 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgesudo rm -rf agentic_security
Mar 26, 2025



Large Language Models (LLMs) are increasingly deployed as computer-use agents, autonomously performing tasks within real desktop or web environments. While this evolution greatly expands practical use cases for humans, it also creates serious security exposures. We present SUDO (Screen-based Universal Detox2Tox Offense), a novel attack framework that systematically bypasses refusal trained safeguards in commercial computer-use agents, such as Claude Computer Use. The core mechanism, Detox2Tox, transforms harmful requests (that agents initially reject) into seemingly benign requests via detoxification, secures detailed instructions from advanced vision language models (VLMs), and then reintroduces malicious content via toxification just before execution. Unlike conventional jailbreaks, SUDO iteratively refines its attacks based on a built-in refusal feedback, making it increasingly effective against robust policy filters. In extensive tests spanning 50 real-world tasks and multiple state-of-the-art VLMs, SUDO achieves a stark attack success rate of 24% (with no refinement), and up to 41% (by its iterative refinement) in Claude Computer Use. By revealing these vulnerabilities and demonstrating the ease with which they can be exploited in real-world computing environments, this paper highlights an immediate need for robust, context-aware safeguards. WARNING: This paper includes harmful or offensive model outputs.
Color Information-Based Automated Mask Generation for Detecting Underwater Atypical Glare Areas
Feb 23, 2025Underwater diving assistance and safety support robots acquire real-time diver information through onboard underwater cameras. This study introduces a breath bubble detection algorithm that utilizes unsupervised K-means clustering, thereby addressing the high accuracy demands of deep learning models as well as the challenges associated with constructing supervised datasets. The proposed method fuses color data and relative spatial coordinates from underwater images, employs CLAHE to mitigate noise, and subsequently performs pixel clustering to isolate reflective regions. Experimental results demonstrate that the algorithm can effectively detect regions corresponding to breath bubbles in underwater images, and that the combined use of RGB, LAB, and HSV color spaces significantly enhances detection accuracy. Overall, this research establishes a foundation for monitoring diver conditions and identifying potential equipment malfunctions in underwater environments.
Beyond Ontology in Dialogue State Tracking for Goal-Oriented Chatbot
Oct 30, 2024Goal-oriented chatbots are essential for automating user tasks, such as booking flights or making restaurant reservations. A key component of these systems is Dialogue State Tracking (DST), which interprets user intent and maintains the dialogue state. However, existing DST methods often rely on fixed ontologies and manually compiled slot values, limiting their adaptability to open-domain dialogues. We propose a novel approach that leverages instruction tuning and advanced prompt strategies to enhance DST performance, without relying on any predefined ontologies. Our method enables Large Language Model (LLM) to infer dialogue states through carefully designed prompts and includes an anti-hallucination mechanism to ensure accurate tracking in diverse conversation contexts. Additionally, we employ a Variational Graph Auto-Encoder (VGAE) to model and predict subsequent user intent. Our approach achieved state-of-the-art with a JGA of 42.57% outperforming existing ontology-less DST models, and performed well in open-domain real-world conversations. This work presents a significant advancement in creating more adaptive and accurate goal-oriented chatbots.
Deep Learning from Shallow Dives: Sonar Image Generation and Training for Underwater Object Detection
Oct 18, 2018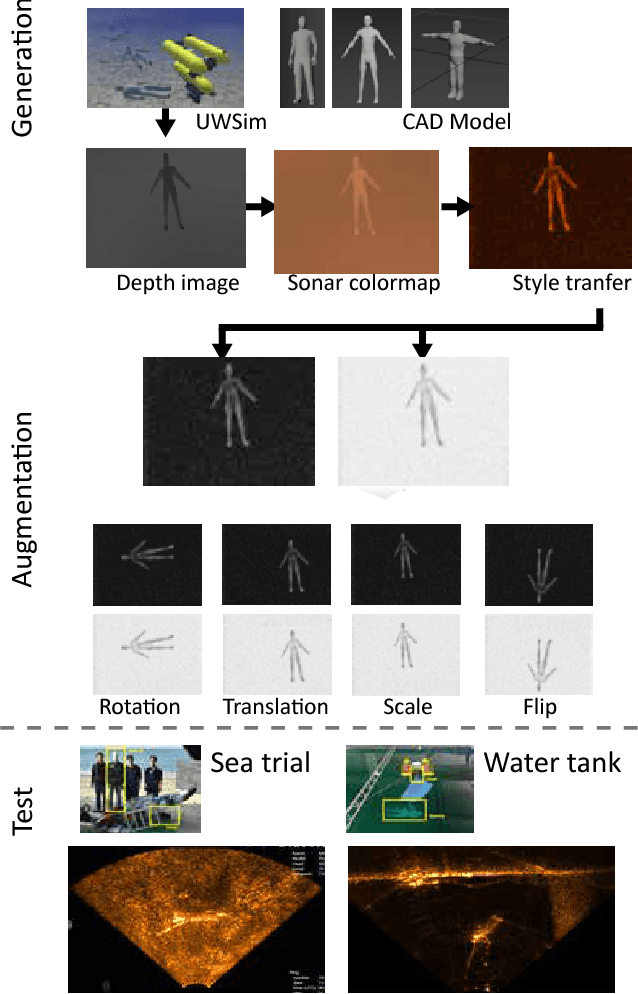



Among underwater perceptual sensors, imaging sonar has been highlighted for its perceptual robustness underwater. The major challenge of imaging sonar, however, arises from the difficulty in defining visual features despite limited resolution and high noise levels. Recent developments in deep learning provide a powerful solution for computer-vision researches using optical images. Unfortunately, deep learning-based approaches are not well established for imaging sonars, mainly due to the scant data in the training phase. Unlike the abundant publically available terrestrial images, obtaining underwater images is often costly, and securing enough underwater images for training is not straightforward. To tackle this issue, this paper presents a solution to this field's lack of data by introducing a novel end-to-end image-synthesizing method in the training image preparation phase. The proposed method present image synthesizing scheme to the images captured by an underwater simulator. Our synthetic images are based on the sonar imaging models and noisy characteristics to represent the real data obtained from the sea. We validate the proposed scheme by training using a simulator and by testing the simulated images with real underwater sonar images obtained from a water tank and the sea.