 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Analytics in Practice: Engineering for Privacy, Scalability and Practicality
Dec 03, 2024



Cross-device Federated Analytics (FA) is a distributed computation paradigm designed to answer analytics queries about and derive insights from data held locally on users' devices. On-device computations combined with other privacy and security measures ensure that only minimal data is transmitted off-device, achieving a high standard of data protection. Despite FA's broad relevance, the applicability of existing FA systems is limited by compromised accuracy; lack of flexibility for data analytics; and an inability to scale effectively. In this paper, we describe our approach to combine privacy, scalability, and practicality to build and deploy a system that overcomes these limitations. Our FA system leverages trusted execution environments (TEEs) and optimizes the use of on-device computing resources to facilitate federated data processing across large fleets of devices, while ensuring robust, defensible, and verifiable privacy safeguards. We focus on federated analytics (statistics and monitoring), in contrast to systems for federated learning (ML workloads), and we flag the key differences.
Confidential Federated Computations
Apr 16, 2024Federated Learning and Analytics (FLA) have seen widespread adoption by technology platforms for processing sensitive on-device data. However, basic FLA systems have privacy limitations: they do not necessarily require anonymization mechanisms like differential privacy (DP), and provide limited protections against a potentially malicious service provider. Adding DP to a basic FLA system currently requires either adding excessive noise to each device's updates, or assuming an honest service provider that correctly implements the mechanism and only uses the privatized outputs. Secure multiparty computation (SMPC) -based oblivious aggregations can limit the service provider's access to individual user updates and improve DP tradeoffs, but the tradeoffs are still suboptimal, and they suffer from scalability challenges and susceptibility to Sybil attacks. This paper introduces a novel system architecture that leverages trusted execution environments (TEEs) and open-sourcing to both ensure confidentiality of server-side computations and provide externally verifiable privacy properties, bolstering the robustness and trustworthiness of private federated computations.
FEL: High Capacity Learning for Recommendation and Ranking via Federated Ensemble Learning
Jun 07, 2022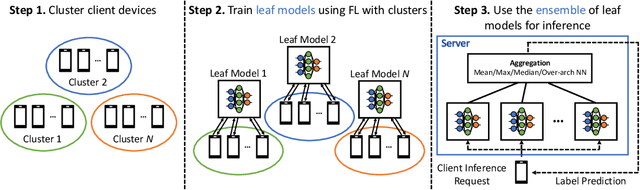
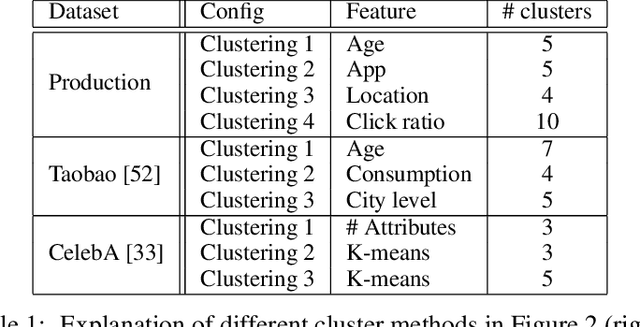
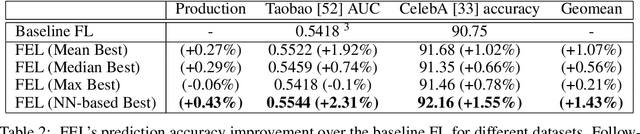
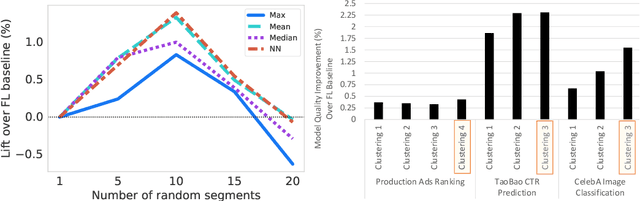
Federated learning (FL) has emerged as an effective approach to address consumer privacy needs. FL has been successfully applied to certain machine learning tasks, such as training smart keyboard models and keyword spotting. Despite FL's initial success, many important deep learning use cases, such as ranking and recommendation tasks, have been limited from on-device learning. One of the key challenges faced by practical FL adoption for DL-based ranking and recommendation is the prohibitive resource requirements that cannot be satisfied by modern mobile systems. We propose Federated Ensemble Learning (FEL) as a solution to tackle the large memory requirement of deep learning ranking and recommendation tasks. FEL enables large-scale ranking and recommendation model training on-device by simultaneously training multiple model versions on disjoint clusters of client devices. FEL integrates the trained sub-models via an over-arch layer into an ensemble model that is hosted on the server. Our experiments demonstrate that FEL leads to 0.43-2.31% model quality improvement over traditional on-device federated learning - a significant improvement for ranking and recommendation system use cases.
