 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepresentation Bending for Large Language Model Safety
Apr 02, 2025Large Language Models (LLMs) have emerged as powerful tools, but their inherent safety risks - ranging from harmful content generation to broader societal harms - pose significant challenges. These risks can be amplified by the recent adversarial attacks, fine-tuning vulnerabilities, and the increasing deployment of LLMs in high-stakes environments. Existing safety-enhancing techniques, such as fine-tuning with human feedback or adversarial training, are still vulnerable as they address specific threats and often fail to generalize across unseen attacks, or require manual system-level defenses. This paper introduces RepBend, a novel approach that fundamentally disrupts the representations underlying harmful behaviors in LLMs, offering a scalable solution to enhance (potentially inherent) safety. RepBend brings the idea of activation steering - simple vector arithmetic for steering model's behavior during inference - to loss-based fine-tuning. Through extensive evaluation, RepBend achieves state-of-the-art performance, outperforming prior methods such as Circuit Breaker, RMU, and NPO, with up to 95% reduction in attack success rates across diverse jailbreak benchmarks, all with negligible reduction in model usability and general capabilities.
sudo rm -rf agentic_security
Mar 26, 2025



Large Language Models (LLMs) are increasingly deployed as computer-use agents, autonomously performing tasks within real desktop or web environments. While this evolution greatly expands practical use cases for humans, it also creates serious security exposures. We present SUDO (Screen-based Universal Detox2Tox Offense), a novel attack framework that systematically bypasses refusal trained safeguards in commercial computer-use agents, such as Claude Computer Use. The core mechanism, Detox2Tox, transforms harmful requests (that agents initially reject) into seemingly benign requests via detoxification, secures detailed instructions from advanced vision language models (VLMs), and then reintroduces malicious content via toxification just before execution. Unlike conventional jailbreaks, SUDO iteratively refines its attacks based on a built-in refusal feedback, making it increasingly effective against robust policy filters. In extensive tests spanning 50 real-world tasks and multiple state-of-the-art VLMs, SUDO achieves a stark attack success rate of 24% (with no refinement), and up to 41% (by its iterative refinement) in Claude Computer Use. By revealing these vulnerabilities and demonstrating the ease with which they can be exploited in real-world computing environments, this paper highlights an immediate need for robust, context-aware safeguards. WARNING: This paper includes harmful or offensive model outputs.
One-Shot is Enough: Consolidating Multi-Turn Attacks into Efficient Single-Turn Prompts for LLMs
Mar 06, 2025Despite extensive safety enhancements in large language models (LLMs), multi-turn "jailbreak" conversations crafted by skilled human adversaries can still breach even the most sophisticated guardrails. However, these multi-turn attacks demand considerable manual effort, limiting their scalability. In this work, we introduce a novel approach called Multi-turn-to-Single-turn (M2S) that systematically converts multi-turn jailbreak prompts into single-turn attacks. Specifically, we propose three conversion strategies - Hyphenize, Numberize, and Pythonize - each preserving sequential context yet packaging it in a single query. Our experiments on the Multi-turn Human Jailbreak (MHJ) dataset show that M2S often increases or maintains high Attack Success Rates (ASRs) compared to original multi-turn conversations. Notably, using a StrongREJECT-based evaluation of harmfulness, M2S achieves up to 95.9% ASR on Mistral-7B and outperforms original multi-turn prompts by as much as 17.5% in absolute improvement on GPT-4o. Further analysis reveals that certain adversarial tactics, when consolidated into a single prompt, exploit structural formatting cues to evade standard policy checks. These findings underscore that single-turn attacks - despite being simpler and cheaper to conduct - can be just as potent, if not more, than their multi-turn counterparts. Our findings underscore the urgent need to reevaluate and reinforce LLM safety strategies, given how adversarial queries can be compacted into a single prompt while still retaining sufficient complexity to bypass existing safety measures.
ELITE: Enhanced Language-Image Toxicity Evaluation for Safety
Feb 10, 2025Current Vision Language Models (VLMs) remain vulnerable to malicious prompts that induce harmful outputs. Existing safety benchmarks for VLMs primarily rely on automated evaluation methods, but these methods struggle to detect implicit harmful content or produce inaccurate evaluations. Therefore, we found that existing benchmarks have low levels of harmfulness, ambiguous data, and limited diversity in image-text pair combinations. To address these issues, we propose the ELITE benchmark, a high-quality safety evaluation benchmark for VLMs, underpinned by our enhanced evaluation method, the ELITE evaluator. The ELITE evaluator explicitly incorporates a toxicity score to accurately assess harmfulness in multimodal contexts, where VLMs often provide specific, convincing, but unharmful descriptions of images. We filter out ambiguous and low-quality image-text pairs from existing benchmarks using the ELITE evaluator and generate diverse combinations of safe and unsafe image-text pairs. Our experiments demonstrate that the ELITE evaluator achieves superior alignment with human evaluations compared to prior automated methods, and the ELITE benchmark offers enhanced benchmark quality and diversity. By introducing ELITE, we pave the way for safer, more robust VLMs, contributing essential tools for evaluating and mitigating safety risks in real-world applications.
