 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLet Triggers Control: Frequency-Aware Dropout for Effective Token Control
Mar 28, 2026Text-to-image models such as Stable Diffusion have achieved unprecedented levels of high-fidelity visual synthesis. As these models advance, personalization of generative models -- commonly facilitated through Low-Rank Adaptation (LoRA) with a dedicated trigger token -- has become a significant area of research. Previous works have naively assumed that fine-tuning with a single trigger token to represent new concepts. However, this often results in poor controllability, where the trigger token alone fails to reliably evoke the intended concept. We attribute this issue to the frequent co-occurrence of the trigger token with the surrounding context during fine-tuning, which entangles their representations and compromises the token's semantic distinctiveness. To disentangle this, we propose Frequency-Aware Dropout (FAD) -- a novel regularization technique that improves prompt controllability without adding new parameters. FAD consists of two key components: co-occurrence analysis and curriculum-inspired scheduling. Qualitative and quantitative analyses across token-based diffusion models (SD~1.5 and SDXL) and natural language--driven backbones (FLUX and Qwen-Image) demonstrate consistent gains in prompt fidelity, stylistic precision, and user-perceived quality. Our method provides a simple yet effective dropout strategy that enhances controllability and personalization in text-to-image generation. Notably, it achieves these improvements without introducing additional parameters or architectural modifications, making it readily applicable to existing models with minimal computational overhead.
VLM2Rec: Resolving Modality Collapse in Vision-Language Model Embedders for Multimodal Sequential Recommendation
Mar 18, 2026Sequential Recommendation (SR) in multimodal settings typically relies on small frozen pretrained encoders, which limits semantic capacity and prevents Collaborative Filtering (CF) signals from being fully integrated into item representations. Inspired by the recent success of Large Language Models (LLMs) as high-capacity embedders, we investigate the use of Vision-Language Models (VLMs) as CF-aware multimodal encoders for SR. However, we find that standard contrastive supervised fine-tuning (SFT), which adapts VLMs for embedding generation and injects CF signals, can amplify its inherent modality collapse. In this state, optimization is dominated by a single modality while the other degrades, ultimately undermining recommendation accuracy. To address this, we propose VLM2Rec, a VLM embedder-based framework for multimodal sequential recommendation designed to ensure balanced modality utilization. Specifically, we introduce Weak-modality Penalized Contrastive Learning to rectify gradient imbalance during optimization and Cross-Modal Relational Topology Regularization to preserve geometric consistency between modalities. Extensive experiments demonstrate that VLM2Rec consistently outperforms state-of-the-art baselines in both accuracy and robustness across diverse scenarios.
Automatic Inter-document Multi-hop Scientific QA Generation
Mar 15, 2026Existing automatic scientific question generation studies mainly focus on single-document factoid QA, overlooking the inter-document reasoning crucial for scientific understanding. We present AIM-SciQA, an automated framework for generating multi-document, multi-hop scientific QA datasets. AIM-SciQA extracts single-hop QAs using large language models (LLMs) with machine reading comprehension and constructs cross-document relations based on embedding-based semantic alignment while selectively leveraging citation information. Applied to 8,211 PubMed Central papers, it produced 411,409 single-hop and 13,672 multi-hop QAs, forming the IM-SciQA dataset. Human and automatic validation confirmed high factual consistency, and experimental results demonstrate that IM-SciQA effectively differentiates reasoning capabilities across retrieval and QA stages, providing a realistic and interpretable benchmark for retrieval-augmented scientific reasoning. We further extend this framework to construct CIM-SciQA, a citation-guided variant achieving comparable performance to the Oracle setting, reinforcing the dataset's validity and generality.