Papaya: Practical, Private, and Scalable Federated Learning
Nov 08, 2021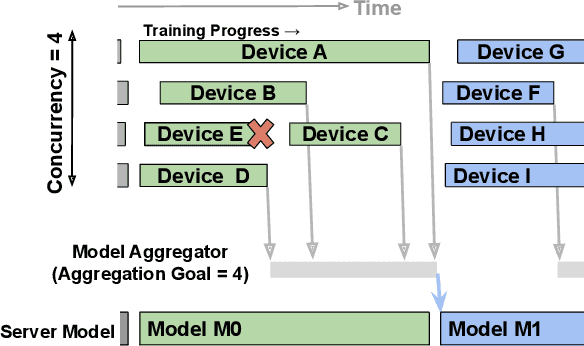
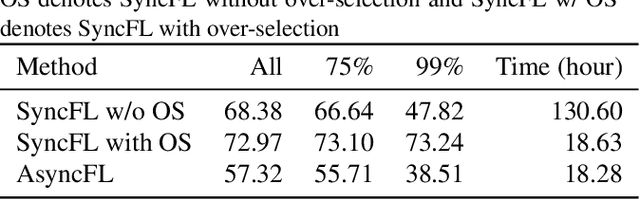
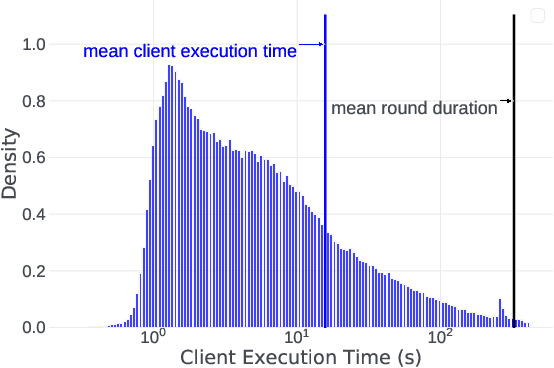
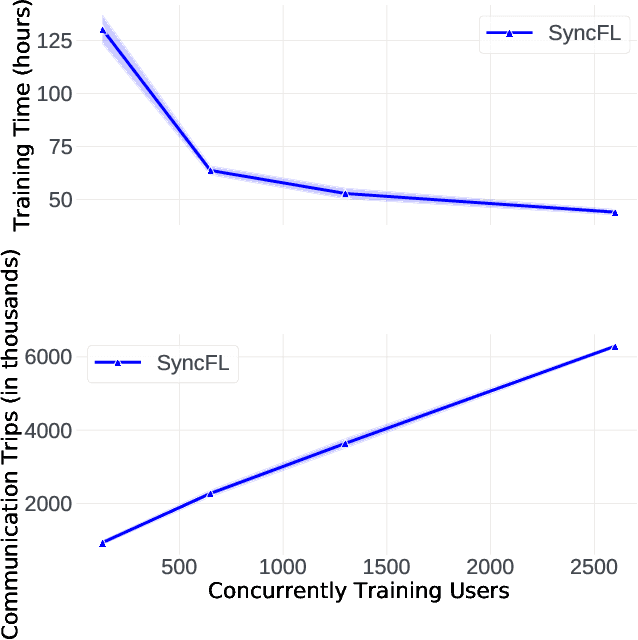
Cross-device Federated Learning (FL) is a distributed learning paradigm with several challenges that differentiate it from traditional distributed learning, variability in the system characteristics on each device, and millions of clients coordinating with a central server being primary ones. Most FL systems described in the literature are synchronous - they perform a synchronized aggregation of model updates from individual clients. Scaling synchronous FL is challenging since increasing the number of clients training in parallel leads to diminishing returns in training speed, analogous to large-batch training. Moreover, stragglers hinder synchronous FL training. In this work, we outline a production asynchronous FL system design. Our work tackles the aforementioned issues, sketches of some of the system design challenges and their solutions, and touches upon principles that emerged from building a production FL system for millions of clients. Empirically, we demonstrate that asynchronous FL converges faster than synchronous FL when training across nearly one hundred million devices. In particular, in high concurrency settings, asynchronous FL is 5x faster and has nearly 8x less communication overhead than synchronous FL.
Federated Learning with Buffered Asynchronous Aggregation
Jun 11, 2021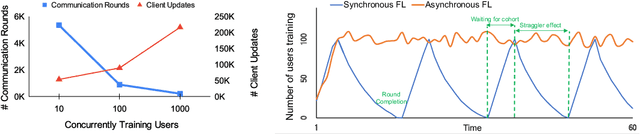

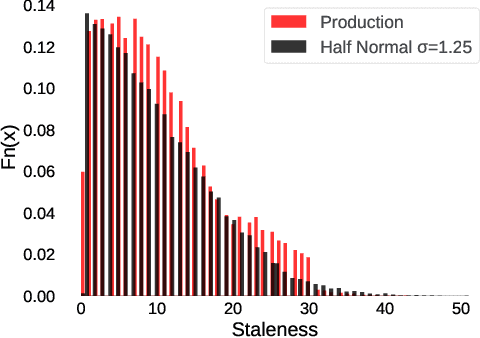

Federated Learning (FL) trains a shared model across distributed devices while keeping the training data on the devices. Most FL schemes are synchronous: they perform a synchronized aggregation of model updates from individual devices. Synchronous training can be slow because of late-arriving devices (stragglers). On the other hand, completely asynchronous training makes FL less private because of incompatibility with secure aggregation. In this work, we propose a model aggregation scheme, FedBuff, that combines the best properties of synchronous and asynchronous FL. Similar to synchronous FL, FedBuff is compatible with secure aggregation. Similar to asynchronous FL, FedBuff is robust to stragglers. In FedBuff, clients trains asynchronously and send updates to the server. The server aggregates client updates in a private buffer until updates have been received, at which point a server model update is immediately performed. We provide theoretical convergence guarantees for FedBuff in a non-convex setting. Empirically, FedBuff converges up to 3.8x faster than previous proposals for synchronous FL (e.g., FedAvgM), and up to 2.5x faster than previous proposals for asynchronous FL (e.g., FedAsync). We show that FedBuff is robust to different staleness distributions and is more scalable than synchronous FL techniques.
