 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeINN: A Method Identifying Clean-annotated Samples via Consistency Effect in Deep Neural Networks
Paper and Code
Jun 29, 2021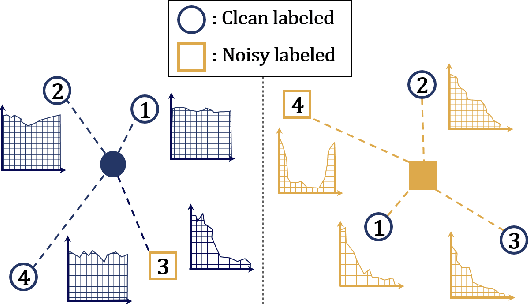
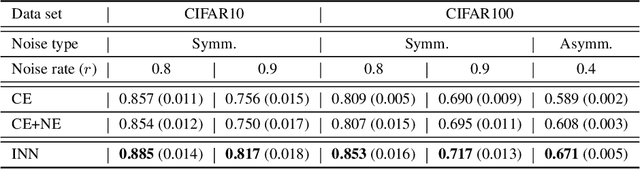
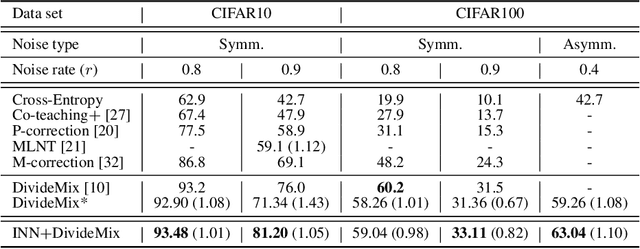
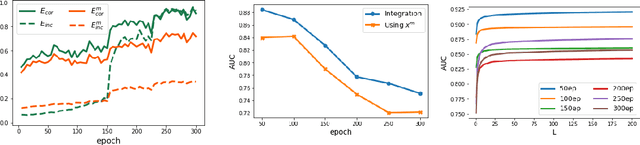
In many classification problems, collecting massive clean-annotated data is not easy, and thus a lot of researches have been done to handle data with noisy labels. Most recent state-of-art solutions for noisy label problems are built on the small-loss strategy which exploits the memorization effect. While it is a powerful tool, the memorization effect has several drawbacks. The performances are sensitive to the choice of a training epoch required for utilizing the memorization effect. In addition, when the labels are heavily contaminated or imbalanced, the memorization effect may not occur in which case the methods based on the small-loss strategy fail to identify clean labeled data. We introduce a new method called INN(Integration with the Nearest Neighborhoods) to refine clean labeled data from training data with noisy labels. The proposed method is based on a new discovery that a prediction pattern at neighbor regions of clean labeled data is consistently different from that of noisy labeled data regardless of training epochs. The INN method requires more computation but is much stable and powerful than the small-loss strategy. By carrying out various experiments, we demonstrate that the INN method resolves the shortcomings in the memorization effect successfully and thus is helpful to construct more accurate deep prediction models with training data with noisy labels.