Memorize Early, Then Query: Inlier-Memorization-Guided Active Outlier Detection
Jan 16, 2026Outlier detection (OD) aims to identify abnormal instances, known as outliers or anomalies, by learning typical patterns of normal data, or inliers. Performing OD under an unsupervised regime-without any information about anomalous instances in the training data-is challenging. A recently observed phenomenon, known as the inlier-memorization (IM) effect, where deep generative models (DGMs) tend to memorize inlier patterns during early training, provides a promising signal for distinguishing outliers. However, existing unsupervised approaches that rely solely on the IM effect still struggle when inliers and outliers are not well-separated or when outliers form dense clusters. To address these limitations, we incorporate active learning to selectively acquire informative labels, and propose IMBoost, a novel framework that explicitly reinforces the IM effect to improve outlier detection. Our method consists of two stages: 1) a warm-up phase that induces and promotes the IM effect, and 2) a polarization phase in which actively queried samples are used to maximize the discrepancy between inlier and outlier scores. In particular, we propose a novel query strategy and tailored loss function in the polarization phase to effectively identify informative samples and fully leverage the limited labeling budget. We provide a theoretical analysis showing that the IMBoost consistently decreases inlier risk while increasing outlier risk throughout training, thereby amplifying their separation. Extensive experiments on diverse benchmark datasets demonstrate that IMBoost not only significantly outperforms state-of-the-art active OD methods but also requires substantially less computational cost.
Personalized Federated Recommendation With Knowledge Guidance
Nov 18, 2025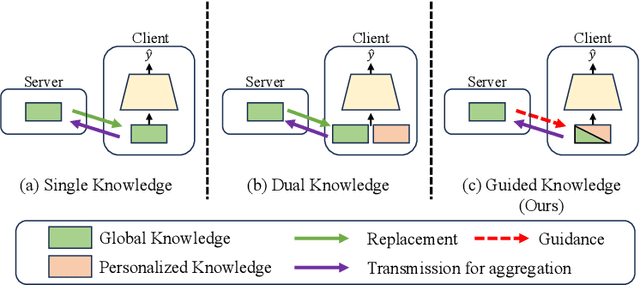
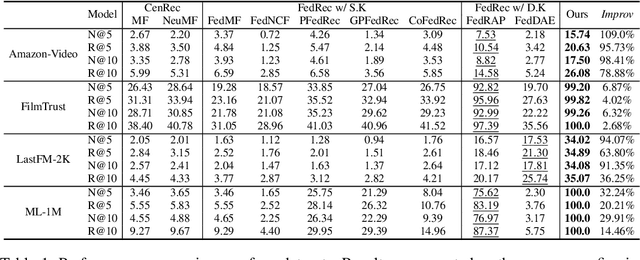
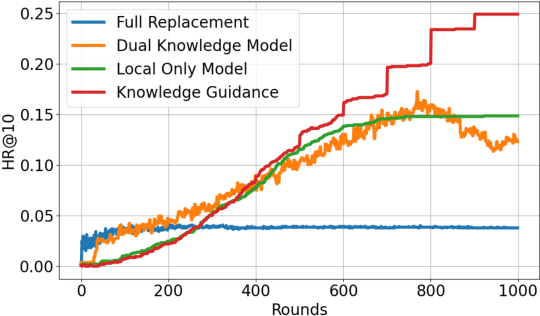
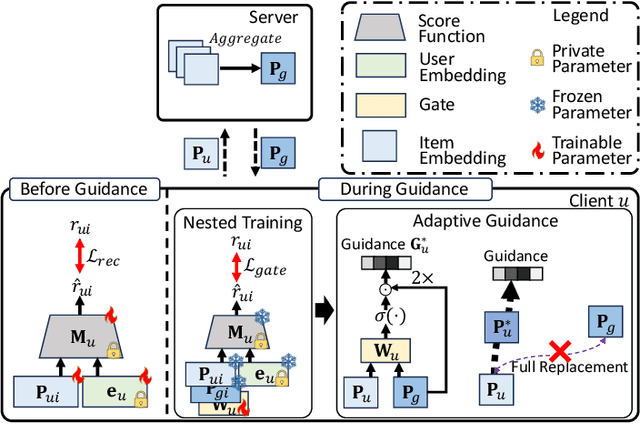
Federated Recommendation (FedRec) has emerged as a key paradigm for building privacy-preserving recommender systems. However, existing FedRec models face a critical dilemma: memory-efficient single-knowledge models suffer from a suboptimal knowledge replacement practice that discards valuable personalization, while high-performance dual-knowledge models are often too memory-intensive for practical on-device deployment. We propose Federated Recommendation with Knowledge Guidance (FedRKG), a model-agnostic framework that resolves this dilemma. The core principle, Knowledge Guidance, avoids full replacement and instead fuses global knowledge into preserved local embeddings, attaining the personalization benefits of dual-knowledge within a single-knowledge memory footprint. Furthermore, we introduce Adaptive Guidance, a fine-grained mechanism that dynamically modulates the intensity of this guidance for each user-item interaction, overcoming the limitations of static fusion methods. Extensive experiments on benchmark datasets demonstrate that FedRKG significantly outperforms state-of-the-art methods, validating the effectiveness of our approach. The code is available at https://github.com/Jaehyung-Lim/fedrkg.
