 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTensor Product Neural Networks for Functional ANOVA Model
Feb 24, 2025Interpretability for machine learning models is becoming more and more important as machine learning models become more complex. The functional ANOVA model, which decomposes a high-dimensional function into a sum of lower dimensional functions so called components, is one of the most popular tools for interpretable AI, and recently, various neural network models have been developed for estimating each component in the functional ANOVA model. However, such neural networks are highly unstable when estimating components since the components themselves are not uniquely defined. That is, there are multiple functional ANOVA decompositions for a given function. In this paper, we propose a novel interpretable model which guarantees a unique functional ANOVA decomposition and thus is able to estimate each component stably. We call our proposed model ANOVA-NODE since it is a modification of Neural Oblivious Decision Ensembles (NODE) for the functional ANOVA model. Theoretically, we prove that ANOVA-NODE can approximate a smooth function well. Additionally, we experimentally show that ANOVA-NODE provides much more stable estimation of each component and thus much more stable interpretation when training data and initial values of the model parameters vary than existing neural network models do.
META-ANOVA: Screening interactions for interpretable machine learning
Aug 02, 2024



There are two things to be considered when we evaluate predictive models. One is prediction accuracy,and the other is interpretability. Over the recent decades, many prediction models of high performance, such as ensemble-based models and deep neural networks, have been developed. However, these models are often too complex, making it difficult to intuitively interpret their predictions. This complexity in interpretation limits their use in many real-world fields that require accountability, such as medicine, finance, and college admissions. In this study, we develop a novel method called Meta-ANOVA to provide an interpretable model for any given prediction model. The basic idea of Meta-ANOVA is to transform a given black-box prediction model to the functional ANOVA model. A novel technical contribution of Meta-ANOVA is a procedure of screening out unnecessary interaction before transforming a given black-box model to the functional ANOVA model. This screening procedure allows the inclusion of higher order interactions in the transformed functional ANOVA model without computational difficulties. We prove that the screening procedure is asymptotically consistent. Through various experiments with synthetic and real-world datasets, we empirically demonstrate the superiority of Meta-ANOVA
INN: A Method Identifying Clean-annotated Samples via Consistency Effect in Deep Neural Networks
Jun 29, 2021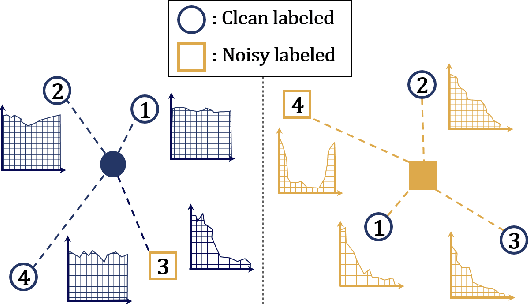
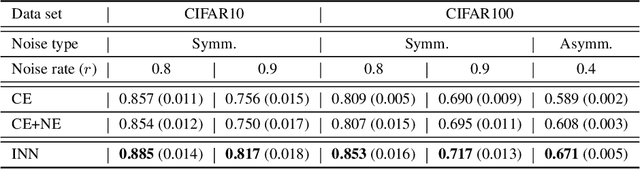
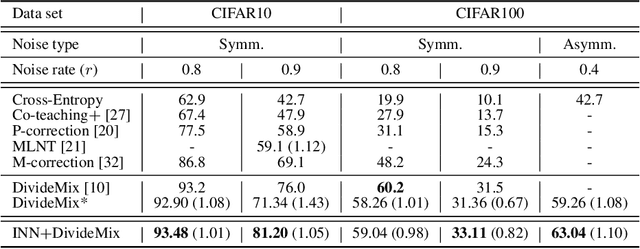
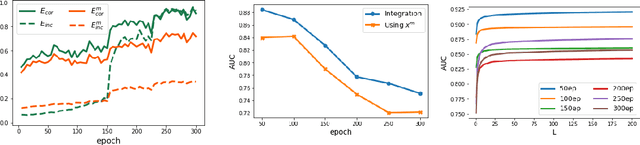
In many classification problems, collecting massive clean-annotated data is not easy, and thus a lot of researches have been done to handle data with noisy labels. Most recent state-of-art solutions for noisy label problems are built on the small-loss strategy which exploits the memorization effect. While it is a powerful tool, the memorization effect has several drawbacks. The performances are sensitive to the choice of a training epoch required for utilizing the memorization effect. In addition, when the labels are heavily contaminated or imbalanced, the memorization effect may not occur in which case the methods based on the small-loss strategy fail to identify clean labeled data. We introduce a new method called INN(Integration with the Nearest Neighborhoods) to refine clean labeled data from training data with noisy labels. The proposed method is based on a new discovery that a prediction pattern at neighbor regions of clean labeled data is consistently different from that of noisy labeled data regardless of training epochs. The INN method requires more computation but is much stable and powerful than the small-loss strategy. By carrying out various experiments, we demonstrate that the INN method resolves the shortcomings in the memorization effect successfully and thus is helpful to construct more accurate deep prediction models with training data with noisy labels.
Understanding and Improving Virtual Adversarial Training
Sep 15, 2019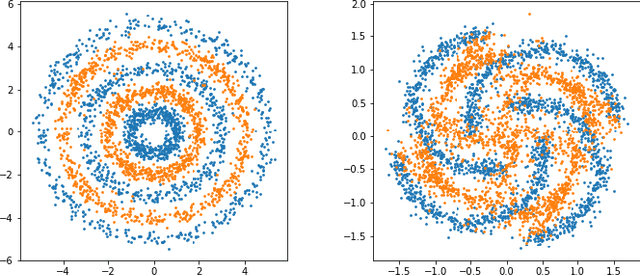
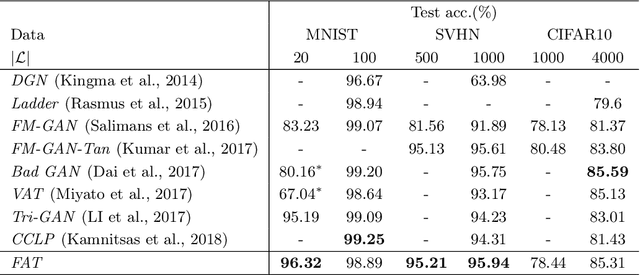
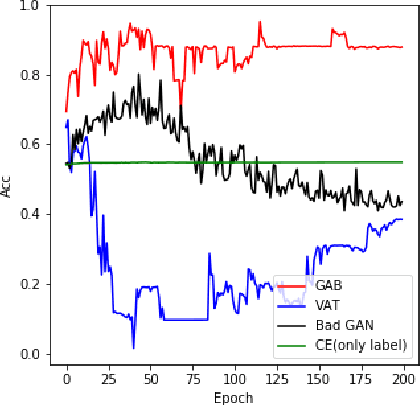

In semi-supervised learning, virtual adversarial training (VAT) approach is one of the most attractive method due to its intuitional simplicity and powerful performances. VAT finds a classifier which is robust to data perturbation toward the adversarial direction. In this study, we provide a fundamental explanation why VAT works well in semi-supervised learning case and propose new techniques which are simple but powerful to improve the VAT method. Especially we employ the idea of Bad GAN approach, which utilizes bad samples distributed on complement of the support of the input data, without any additional deep generative architectures. We generate bad samples of high-quality by use of the adversarial training used in VAT and also give theoretical explanations why the adversarial training is good at both generating bad samples. An advantage of our proposed method is to achieve the competitive performances compared with other recent studies with much fewer computations. We demonstrate advantages our method by various experiments with well known benchmark image datasets.