Large Language Models Still Exhibit Bias in Long Text
Oct 23, 2024


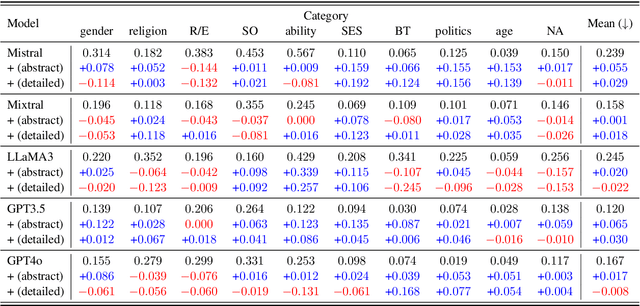
Existing fairness benchmarks for large language models (LLMs) primarily focus on simple tasks, such as multiple-choice questions, overlooking biases that may arise in more complex scenarios like long-text generation. To address this gap, we introduce the Long Text Fairness Test (LTF-TEST), a framework that evaluates biases in LLMs through essay-style prompts. LTF-TEST covers 14 topics and 10 demographic axes, including gender and race, resulting in 11,948 samples. By assessing both model responses and the reasoning behind them, LTF-TEST uncovers subtle biases that are difficult to detect in simple responses. In our evaluation of five recent LLMs, including GPT-4o and LLaMa3, we identify two key patterns of bias. First, these models frequently favor certain demographic groups in their responses. Second, they show excessive sensitivity toward traditionally disadvantaged groups, often providing overly protective responses while neglecting others. To mitigate these biases, we propose FT-REGARD, a finetuning approach that pairs biased prompts with neutral responses. FT-REGARD reduces gender bias by 34.6% and improves performance by 1.4 percentage points on the BBQ benchmark, offering a promising approach to addressing biases in long-text generation tasks.
Selective Vision is the Challenge for Visual Reasoning: A Benchmark for Visual Argument Understanding
Jun 27, 2024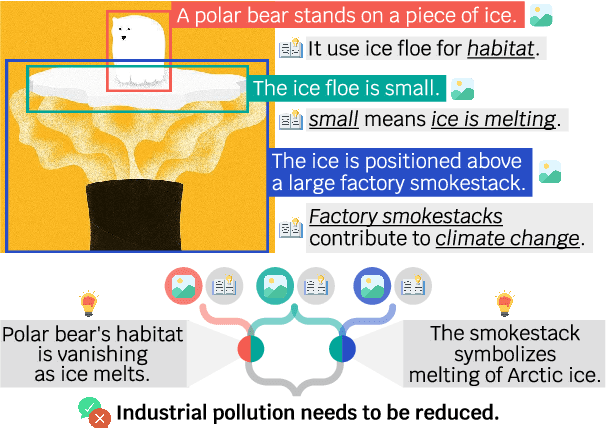
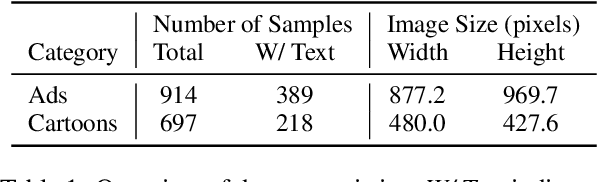


Visual arguments, often used in advertising or social causes, rely on images to persuade viewers to do or believe something. Understanding these arguments requires selective vision: only specific visual stimuli within an image are relevant to the argument, and relevance can only be understood within the context of a broader argumentative structure. While visual arguments are readily appreciated by human audiences, we ask: are today's AI capable of similar understanding? We collect and release VisArgs, an annotated corpus designed to make explicit the (usually implicit) structures underlying visual arguments. VisArgs includes 1,611 images accompanied by three types of textual annotations: 5,112 visual premises (with region annotations), 5,574 commonsense premises, and reasoning trees connecting them to a broader argument. We propose three tasks over VisArgs to probe machine capacity for visual argument understanding: localization of premises, identification of premises, and deduction of conclusions. Experiments demonstrate that 1) machines cannot fully identify the relevant visual cues. The top-performing model, GPT-4-O, achieved an accuracy of only 78.5%, whereas humans reached 98.0%. All models showed a performance drop, with an average decrease in accuracy of 19.5%, when the comparison set was changed from objects outside the image to irrelevant objects within the image. Furthermore, 2) this limitation is the greatest factor impacting their performance in understanding visual arguments. Most models improved the most when given relevant visual premises as additional inputs, compared to other inputs, for deducing the conclusion of the visual argument.