Federated Continual Recommendation
Aug 06, 2025The increasing emphasis on privacy in recommendation systems has led to the adoption of Federated Learning (FL) as a privacy-preserving solution, enabling collaborative training without sharing user data. While Federated Recommendation (FedRec) effectively protects privacy, existing methods struggle with non-stationary data streams, failing to maintain consistent recommendation quality over time. On the other hand, Continual Learning Recommendation (CLRec) methods address evolving user preferences but typically assume centralized data access, making them incompatible with FL constraints. To bridge this gap, we introduce Federated Continual Recommendation (FCRec), a novel task that integrates FedRec and CLRec, requiring models to learn from streaming data while preserving privacy. As a solution, we propose F3CRec, a framework designed to balance knowledge retention and adaptation under the strict constraints of FCRec. F3CRec introduces two key components: Adaptive Replay Memory on the client side, which selectively retains past preferences based on user-specific shifts, and Item-wise Temporal Mean on the server side, which integrates new knowledge while preserving prior information. Extensive experiments demonstrate that F3CRec outperforms existing approaches in maintaining recommendation quality over time in a federated environment.
Personalizing Large Language Models using Retrieval Augmented Generation and Knowledge Graph
May 15, 2025The advent of large language models (LLMs) has allowed numerous applications, including the generation of queried responses, to be leveraged in chatbots and other conversational assistants. Being trained on a plethora of data, LLMs often undergo high levels of over-fitting, resulting in the generation of extra and incorrect data, thus causing hallucinations in output generation. One of the root causes of such problems is the lack of timely, factual, and personalized information fed to the LLM. In this paper, we propose an approach to address these problems by introducing retrieval augmented generation (RAG) using knowledge graphs (KGs) to assist the LLM in personalized response generation tailored to the users. KGs have the advantage of storing continuously updated factual information in a structured way. While our KGs can be used for a variety of frequently updated personal data, such as calendar, contact, and location data, we focus on calendar data in this paper. Our experimental results show that our approach works significantly better in understanding personal information and generating accurate responses compared to the baseline LLMs using personal data as text inputs, with a moderate reduction in response time.
Nonparametric estimation of a factorizable density using diffusion models
Jan 03, 2025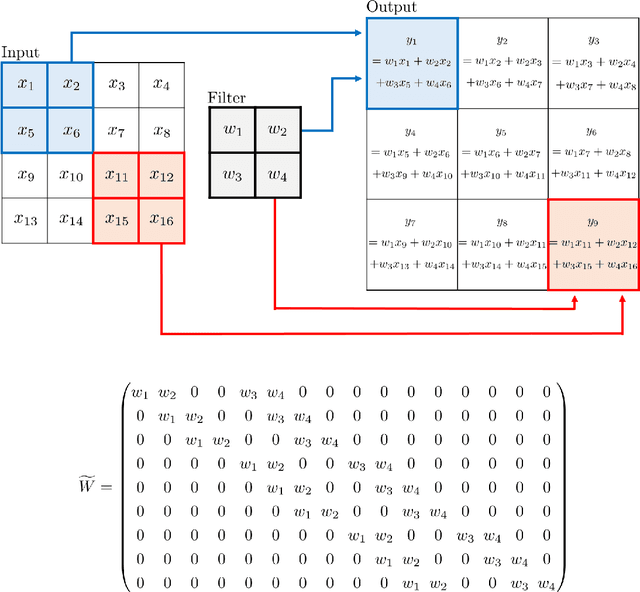
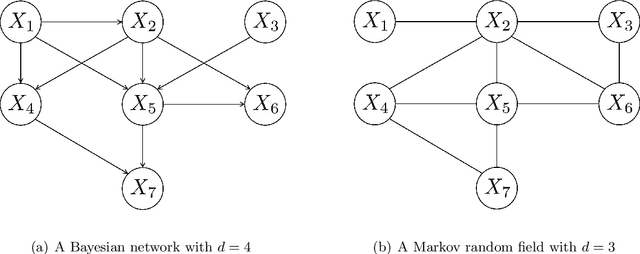
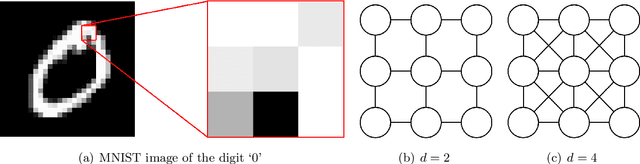
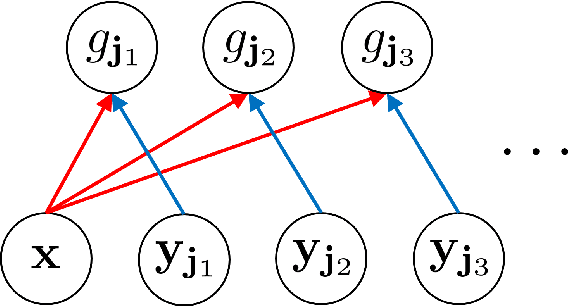