Towards Federated Learning at Scale: System Design
Mar 22, 2019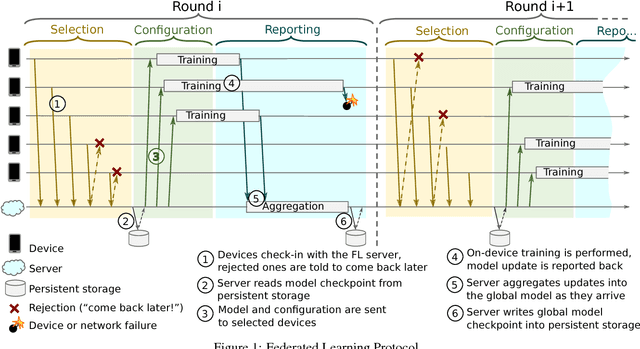
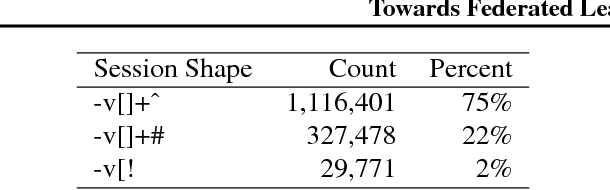
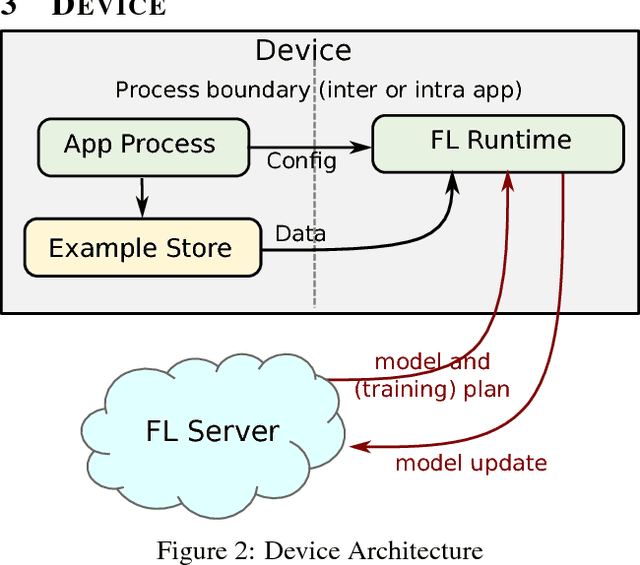
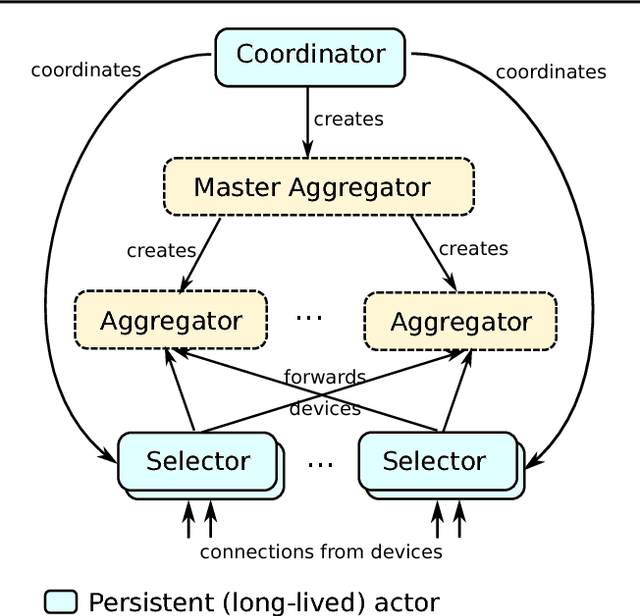
Federated Learning is a distributed machine learning approach which enables model training on a large corpus of decentralized data. We have built a scalable production system for Federated Learning in the domain of mobile devices, based on TensorFlow. In this paper, we describe the resulting high-level design, sketch some of the challenges and their solutions, and touch upon the open problems and future directions.