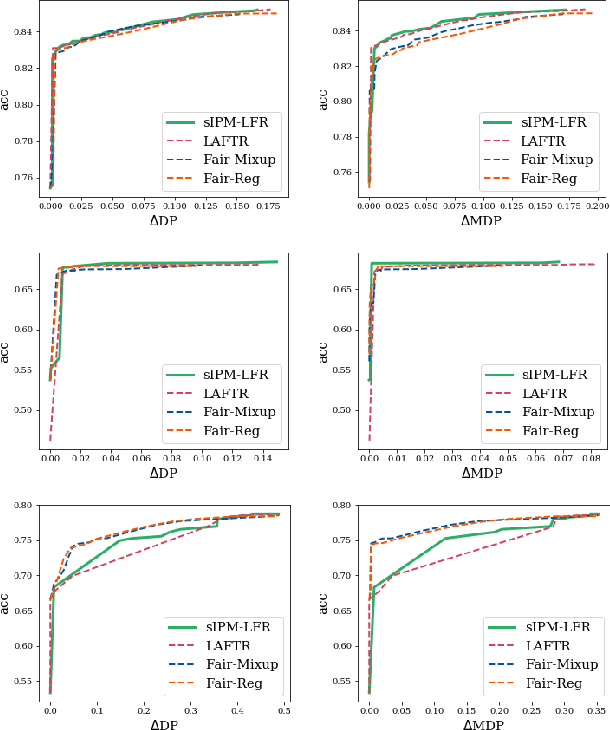
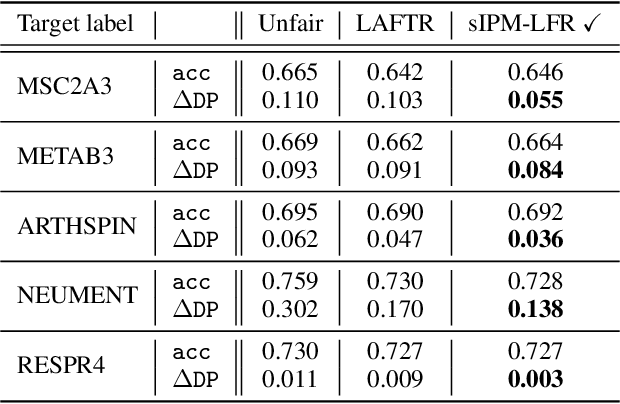
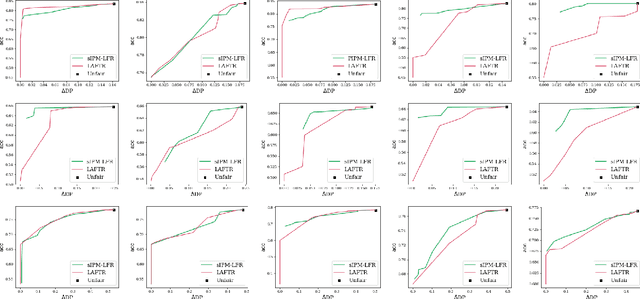
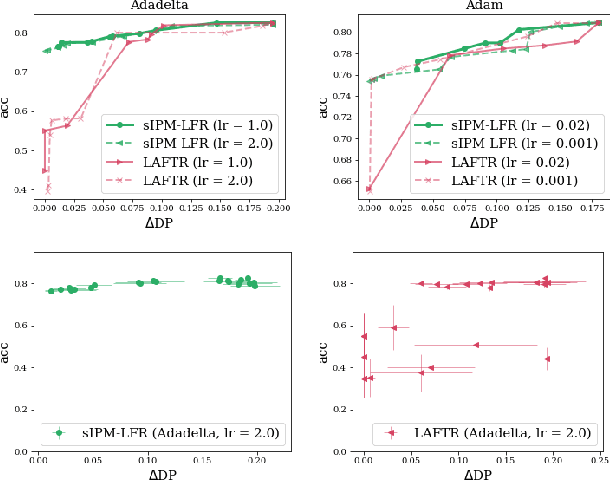
As they have a vital effect on social decision-making, AI algorithms should be not only accurate but also fair. Among various algorithms for fairness AI, learning fair representation (LFR), whose goal is to find a fair representation with respect to sensitive variables such as gender and race, has received much attention. For LFR, the adversarial training scheme is popularly employed as is done in the generative adversarial network type algorithms. The choice of a discriminator, however, is done heuristically without justification. In this paper, we propose a new adversarial training scheme for LFR, where the integral probability metric (IPM) with a specific parametric family of discriminators is used. The most notable result of the proposed LFR algorithm is its theoretical guarantee about the fairness of the final prediction model, which has not been considered yet. That is, we derive theoretical relations between the fairness of representation and the fairness of the prediction model built on the top of the representation (i.e., using the representation as the input). Moreover, by numerical experiments, we show that our proposed LFR algorithm is computationally lighter and more stable, and the final prediction model is competitive or superior to other LFR algorithms using more complex discriminators.