In recent years, diffusion models, and more generally score-based deep generative models, have achieved remarkable success in various applications, including image and audio generation. In this paper, we view diffusion models as an implicit approach to nonparametric density estimation and study them within a statistical framework to analyze their surprising performance. A key challenge in high-dimensional statistical inference is leveraging low-dimensional structures inherent in the data to mitigate the curse of dimensionality. We assume that the underlying density exhibits a low-dimensional structure by factorizing into low-dimensional components, a property common in examples such as Bayesian networks and Markov random fields. Under suitable assumptions, we demonstrate that an implicit density estimator constructed from diffusion models adapts to the factorization structure and achieves the minimax optimal rate with respect to the total variation distance. In constructing the estimator, we design a sparse weight-sharing neural network architecture, where sparsity and weight-sharing are key features of practical architectures such as convolutional neural networks and recurrent neural networks.
Beyond Ontology in Dialogue State Tracking for Goal-Oriented Chatbot
Oct 30, 2024Goal-oriented chatbots are essential for automating user tasks, such as booking flights or making restaurant reservations. A key component of these systems is Dialogue State Tracking (DST), which interprets user intent and maintains the dialogue state. However, existing DST methods often rely on fixed ontologies and manually compiled slot values, limiting their adaptability to open-domain dialogues. We propose a novel approach that leverages instruction tuning and advanced prompt strategies to enhance DST performance, without relying on any predefined ontologies. Our method enables Large Language Model (LLM) to infer dialogue states through carefully designed prompts and includes an anti-hallucination mechanism to ensure accurate tracking in diverse conversation contexts. Additionally, we employ a Variational Graph Auto-Encoder (VGAE) to model and predict subsequent user intent. Our approach achieved state-of-the-art with a JGA of 42.57% outperforming existing ontology-less DST models, and performed well in open-domain real-world conversations. This work presents a significant advancement in creating more adaptive and accurate goal-oriented chatbots.
Illustrious: an Open Advanced Illustration Model
Sep 30, 2024



In this work, we share the insights for achieving state-of-the-art quality in our text-to-image anime image generative model, called Illustrious. To achieve high resolution, dynamic color range images, and high restoration ability, we focus on three critical approaches for model improvement. First, we delve into the significance of the batch size and dropout control, which enables faster learning of controllable token based concept activations. Second, we increase the training resolution of images, affecting the accurate depiction of character anatomy in much higher resolution, extending its generation capability over 20MP with proper methods. Finally, we propose the refined multi-level captions, covering all tags and various natural language captions as a critical factor for model development. Through extensive analysis and experiments, Illustrious demonstrates state-of-the-art performance in terms of animation style, outperforming widely-used models in illustration domains, propelling easier customization and personalization with nature of open source. We plan to publicly release updated Illustrious model series sequentially as well as sustainable plans for improvements.