 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning fair representation with a parametric integral probability metric
Paper and Code
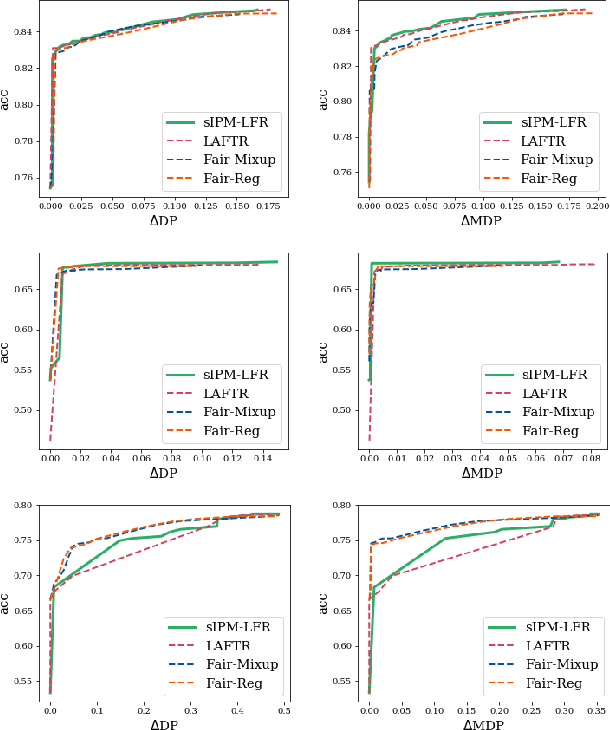
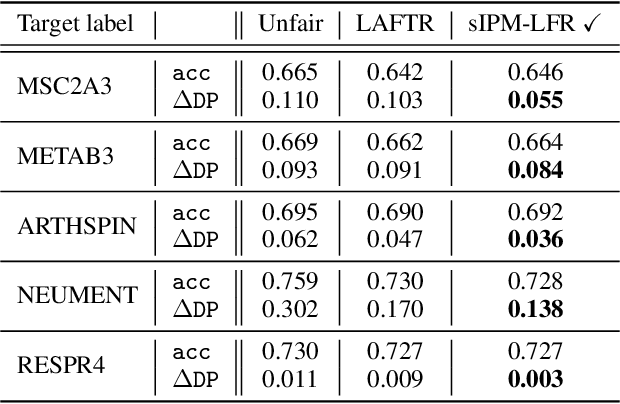
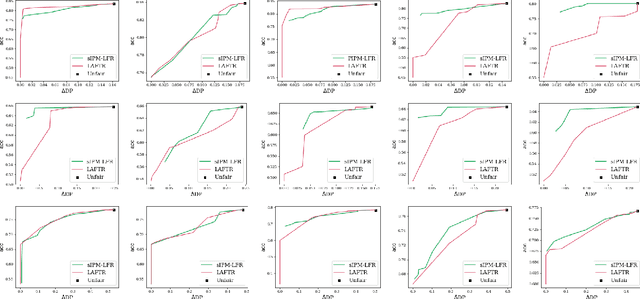
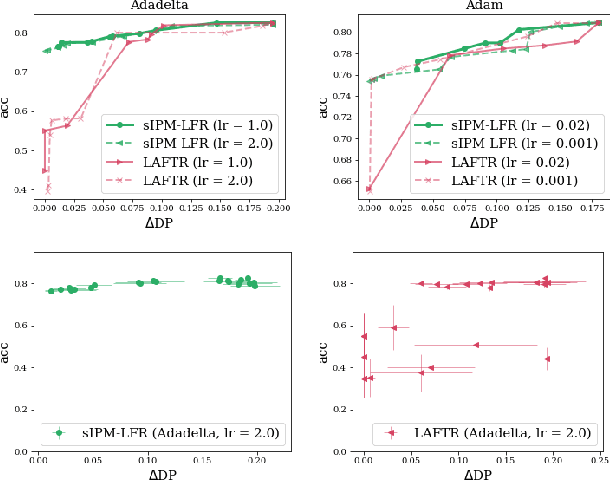
As they have a vital effect on social decision-making, AI algorithms should be not only accurate but also fair. Among various algorithms for fairness AI, learning fair representation (LFR), whose goal is to find a fair representation with respect to sensitive variables such as gender and race, has received much attention. For LFR, the adversarial training scheme is popularly employed as is done in the generative adversarial network type algorithms. The choice of a discriminator, however, is done heuristically without justification. In this paper, we propose a new adversarial training scheme for LFR, where the integral probability metric (IPM) with a specific parametric family of discriminators is used. The most notable result of the proposed LFR algorithm is its theoretical guarantee about the fairness of the final prediction model, which has not been considered yet. That is, we derive theoretical relations between the fairness of representation and the fairness of the prediction model built on the top of the representation (i.e., using the representation as the input). Moreover, by numerical experiments, we show that our proposed LFR algorithm is computationally lighter and more stable, and the final prediction model is competitive or superior to other LFR algorithms using more complex discriminators.