SLIDE: a surrogate fairness constraint to ensure fairness consistency
Feb 07, 2022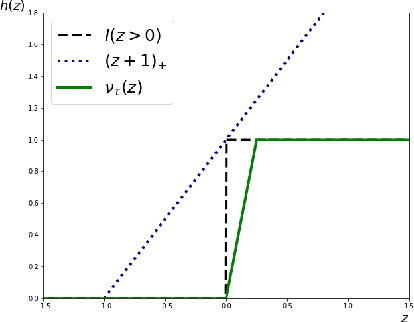
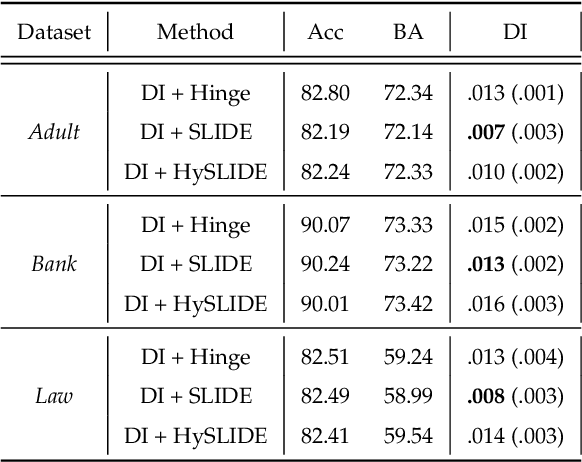
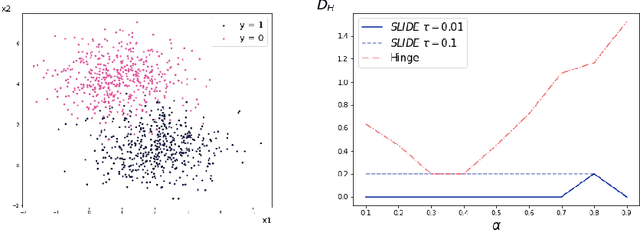
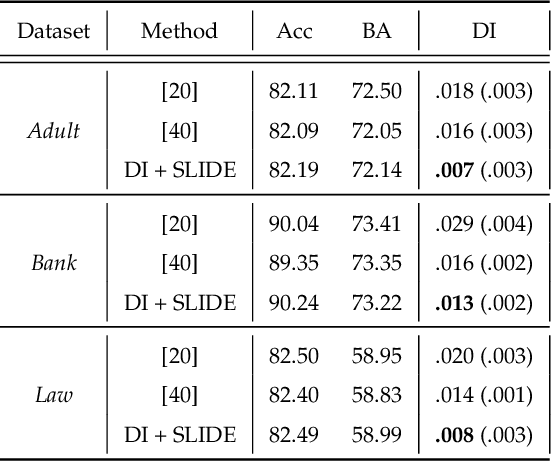
As they have a vital effect on social decision makings, AI algorithms should be not only accurate and but also fair. Among various algorithms for fairness AI, learning a prediction model by minimizing the empirical risk (e.g., cross-entropy) subject to a given fairness constraint has received much attention. To avoid computational difficulty, however, a given fairness constraint is replaced by a surrogate fairness constraint as the 0-1 loss is replaced by a convex surrogate loss for classification problems. In this paper, we investigate the validity of existing surrogate fairness constraints and propose a new surrogate fairness constraint called SLIDE, which is computationally feasible and asymptotically valid in the sense that the learned model satisfies the fairness constraint asymptotically and achieves a fast convergence rate. Numerical experiments confirm that the SLIDE works well for various benchmark datasets.
INN: A Method Identifying Clean-annotated Samples via Consistency Effect in Deep Neural Networks
Jun 29, 2021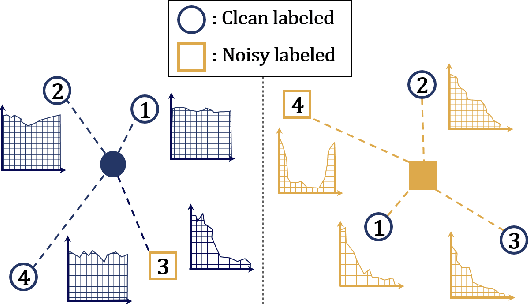
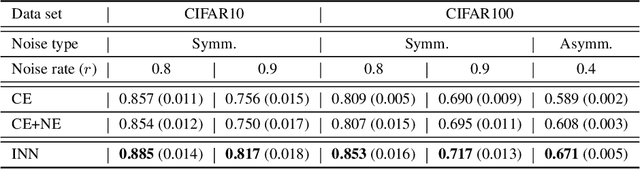
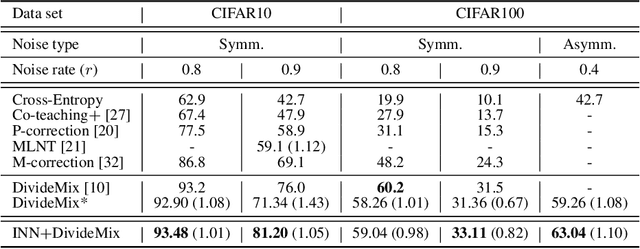
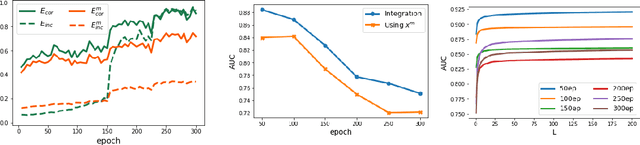
In many classification problems, collecting massive clean-annotated data is not easy, and thus a lot of researches have been done to handle data with noisy labels. Most recent state-of-art solutions for noisy label problems are built on the small-loss strategy which exploits the memorization effect. While it is a powerful tool, the memorization effect has several drawbacks. The performances are sensitive to the choice of a training epoch required for utilizing the memorization effect. In addition, when the labels are heavily contaminated or imbalanced, the memorization effect may not occur in which case the methods based on the small-loss strategy fail to identify clean labeled data. We introduce a new method called INN(Integration with the Nearest Neighborhoods) to refine clean labeled data from training data with noisy labels. The proposed method is based on a new discovery that a prediction pattern at neighbor regions of clean labeled data is consistently different from that of noisy labeled data regardless of training epochs. The INN method requires more computation but is much stable and powerful than the small-loss strategy. By carrying out various experiments, we demonstrate that the INN method resolves the shortcomings in the memorization effect successfully and thus is helpful to construct more accurate deep prediction models with training data with noisy labels.