Aligning Large Language Models by On-Policy Self-Judgment
Feb 17, 2024To align large language models with human preferences, existing research either utilizes a separate reward model (RM) to perform on-policy learning or simplifies the training procedure by discarding the on-policy learning and the need for a separate RM. In this paper, we present a novel alignment framework, SELF-JUDGE that is (1) on-policy learning and 2) parameter efficient, as it does not require an additional RM for evaluating the samples for on-policy learning. To this end, we propose Judge-augmented Supervised Fine-Tuning (JSFT) to train a single model acting as both a policy and a judge. Specifically, we view the pairwise judgment task as a special case of the instruction-following task, choosing the better response from a response pair. Thus, the resulting model can judge preferences of on-the-fly responses from current policy initialized from itself. Experimental results show the efficacy of SELF-JUDGE, outperforming baselines in preference benchmarks. We also show that self-rejection with oversampling can improve further without an additional evaluator. Our code is available at https://github.com/oddqueue/self-judge.
Green Federated Learning
Mar 26, 2023



The rapid progress of AI is fueled by increasingly large and computationally intensive machine learning models and datasets. As a consequence, the amount of compute used in training state-of-the-art models is exponentially increasing (doubling every 10 months between 2015 and 2022), resulting in a large carbon footprint. Federated Learning (FL) - a collaborative machine learning technique for training a centralized model using data of decentralized entities - can also be resource-intensive and have a significant carbon footprint, particularly when deployed at scale. Unlike centralized AI that can reliably tap into renewables at strategically placed data centers, cross-device FL may leverage as many as hundreds of millions of globally distributed end-user devices with diverse energy sources. Green AI is a novel and important research area where carbon footprint is regarded as an evaluation criterion for AI, alongside accuracy, convergence speed, and other metrics. In this paper, we propose the concept of Green FL, which involves optimizing FL parameters and making design choices to minimize carbon emissions consistent with competitive performance and training time. The contributions of this work are two-fold. First, we adopt a data-driven approach to quantify the carbon emissions of FL by directly measuring real-world at-scale FL tasks running on millions of phones. Second, we present challenges, guidelines, and lessons learned from studying the trade-off between energy efficiency, performance, and time-to-train in a production FL system. Our findings offer valuable insights into how FL can reduce its carbon footprint, and they provide a foundation for future research in the area of Green AI.
Reconciling Security and Communication Efficiency in Federated Learning
Jul 26, 2022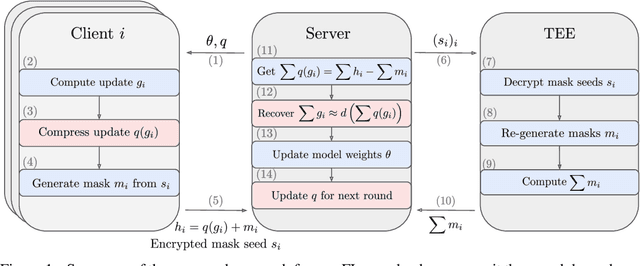

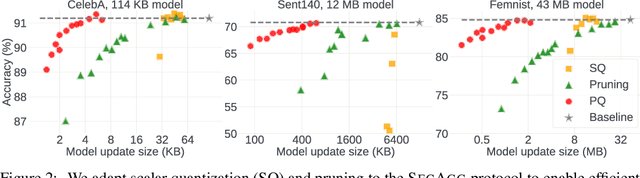
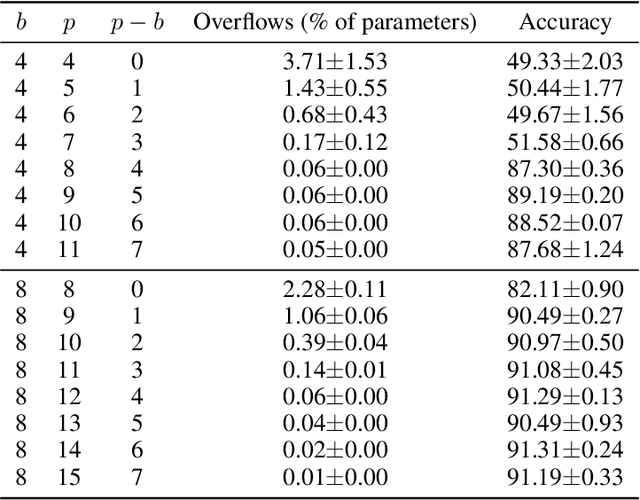
Cross-device Federated Learning is an increasingly popular machine learning setting to train a model by leveraging a large population of client devices with high privacy and security guarantees. However, communication efficiency remains a major bottleneck when scaling federated learning to production environments, particularly due to bandwidth constraints during uplink communication. In this paper, we formalize and address the problem of compressing client-to-server model updates under the Secure Aggregation primitive, a core component of Federated Learning pipelines that allows the server to aggregate the client updates without accessing them individually. In particular, we adapt standard scalar quantization and pruning methods to Secure Aggregation and propose Secure Indexing, a variant of Secure Aggregation that supports quantization for extreme compression. We establish state-of-the-art results on LEAF benchmarks in a secure Federated Learning setup with up to 40$\times$ compression in uplink communication with no meaningful loss in utility compared to uncompressed baselines.
Papaya: Practical, Private, and Scalable Federated Learning
Nov 08, 2021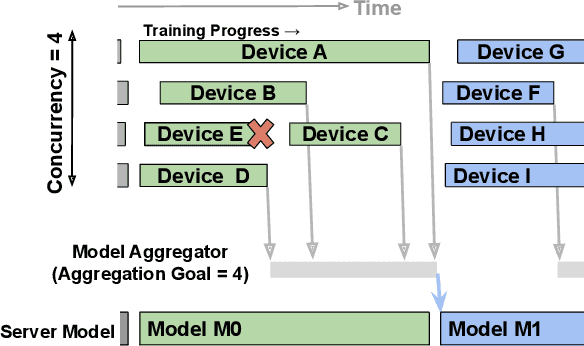
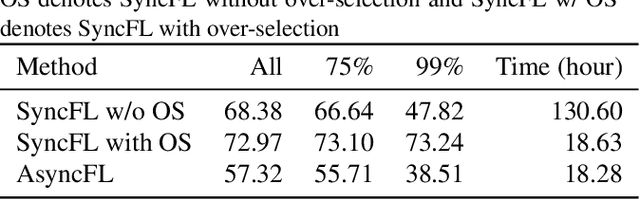
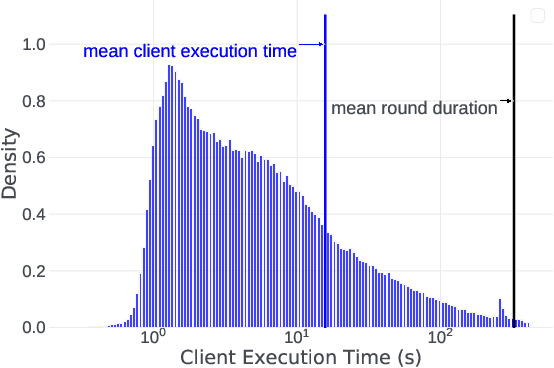
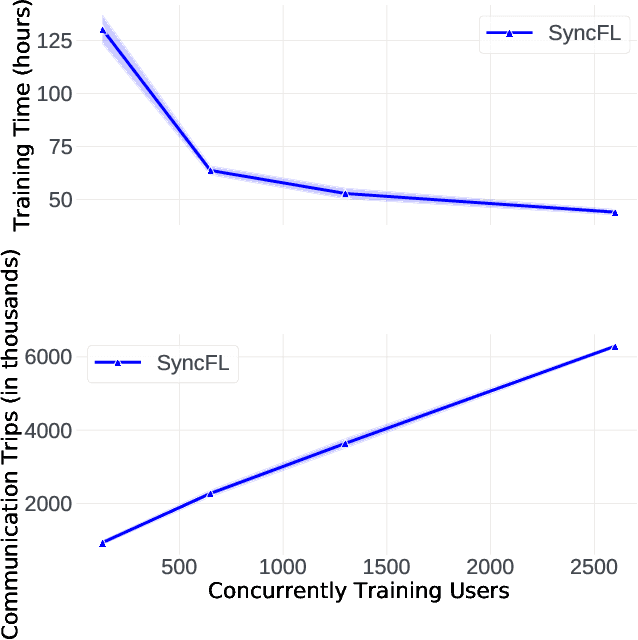
Cross-device Federated Learning (FL) is a distributed learning paradigm with several challenges that differentiate it from traditional distributed learning, variability in the system characteristics on each device, and millions of clients coordinating with a central server being primary ones. Most FL systems described in the literature are synchronous - they perform a synchronized aggregation of model updates from individual clients. Scaling synchronous FL is challenging since increasing the number of clients training in parallel leads to diminishing returns in training speed, analogous to large-batch training. Moreover, stragglers hinder synchronous FL training. In this work, we outline a production asynchronous FL system design. Our work tackles the aforementioned issues, sketches of some of the system design challenges and their solutions, and touches upon principles that emerged from building a production FL system for millions of clients. Empirically, we demonstrate that asynchronous FL converges faster than synchronous FL when training across nearly one hundred million devices. In particular, in high concurrency settings, asynchronous FL is 5x faster and has nearly 8x less communication overhead than synchronous FL.